Как найти Инстаграм человека через ВКонтакте
Вариант 1: Веб-сайт
Произвести поиск учетной записи пользователя в Instagram через веб-сайт социальной сети ВКонтакте можно при условии, что нужный человек заранее осуществил привязку профиля, когда это было возможно, или вручную добавил URL-адрес в описание аккаунта. Мы не будем углубляться в рассмотрение инструментов поиска, так как с данной темой лучше всего ознакомиться отдельно.
Подробнее: Как использовать поиск ВКонтакте
- Откройте официальный сайт рассматриваемой соцсети, через основное меню перейдите в «Друзья» и выберите дочерний раздел «Поиск друзей» в правой колонке. Также можете остаться на предыдущей странице или перейти в другую директорию, чтобы произвести поиск среди друзей или подписчиков, если нужный пользователь был добавлен в соответствующий список.
- Заполните основное текстовое поле «Поиск» в шапке страницы, используя имя и фамилию искомого пользователя, и нажмите клавишу «Enter»
 Для большей эффективности обязательно используйте «Параметры поиска», расположенные с правой стороны.
Для большей эффективности обязательно используйте «Параметры поиска», расположенные с правой стороны. - После перехода к учетной записи ссылка на Instagram должна располагаться напротив одноименного пункта при раскрытии блока «Показать подробную информацию». Если нажать по данной строке, откроется официальный сайт Instagram или приложение, если ПК-версия ВК используется на мобильном устройстве.
В некоторых случаях, что особенно актуально для новых учетных записей, созданных после того, как связывание рассматриваемых социальных сетей стало невозможным, полный URL-адрес профиля может быть указан в подразделе
 Для большей эффективности обязательно используйте «Параметры поиска», расположенные с правой стороны.
Для большей эффективности обязательно используйте «Параметры поиска», расположенные с правой стороны.Если на странице отсутствуют интересующие вас поля, возможно, дело в настройках приватности или том, что пользователь предпочел не указывать информацию о контактах. При возникновении такой ситуации, к сожалению, ничего нельзя сделать, кроме как пробовать другие способы поиска людей средствами самого Instagram или сторонних сайтов.
При возникновении такой ситуации, к сожалению, ничего нельзя сделать, кроме как пробовать другие способы поиска людей средствами самого Instagram или сторонних сайтов.
Вариант 2: Мобильное приложение
Для того чтобы найти друзей или просто интересных пользователей в Instagram через мобильное приложение ВКонтакте, можно также воспользоваться внутренней, хоть и немного отличающейся по оформлению, системой поиска.
- С помощью нижней навигационной панели приложения перейдите на вкладку «Главная» и в правом верхнем углу экрана нажмите по значку с изображением лупы. После этого следует переместиться на вкладку «Люди» и коснуться текстового блока «Поиск людей».
- Заполните графу в соответствии с именем и фамилией нужного пользователя, попутно просматривая результаты. Для исключения некоторых вариантов, если вы знаете что-то конкретное о человеке, обязательно используйте всплывающее окно
- Разобравшись с отсеиванием результатов, найдите человека в списке. Для перехода к персональной анкете достаточно один раз коснуться произвольной области рядом с именем.
- Оказавшись по итогу на странице пользователя, в шапке аккаунта нажмите по блоку с подписью «Подробная информация» и пролистайте содержимое окна до самого низа. Если владелец учетной записи осуществил привязку профиля в Instagram или вручную указал ссылку, это будет отображено в рамках блока «Контакты».
 Для перехода к персональной анкете достаточно один раз коснуться произвольной области рядом с именем.
Для перехода к персональной анкете достаточно один раз коснуться произвольной области рядом с именем.Во втором варианте, к сожалению, могут быть проблемы, если поле использовалось для более чем одного адреса. Кроме этого, ссылка без привязки даже в приложении приведет к открытию веб-сайта в мобильном браузере, а не официального клиента социальной сети.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТКомитет по труду и занятости населения Волгоградской области
Уважаемые работодатели!
Интерактивный портал комитета по труду и занятости населения Волгоградской области (далее — портал) предназначен для предоставления государственных услуг в сфере занятости населения гражданам и работодателям.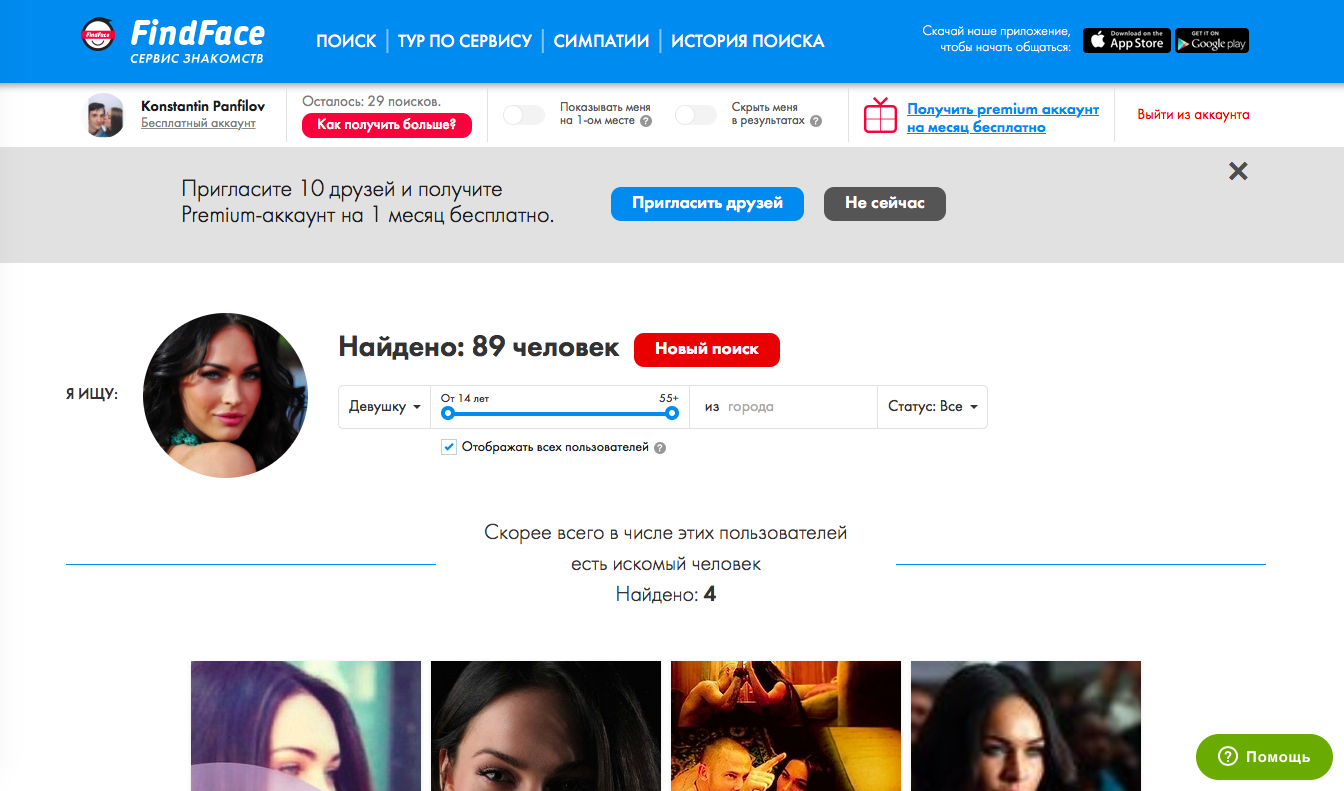
Отдельный блок портала предназначен для работодателей.
Работодатель может получить полный спектр услуг только после регистрации на портале и создания личного кабинета.
Зарегистрироваться на портале можно двумя способами:
с помощью учетной записи портала Госуслуг;
при личном обращении в центр занятости населения.
На портале в разделе «Информация» – «Видеоматериалы» расположены видеоролики, которые помогут работодателю выполнить регистрацию на портале.
После регистрации на портале работодателю будут доступны следующие госуслуги и сервисы в электронном виде (вкладка «Услуги» в личном кабинете):
информирование о положении на рынке труда;
уведомительная регистрация коллективных договоров;
предоставление сведений о вакансиях;
предоставление сведений о высвобождении работников;
предоставление отчетов о кадровом составе;
предоставление отчетов о выполнении условий квотирования.
Технология предоставления работодателями сведений в центр занятости выглядит следующим образом:
В результате этих действий формируется два объекта: электронное обращение работодателя в центр занятости и сам отчет.
В личном кабинете работодателя присутствует еще 6 вкладок:
Во вкладке «Обращения» отображаются обращения работодателя в центр занятости с разными целями (предоставление сведений, обращения за госуслугами и пр.).
В вкладке «Черновики» отображаются черновики заявлений, по которым не была выполнена отправка.
Во вкладке «Реквизиты» работодателю доступна информация об организации, которая была представлена при регистрации на портале.
Во вкладке «Настройки» представитель организации может выполнить операцию изменения пароля и адреса электронной почты.
Во вкладке «Избранные соискатели» отображаются резюме соискателей, которые были добавлены сотрудником организации в «Избранное» в «Банке соискателей».
ПОЛОЖЕНИЕ О ВОЗМЕЩЕНИИ РАСХОДОВ НА ПОИСК И ОЦЕНКУ ОТКРЫТОГО МЕСТОРОЖДЕНИЯ ПОЛЕЗНЫХ ИСКОПАЕМЫХ И СУММЫ УПЛАЧЕННОГО В СООТВЕТСТВИИ С УСЛОВИЯМИ СОВМЕЩЕННОЙ ЛИЦЕНЗИИ РАЗОВОГО ПЛАТЕЖА ЗА ПОЛЬЗОВАНИЕ УЧАСТКОМ НЕДР ЛИЦАМ, КОТОРЫМ В СООТВЕТСТВИИ С ЧАСТЬЮ ПЯТОЙ СТАТЬИ 2.1 ЗАКОНА РОССИЙСКОЙ ФЕДЕРАЦИИ «О НЕДРАХ» ОТКАЗАНО В ПРЕДОСТАВЛЕНИИ ПРАВА ПОЛЬЗОВАНИЯ УЧАСТКОМ НЕДР ДЛЯ РАЗВЕДКИ И ДОБЫЧИ ПОЛЕЗНЫХ ИСКОПАЕМЫХ НА УЧАСТКЕ НЕДР ФЕДЕРАЛЬНОГО ЗНАЧЕНИЯ, И О ВЫПЛАТЕ ИМ ВОЗНАГРАЖДЕНИЯ
Утверждено
Постановлением Правительства
Российской Федерации
от 10 марта 2009 г. N 206
N 206
1. Настоящее Положение устанавливает порядок возмещения расходов на поиск и оценку открытого месторождения полезных ископаемых и суммы уплаченного в соответствии с условиями совмещенной лицензии разового платежа за пользование участком недр (далее — сумма разового платежа) лицам, которым в соответствии с частью пятой статьи 2.1 Закона Российской Федерации «О недрах» отказано в предоставлении права пользования участком недр для разведки и добычи полезных ископаемых на участке недр федерального значения (далее — инвесторы), а также выплаты им вознаграждения.
2. Инвесторам возмещаются документально подтвержденные и осуществленные ими расходы на поиск и оценку открытого месторождения полезных ископаемых (далее — возмещаемые расходы).
3. В состав возмещаемых расходов включаются расходы:
а) на проведение общих и детальных поисков открытого месторождения полезных ископаемых, в том числе поисковых работ при геологической съемке;
б) на проведение работ по поиску и оценке открытого месторождения полезных ископаемых (далее — работы), в том числе тематических и иных исследований, связанных с геологическим изучением участка недр федерального значения и оценкой его перспектив;
в) на осуществление мероприятий по установлению факта открытия месторождения полезных ископаемых и постановке запасов полезных ископаемых на государственный баланс;
г) на компенсацию инвестором иным лицам их расходов, осуществленных на поиск и оценку открытого месторождения полезных ископаемых после выдачи инвестору лицензии на пользование участком недр;
д)на осуществление иных документально подтвержденных работ, проведенных на предоставленном инвестору в пользование участке недр федерального значения;
КонсультантПлюс: примечание.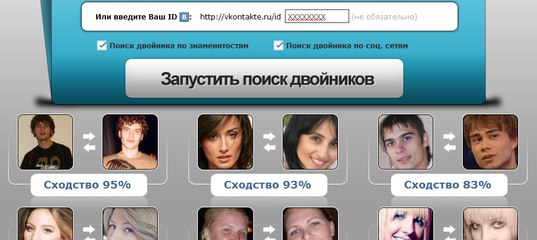
В соответствии с Постановлением Правительства РФ от 08.12.2015 N 1340 к отношениям, регулируемым актами Правительства РФ, в которых используется ставка рефинансирования Банка России, с 1 января 2016 года вместо ставки рефинансирования применяется ключевая ставка Банка России.
е) на выплату процентов, начисленных по долговым обязательствам, связанным с получением и использованием инвестором кредитных и заемных средств для финансирования работ (по кредитам, в том числе товарным и коммерческим кредитам, займам и иным заимствованиям независимо от формы их оформления), предельная величина которых равна ставке рефинансирования Центрального банка Российской Федерации, увеличенной в 1,1 раза, — при оформлении долгового обязательства в рублях и равной 15 процентам — по долговым обязательствам в иностранной валюте.
4. В составе возмещаемых расходов не учитываются расходы, которые:
а) ранее возмещены государством инвестору;
б) отнесены в состав расходов, связанных с извлечением полученных инвестором доходов и учтенных при определении налоговой базы по налогу на прибыль организаций в соответствии с главой 25 Налогового кодекса Российской Федерации, до даты их возмещения;
в) связаны с поиском и оценкой открытого месторождения полезных ископаемых иными лицами до даты выдачи инвестору лицензии на пользование участком недр, при выполнении условий которой инвестор эти расходы осуществил;
г) осуществлены инвестором и связаны с получением и использованием им кредитных и заемных средств для финансирования работ, за исключением процентов, указанных в подпункте «е» пункта 3 настоящего Положения.
5. При отказе в предоставлении права пользования участком недр для разведки и добычи полезных ископаемых на участке недр федерального значения инвестору, осуществлявшему пользование участком недр на условиях совмещенной лицензии, возмещается сумма разового платежа, рассчитанная на дату принятия решения о таком отказе в соответствии с частью пятой статьи 2.1 Закона Российской Федерации «О недрах».
6. Размер вознаграждения, выплачиваемого инвестору, определяется как процент суммы возмещаемых расходов:
а) для участков недр, содержащих месторождения углеводородного сырья, — согласно приложению N 1;
б) для участков недр, содержащих месторождения твердых полезных ископаемых, — согласно приложению N 2.
7. Для получения сумм возмещаемых расходов, разового платежа и вознаграждения инвестор подает в Федеральное агентство по недропользованию заявление, в котором указывает:
а) сведения о сумме возмещаемых расходов, рассчитанной в соответствии с настоящим Положением в рублях на дату осуществления этих расходов;
б) сведения о сумме разового платежа;
в) банковские реквизиты счетов для перечисления ему сумм возмещаемых расходов, разового платежа и вознаграждения.
8. К заявлению прилагаются документы, подтверждающие сведения, указанные в подпунктах «а» и «б» пункта 7 настоящего Положения.
9. Проверка сведений, указанных инвестором в заявлении в соответствии с подпунктами «а» и «б» пункта 7 настоящего Положения, расчет сумм возмещаемых расходов, разового платежа и вознаграждения, выплачиваемых инвестору, и их утверждение осуществляются Федеральным агентством по недропользованию с привлечением независимых аудиторов в течение 90 дней с даты подачи инвестором заявления.
Указанные в заявлении инвестора суммы возмещаемых расходов и разового платежа пересчитываются на дату подачи заявления с использованием индексов-дефляторов, устанавливаемых Министерством экономического развития Российской Федерации.
10. Федеральное агентство по недропользованию информирует Министерство природных ресурсов и экологии Российской Федерации и Министерство экономического развития Российской Федерации об утвержденных суммах возмещаемых расходов, разового платежа и вознаграждения.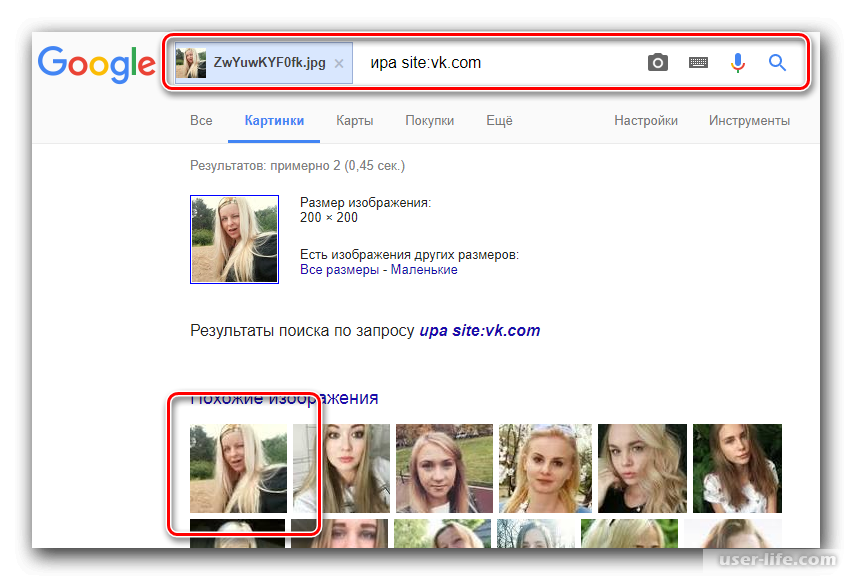
11. Выплата инвестору сумм возмещаемых расходов, разового платежа и вознаграждения осуществляется за счет средств федерального бюджета, предусмотренных на эти цели в очередном финансовом году Федеральному агентству по недропользованию в соответствии с бюджетным законодательством Российской Федерации, путем перечисления этих сумм на счета инвестора, указанные в подпункте «в» пункта 7 настоящего Положения.
Технология распознавания лиц в 4 аэропортах будет внедрена к марту следующего года: Центр
Технологии распознавания лиц (FRT) еще не внедрен ни в одном из аэропортов Индии, ответил госминистр в Министерстве гражданской авиации генерал В.К. Сингх ( retd) на вопрос в Лок Сабха в четверг.Вопрос задали депутаты Ферозе Варун Ганди и Рам Шанкар Катерия.
Сингх сказал, что система FRT еще не введена ни в одном из аэропортов Индии. Тем не менее, Управление аэропортов Индии (AAI) работает над проектом системы биометрической регистрации на основе FRT в рамках первого этапа внедрения Digi Yatra в четырех аэропортах (Варанаси, Пуна, Калькутта и Виджаявада).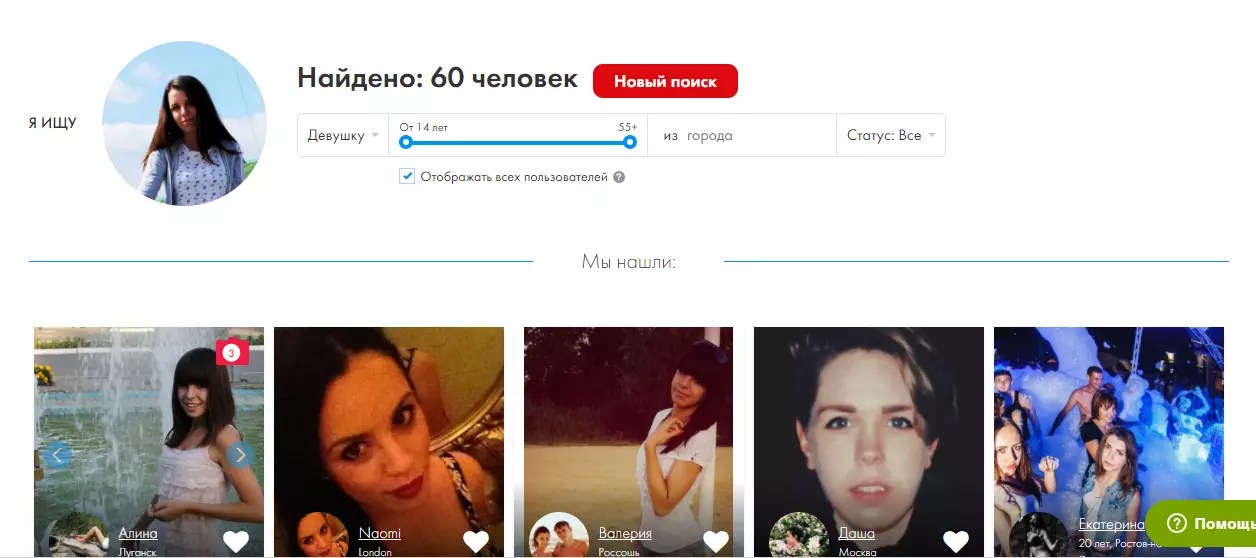
Он добавил, что предлагаемая центральная экосистема Digi Yatra планируется запустить в марте 2022 года. Ее необходимо поэтапно масштабировать для внедрения в различных аэропортах страны.
Когда его спросили о мерах безопасности, принятых правительством для предотвращения утечки данных о пассажирах, он сказал, что в соответствии с политикой Диги-ятры регистрация в Центральной экосистеме Диги-ятры не является обязательной для пассажира. Чтобы воспользоваться услугами Digi Yatra, пассажиры должны были отправлять информацию о поездке (данные Pax, PNR и биометрические данные лица) через приложение в систему биометрической регистрации соответствующего аэропорта вылета.
Кроме того, если для определенного путешествия пассажир не хочет пользоваться услугами Диги-ятры, у пассажира есть возможность не отправлять данные и использовать существующий ручной процесс в аэропортах.
«Центральная экосистема Digi Yatra предусматривает оценку (независимыми группами для оценки уровня безопасности и устойчивости системы для защиты PII) и периодические проверки руководящими/регулирующими органами два раза в год.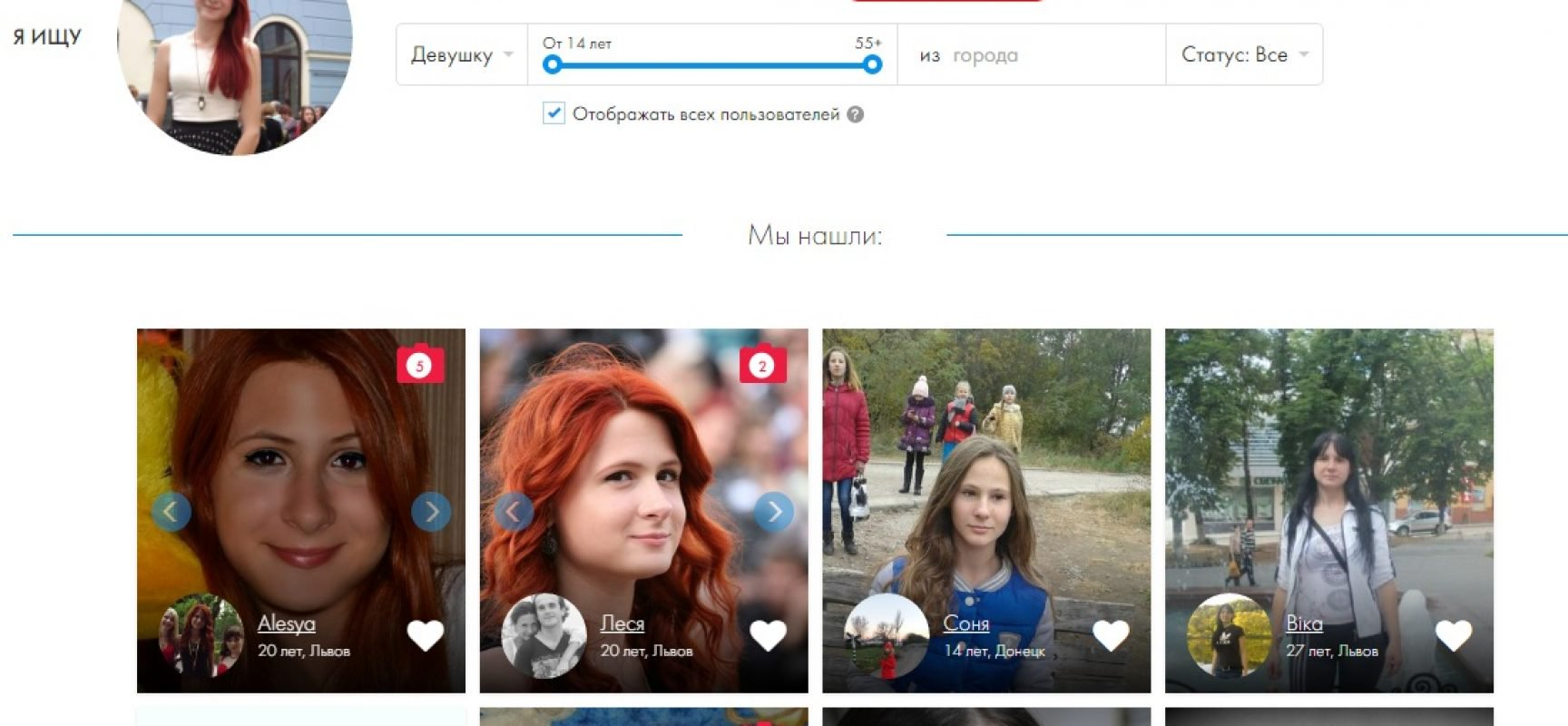 Распознавание лиц соответствует отраслевым стандартам ISO с лучшими показателями Национальный институт стандартов и технологий (NIST) перечислил алгоритмы, соответствующие требованиям конфиденциальности и защиты данных, установленным правительством», — сказал он.
Распознавание лиц соответствует отраслевым стандартам ISO с лучшими показателями Национальный институт стандартов и технологий (NIST) перечислил алгоритмы, соответствующие требованиям конфиденциальности и защиты данных, установленным правительством», — сказал он.
Данные, переданные Пассажиром, должны использоваться для определенной цели и не будут передаваться никаким другим внешним заинтересованным сторонам. Важно отметить, что данные, предоставленные пассажирами, должны храниться во время транзита пассажира в аэропорту и не будут храниться более 24 часов после взлета/вылета рейса, — ответил он.
Служба распознавания лиц FindFace может поставить вашу конфиденциальность под угрозу
Если вы не из России, то наверняка не слышали о сервисе, который анализирует изображение человека и находит его аккаунт в ВК.ком социальная сеть. Называется FindFace. Он был представлен в феврале 2016 года, но в последнее время стал довольно популярным; благодаря впечатляющему фотопроекту, опубликованному петербургским фотографом Егором Цветковым. Недавно мы упоминали об этом проекте в блоге.
Недавно мы упоминали об этом проекте в блоге.
Редакция Kaspersky Daily решила проверить сервис, чтобы узнать, как он работает и какие типы портретов распознает, а какие нет. Мы хотели узнать, можно ли узнать подробную биографию совершенно незнакомого человека с помощью одной случайной фотографии, интернета и некоторых современных технологий.
Как #bigdata превратила нас с вами в товар. Постарайтесь не чувствовать себя #грязным https://t.co/8yIXgsm9IY pic.twitter.com/p7khV4F95M
— Лаборатория Касперского (@kaspersky) 22 апреля 2016 г.
Выводы тревожные: действительно возможно . В ходе исследования мы также сделали несколько интересных открытий; например, один из наших коллег неожиданно обнаружил, что его цифровая личность была украдена.
Итак, что такое FindFace и как он работает?
FindFace — сервис, умеющий искать ВК.com на основе портретной фотографии человека. 30 попыток поиска бесплатны, далее придется заплатить.
30 попыток поиска бесплатны, далее придется заплатить.
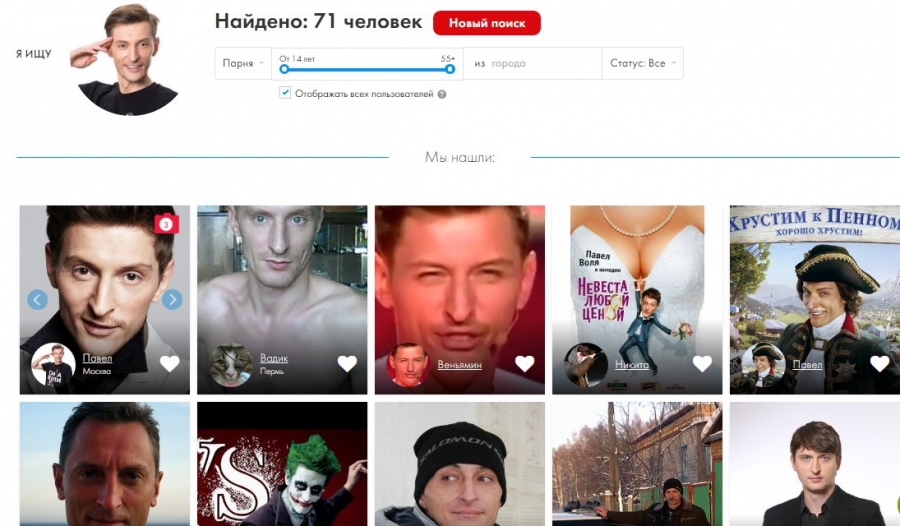
У сервиса есть мобильные приложения для iOS и Android, дополненные веб-версией. Приложения бывают с ограниченным функционалом и рядом недостатков в работе, но у них есть одно ценное преимущество: пользователи могут сделать фото и сразу же использовать его для поиска с помощью FindFace.
Приложение показывает фотографии профилей потенциальных совпадений. Вы можете нажать на каждую фотографию, чтобы просмотреть все общедоступные изображения в учетной записи пользователя.Достаточно взглянуть на работу Егора Цветкова в проекте «Твое лицо — большие данные», чтобы увидеть, как легко найти совершенно незнакомого человека.
Веб-сервис более удобен, так как позволяет сразу перейти к целевой учетной записи VK.com. Для поиска человека с помощью сайта вам придется выполнить несколько дополнительных действий, например, сначала скопировать фотографии на жесткий диск, а затем загрузить их на FindFace.ru.
Если вы загружаете «идеальные» фотографии, сделанные, когда ваша цель позировала, все работает просто отлично. Программа успешно нашла 9 из 10 тестовых «жертв» в офисе.
Программа успешно нашла 9 из 10 тестовых «жертв» в офисе.
Если украдкой фотографировать незнакомцев на улицах или в метро, точность снижается в два, а то и в три раза. А если загружать изображения, сделанные с большого расстояния, сервис часто не может найти на фото человека. Тем не менее, если вы увеличите или обрежете изображение, FindFace снова будет работать.
Насколько легко хакерам украсть ваше лицо? https://t.co/SGtYtE1y63 #digitalidentity pic.twitter.com/Cz85TxEkYt
— Лаборатория Касперского (@kaspersky) 28 октября 2015 г.
При дневном свете нетрудно сфотографировать пешехода на средний смартфон, которого хватило бы на Findface. В метро вам понадобится штатив или хороший фотоаппарат.
Что мы узнали
Если вы не хотите, чтобы вас буквально обнаружил какой-нибудь незнакомец с телефоном, есть несколько вещей, которые вы можете сделать.
1. Сервис ищет фотографии, загруженные в ваш ВК. com профиль , а не весь аккаунт. Это включает в себя ваше текущее изображение профиля и все предыдущие. Социальная сеть хранит эти фотографии в альбоме «Мои фото профиля». Примечательно, что этот альбом нельзя скрыть — он всегда остается общедоступным. Единственное, что вы можете сделать, это удалить старые изображения профиля: чем меньше у вас фотографий в этом альбоме, тем сложнее приложению вас распознать.
com профиль , а не весь аккаунт. Это включает в себя ваше текущее изображение профиля и все предыдущие. Социальная сеть хранит эти фотографии в альбоме «Мои фото профиля». Примечательно, что этот альбом нельзя скрыть — он всегда остается общедоступным. Единственное, что вы можете сделать, это удалить старые изображения профиля: чем меньше у вас фотографий в этом альбоме, тем сложнее приложению вас распознать.
Совет: удалите старые фотографии. Храните в этом альбоме только последнее изображение, чтобы уберечь себя от тирании распознавания лиц.
2. Можно помешать распознаванию лиц, надев толстовку с капюшоном или отвернув голову от камеры или под необычным углом. Корчить смешные рожицы тоже можно, за некоторыми исключениями. Очки со сплошными кольцами работают просто идеально, если только у вас нет фото с такими же очками в вашем профиле (или с таким же забавным лицом).
советов и хитростей, которые нужно спрятать от бдительного глаза #BigBrother https://t.
— Лаборатория Касперского (@kaspersky) 9 октября 2015 г.
 co/xJ6VqqUKuo pic.twitter.com/oeNopI12hL
co/xJ6VqqUKuo pic.twitter.com/oeNopI12hL3.Многие добровольцы, принимавшие участие в эксперименте, не знали, что у них так много публичных фотографий. Да, они проверили параметры конфиденциальности в «Настройках», но этого было недостаточно, так как ВК позволяет ограничить доступ только к альбомам (и то не ко всем), а не к определенным фотографиям в частности.
Совет: попросите всех, кого вы знаете и кому доверяете, удалить вас из друзей (и снова подружиться после теста), изучить свою учетную запись и проверить, что видно, а что нет. Затем переместите фотографии из общедоступных альбомов в частные, если это необходимо.
4. FindFace работает абсолютно легально: не кэширует данные, чтобы показать какую-либо информацию, скрытую настройками социальных сетей. Когда мы удалили все фото с ВКонтакте, сервис перестал нас находить при втором поиске. Тем не менее, вполне возможно, что в будущем может появиться новый сервис, который будет вести себя еще хуже: например, он сможет хранить данные из других популярных социальных сетей, таких как Facebook или Instagram. Так что лучше заранее дважды проверить настройки безопасности для других учетных записей социальных сетей.
Так что лучше заранее дважды проверить настройки безопасности для других учетных записей социальных сетей.
Настройка ваших https://t.co/IQCYudiOoZ #настроек конфиденциальности https://t.co/jWyNOz0yLt #global #socme pic.twitter.com/m6P4nKRMhF
— Лаборатория Касперского (@kaspersky) 7 января 2016 г.
5. FindFace позиционирует себя как сервис знакомств. Например, вы видите симпатичного человека, делаете фото и просматриваете его аккаунт — ок, теперь вам нужно в тему сделать пропуск. На самом деле, этот сервис может позволить вам сделать гораздо больше полезных и странных вещей.
Вспомните историю, недавно обнародованную новостями ABC: камера наблюдения засняла грабителей, грабящих дом.Если бы это произошло в русскоязычных странах, то с вероятностью 99% у преступников был бы аккаунт на VK.com. Можно было бы воспользоваться сервисом, чтобы найти виновных.
С другой стороны, многие люди в социальных сетях используют вымышленные имена из соображений конфиденциальности, но публикуют настоящие фотографии. Им кажется, что Интернет слишком огромен и по фото их никто не найдет. Ну, они обязательно сделают, если захотят. Например, работодатели любят проверять страницы кандидатов в социальных сетях перед собеседованием.
Им кажется, что Интернет слишком огромен и по фото их никто не найдет. Ну, они обязательно сделают, если захотят. Например, работодатели любят проверять страницы кандидатов в социальных сетях перед собеседованием.
Как наш сотрудник узнал, что его цифровая идентификация была украдена
Некоторые люди просто не публикуют фотографии в социальных сетях. Вообще. Например, один из наших сотрудников работает таким образом. Тем не менее, FindFace нашел его.
Дело в том, что некто «Витек Тизинксилов» скопировал свою фотографию из галереи другого пользователя, которая была опубликована в другой социальной сети, и решил использовать ее в качестве своей аватарки.
Все ли ваши фотографии #Social общедоступны? Вы можете пересмотреть свое решение.Сказка об украденной личности. https://t.co/iXwrMP7kfI pic.twitter.com/3IxwzeQnPb
— Лаборатория Касперского (@kaspersky) 27 января 2016 г.
Когда мы попытались найти в Google Images ту же самую фотографию, мы обнаружили, что это изображение использовалось в качестве аватарки еще в одной социальной сети, которая называется Фотострана (что можно перевести как Фотострана). Это было совсем не сладкое открытие.
Это было совсем не сладкое открытие.
Так что, если вы ничего не выкладываете в сеть, это не значит, что вы невидимы: вместо вас это могут сделать ваши друзья.Если они выложат ваш портрет или даже групповое фото с вами — никто не может предсказать будущее этого изображения.
Совет: Прежде чем VK.com заблокирует API, используемый этим приложением, вы можете проверить, есть ли у вас клоны в социальных сетях.
3 реальных случая, когда #интернет превратил чью-то жизнь в ад https://t.co/d50zA1j3yw pic.twitter.com/kLKFVoNGOa
— Лаборатория Касперского (@kaspersky) 5 апреля 2016 г.
Отказ от ответственности: мы удалили данные о людях, чьи фотографии были сделаны в ходе эксперимента без их разрешения на их публикацию.
Как онлайн-системы распознавания лиц могут поставить под угрозу нашу конфиденциальность
Компания E&T провела реинжиниринг онлайн-системы распознавания лиц и показала, как тенденция к онлайн-поиску с поддержкой распознавания лиц может подвергнуть пользователей неожиданным рискам для конфиденциальности.
Когда я впервые воспользовался инструментом под названием FindClone, я столкнулся лицом к лицу с фальшивым профилем в социальной сети, который использовал мою фотографию в качестве изображения своего профиля.Человек решил, что стоит украсть мое лицо для своего фальшивого профиля в ВК, социальной сети, которую назвали русским ответом на Facebook.
FindClone использует программное обеспечение для распознавания лиц и сравнивает ваше входное изображение с миллионами изображений профиля ВКонтакте. Это бесплатно, но вы должны указать свой номер телефона. Я не был шокирован тем, что кто-то украл мое изображение — выдача себя за другое лицо с помощью выстрела в голову пугающе распространено; хакеры, преступники и фальшивые онлайн-датеры («сомы») делают это все время — что меня действительно беспокоило, так это то, насколько легко было установить связь между моим изображением и одним из меня, крутящимся в самом глубоком Интернете.
Ярким примером является Clearview. Согласно новостным сообщениям, технический стартап из Нью-Йорка извлек три миллиарда снимков головы и других изображений лиц со страниц социальных сетей. Скрапинг — это термин, который разработчики используют для сохранения данных и изображений на локальных серверах.
С этим скандалом фирма попала в заголовки газет по всему миру. Его генеральный директор оправдывает сбор средств тем, что он соответствует действующему законодательству, утверждая: «Люди в этих странах могут отказаться.Так почему же компания так жаждет наших изображений?
Фирма продает доступ к своей базе данных правоохранительным органам. Система упрощает их поиск, позволяя им за считанные секунды сравнить изображение подозреваемого в базе данных Clearview. Если они найдут совпадение, то смогут собрать достаточно сведений, чтобы произвести арест. В маркетинговых материалах компании отмечается помощь в поимке террористов.
Критики говорят, что компания мало изменилась с момента своего большого выхода в 2019 году, в том числе продолжала работать в эпоху пандемии. В марте Жозефина Вольф, обозреватель New York Times , написала, что продукт компании остается таким же опасным, инвазивным и ненужным, каким он был до распространения коронавируса.
В марте Жозефина Вольф, обозреватель New York Times , написала, что продукт компании остается таким же опасным, инвазивным и ненужным, каким он был до распространения коронавируса.
От чего мы отказываемся, если такие компании, как Clearview, могут очистить миллиарды наших личных изображений из социальных сетей? Во-первых, давайте посмотрим на бизнес. Clearview не одинок в этом пространстве. Недавнее расследование Netzpolitik обнаружило польскую компанию Pimeyes, которая собирает изображения из Интернета и продает услуги правоохранительным органам.Сообщается, что основатели Pimeyes Лукаш Ковальчик и Денис Татина накопили базу данных из 900 миллионов лиц.
Насколько прибыльны эти предприятия, мы не знаем, поскольку такие стартапы не обязаны публично раскрывать свои счета. Но это поднимает вопросы о том, может ли новый спрос стимулировать новое предложение. Другими словами, если бизнес по оказанию услуг правоохранительным органам является прибыльным, можем ли мы вскоре ожидать, что больше фирм последуют примеру Pimeyes и Clearview, чтобы заключать сделки без нашего лица?
Чтобы ответить на этот вопрос, мы должны спросить, что именно делают Clearview и Pimeyes. Как работает их предложение? Лучше всего это пояснить на упрощенном примере. Мы обнаружили, что почти каждый может воспроизвести базовую концепцию создания системы распознавания лиц.
Как работает их предложение? Лучше всего это пояснить на упрощенном примере. Мы обнаружили, что почти каждый может воспроизвести базовую концепцию создания системы распознавания лиц.
E&T подражали их работе, создав небольшую базу данных распознавания лиц, которая была протестирована путем подачи изображений моего лица. Это было просто, и вы можете легко повторить это дома, если вы немного разбираетесь в технологиях. Для сопоставления изображений из базы данных с изображениями, которые мы хотели протестировать, потребовалось всего несколько строк кода Python (популярный язык программирования).Процесс описан пошагово ниже.
Как создать собственную онлайн-систему распознавания лиц
Чтобы построить такую упрощенную систему, мы должны создать базу данных изображений, отражающую миллиарды снимков, собранных Clearview. Затем мы запускаем алгоритм, чтобы сопоставить их с нашими входными изображениями.
В конце концов мы объясним, что нужно, чтобы масштабировать его до опасного уровня — мы не поддерживаем этот шаг, но он поможет прояснить риски, которые он представляет для нашей конфиденциальности в Интернете.
Шаг 1. Установка программного обеспечения
Мы установили популярную библиотеку Python с открытым исходным кодом под названием FaceRecognition. Есть и другие, но мы использовали этот, так как это часто придумываемый вариант, который хвалят за его простоту и предполагаемую точность. Производители говорят, что это «самый простой в мире API распознавания лиц для Python и командной строки».
Изображение предоставлено Беном Хьюблом (замаскированные изображения)
Эксперимент E&T сравнивал лица одного и того же человека и проверял, может ли алгоритм распознавания лиц идентифицировать человека на других изображениях.
FaceRecognition был создан с использованием распознавания лиц dlib и основан на глубоком обучении, по словам его владельцев — системы искусственного интеллекта с глубоким обучением полагаются на использование нескольких слоев в сети. Точность модели составляет 99,38% в Labeled Faces in the Wild, общедоступном эталоне для проверки лиц, что делает его популярным вариантом и идеальным для эксперимента, подобного нашему.
E&T проверил это на нескольких моих фотографиях, которые попали в Интернет в течение нескольких лет.Результаты показывают, что алгоритм может проводить четкое различие между различными типами изображений лица. Он узнал меня по автопортрету, а также по изображению, скрывающему мой рот (см. рисунок).
Чтобы получить более достоверный образец и посмотреть, что работает, а что нет, мы добавили дополнительные изображения. Социальные сети с большим количеством изображений — хороший способ начать. Такие источники, как Twitter или Linkedin, которыми я пользуюсь уже много лет, а также интернет-журналы и газеты, где размещено мое изображение, предлагают достаточно фотографий для экспериментов.
Визуальные данные, такие как видеоконтент, также могут служить источником ввода. Несмотря на ухудшение качества разрешения, поиск по распознаванию лиц может работать с видео, если оно разбито на отдельные кадры. Когда дело доходит до видео, заслуживает внимания партнерство PimEyes с Paliscope. Правоохранительные органы используют возможности распознавания лиц Paliscope для идентификации людей на видео и в документах.
Правоохранительные органы используют возможности распознавания лиц Paliscope для идентификации людей на видео и в документах.
Итак, почему это забота о конфиденциальности? Предположим, вы отправились в место, которое раскрывает личную информацию; например, ночной клуб, реабилитационный центр для наркозависимых, клиника для тестирования на ИППП или протест против режима.Теперь предположим, что незнакомец в том же месте записал видео или сделал фотографии и загрузил их в Интернет. Теоретически, если этот материал раскрывает ваше лицо, он может разоблачить вас любому, у кого есть доступ к такому программному обеспечению и кто захочет вас расследовать. Пользователь, который видит вас и узнает вас в Интернете, подвергается относительно низкому риску, особенно с учетом того, насколько велик Интернет. Автоматизированный компьютерный процесс, который ищет ваше лицо, может быть более эффективным.
Однако, если у Clearview есть клиент, который ищет вас, алгоритм, который очищает соответствующие изображения, может помочь им обнаружить вас в кратчайшие сроки. Излишне говорить, что любая третья сторона, включая правительство, имеющая право связать вашу личность с местоположением или людьми, с которыми вас видели, может раскрыть личную информацию, которую вы предпочитаете держать в секрете.
Излишне говорить, что любая третья сторона, включая правительство, имеющая право связать вашу личность с местоположением или людьми, с которыми вас видели, может раскрыть личную информацию, которую вы предпочитаете держать в секрете.
Шаг 2. Сбор базы данных
В сети я копирую и вставляю каждое изображение своего лица, которое нахожу, и сохраняю в специальной папке. Возможно, этот процесс является более продвинутым для таких компаний, как Clearview. Вместо того, чтобы копировать и вставлять каждое изображение одно за другим, профессионалы запускают автоматические программы очистки, которые ускоряют процесс сбора данных.
Изображение предоставлено: Ben Heubl, скрытые изображения
Чтобы установить связь между личностью и фотографиями, онлайн-изображения должны иметь ссылку. Под этим мы подразумеваем, что они должны быть помечены именем или информацией, которая связывает их с вашей личностью. Чтобы быть полезными — или вредными, в зависимости от вашего взгляда — для кого-либо, включая клиентов Clearview, эталонные изображения должны быть проиндексированы. Мы сделаем это, называя изображения по правильному имени, например «Ben_glasses.png», «Ben_winterhat.png» или «Ben_cap.png» (см. выше).
Мы сделаем это, называя изображения по правильному имени, например «Ben_glasses.png», «Ben_winterhat.png» или «Ben_cap.png» (см. выше).
У государственных органов есть преимущество, когда дело доходит до проиндексированных личных изображений, поскольку у них может быть ваше изображение уже в файле. Они знают, кто ты. Например, у меня есть паспорт и водительские права с моим изображением, копии которых есть у властей. Если злонамеренное правительство захочет проверить, посещали ли вы вышеупомянутые места, оно может использовать проиндексированные фотографии вашего паспорта в базе данных изображений для сравнения онлайн-видео и изображений. В какой степени европейские правила GDPR могут запрещать такие компании, как PimEyes, остается в значительной степени неясным.
Обратите внимание, что мы храним две папки для нашей системы: одну папку с проиндексированными изображениями — «известная папка»; другой с неизвестными изображениями — «неизвестная папка». Мы говорим библиотеке Python с открытым исходным кодом сравнить папки.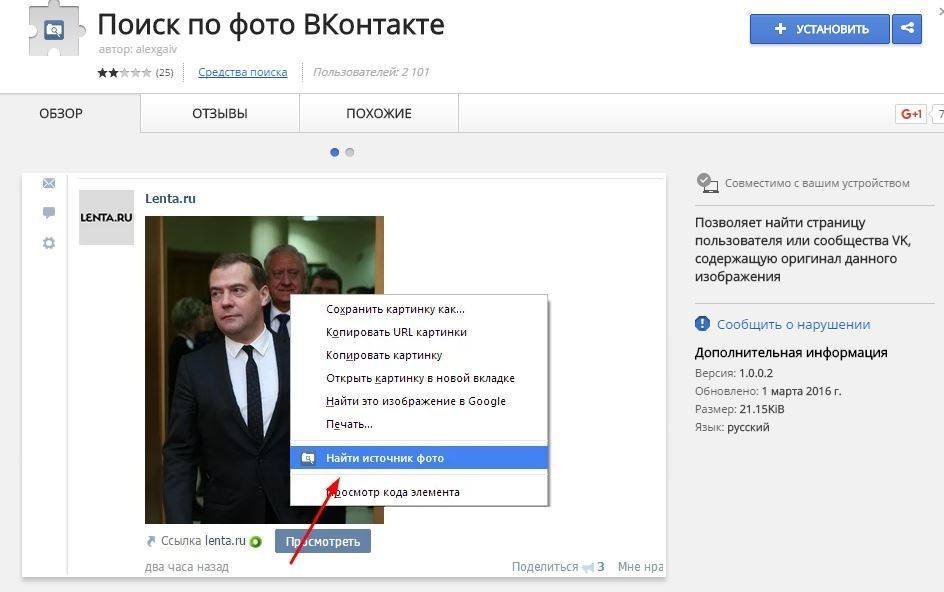 Когда система находит совпадения между проиндексированными и неиндексированными папками изображений, нам сообщают об этом через примечание в окне терминала Mac OS. Вы также можете запросить соответствующий балл. Если мы считаем, что алгоритм слишком нечувствителен, т. е. приводит к слишком большому количеству совпадений, мы можем отрегулировать циферблат в зависимости от того, насколько чувствительным должен быть алгоритм при сравнении изображений.
Когда система находит совпадения между проиндексированными и неиндексированными папками изображений, нам сообщают об этом через примечание в окне терминала Mac OS. Вы также можете запросить соответствующий балл. Если мы считаем, что алгоритм слишком нечувствителен, т. е. приводит к слишком большому количеству совпадений, мы можем отрегулировать циферблат в зависимости от того, насколько чувствительным должен быть алгоритм при сравнении изображений.
Шаг 3. Увеличение масштаба
Последний шаг включает масштабирование всего этого. Это означает, что вместо того, чтобы использовать всего несколько изображений, мы собираем и сравниваем миллиарды онлайн-изображений — одна из причин, по которой Clearview теперь сталкивается с международным расследованием.
Изображение предоставлено: скриншоты PimEyes; Бен Хьюбл
Чтобы увидеть работающую масштабируемую версию, вы можете попробовать FindClone и PimEyes. Оба находятся в свободном доступе, что делает их более вероятными для злоупотреблений — однако для PimEyes вы можете загрузить только изображение, снятое с камеры вашего ноутбука, что, как надеются операторы, демотивирует злоупотребления со стороны тех, кто любит находить других людей.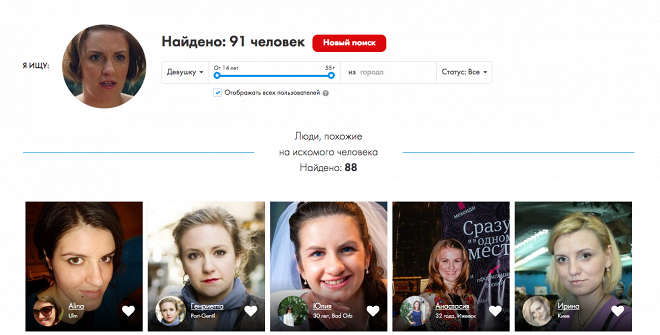
Если вы находитесь в стране западной демократии, включая Великобританию или США, PimEyes может дать вам лучшие результаты, поскольку FindClone работает только с (в основном русскими) профилями ВКонтакте.
Мы протестировали PimEyes и обнаружили, что результаты поразительно точны. Загружая изображения своего лица, результаты показывают, где ваше лицо появляется на различных платформах и какая учетная запись была ответственна за его публикацию. Из пяти результатов моего самоизоляции, включая новые очки, три были точными.Два результата меня удивили, потому что я совершенно забыл, где и зачем делал фотографии.
Вопросы конфиденциальности
Все ли поиски изображений плохие? Некоторые указывают на технологического гиганта Google, который до сих пор предлагает обратный поиск изображений. Вы можете загрузить изображение, и результаты поиска Google могут содержать похожие цвета, узоры или фон, а иногда и то же изображение, которое было загружено. Тем не менее, на момент написания статьи избегайте запуска программного обеспечения для распознавания лиц при поиске.Как скоро это изменится? Такой мощный центр, как Google, может счесть тривиальной задачей сделать изображения лиц доступными для поиска, и последствия этого могут иметь далеко идущие последствия. Любое изображение человека, сделанное на улице, может внезапно стать объектом обратного поиска по изображению лица. Результаты для профилей или документов в социальных сетях могут немедленно раскрыть личность человека.
Тем не менее, на момент написания статьи избегайте запуска программного обеспечения для распознавания лиц при поиске.Как скоро это изменится? Такой мощный центр, как Google, может счесть тривиальной задачей сделать изображения лиц доступными для поиска, и последствия этого могут иметь далеко идущие последствия. Любое изображение человека, сделанное на улице, может внезапно стать объектом обратного поиска по изображению лица. Результаты для профилей или документов в социальных сетях могут немедленно раскрыть личность человека.
Google постоянно пытается улучшить поиск, в том числе с помощью изображений. Вы уже можете улучшить свои шансы найти лица, добавив «&imgtype=face» после URL-адреса, из которого вы указали результаты поиска лиц.Но результаты остаются в лучшем случае посредственными и не зависят от распознавания лиц.
Конкуренция также может побудить Google добавить более навязчивые функции поиска по распознаванию лиц. Естественно, операторы поисковых систем стремятся предоставить лучший сервис, стараясь не потерять пользователей.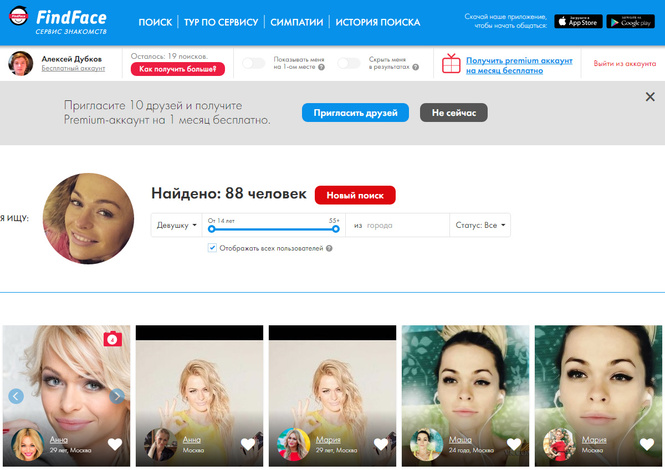 Вполне логично добавлять новые функции для достижения лучших результатов. Что делает конкурс? Российский конкурент Яндекс уже включил функции распознавания лиц для поиска изображений. Вот почему его результаты, как говорят некоторые, часто превосходят результаты Google.Яндекс также позволяет искать изображения и текст вместе.
Вполне логично добавлять новые функции для достижения лучших результатов. Что делает конкурс? Российский конкурент Яндекс уже включил функции распознавания лиц для поиска изображений. Вот почему его результаты, как говорят некоторые, часто превосходят результаты Google.Яндекс также позволяет искать изображения и текст вместе.
Если достаточное количество людей перейдет с Google на другие поисковые системы, может ли это подтолкнуть компанию к потенциально неэтичным решениям? Этика находится в центре обсуждения. Сообщалось, что NtechLab, компания по распознаванию лиц, поставила российскому правительству технологию массового наблюдения. Сегодня он служит российскому государству в Москве для обеспечения массовой слежки.
В 2016 году NtechLab запустила FindFace, который впоследствии был закрыт для публичного использования и теперь предлагает только платную версию, которую E&T не тестировал.Он представил что-то похожее на то, что бесплатно предлагают PimEyes или FindClone.
Возможно, еще более спорным моментом является то, что после пандемии клиентам предлагалась возможность идентифицировать людей, нарушающих правила блокировки Covid-19. На своем веб-сайте NtechLab утверждает, что «мы в NtechLab усердно работаем над корректировкой и внедрением нашей системы контроля вспышек и карантина для борьбы с пандемией». NtechLab обещает, что сможет «распознавать людей, находящихся на домашнем карантине, и отправлять немедленные уведомления при их появлении в поле зрения камеры, даже если лицо закрыто медицинской маской».Активисты за права на конфиденциальность могут счесть утомительной идею разрешить распознавание лиц, чтобы помочь в поиске нарушителей блокировки.
Однако не все так плохо, и онлайн-распознавание лиц может иметь некоторые преимущества. Благодаря улучшенным функциям поиска поиск информации о других пользователях сети может пригодиться полиции, следователям и пользователям. Предположим, вы «встречаетесь вслепую» с человеком из приложения онлайн-знакомств Tinder.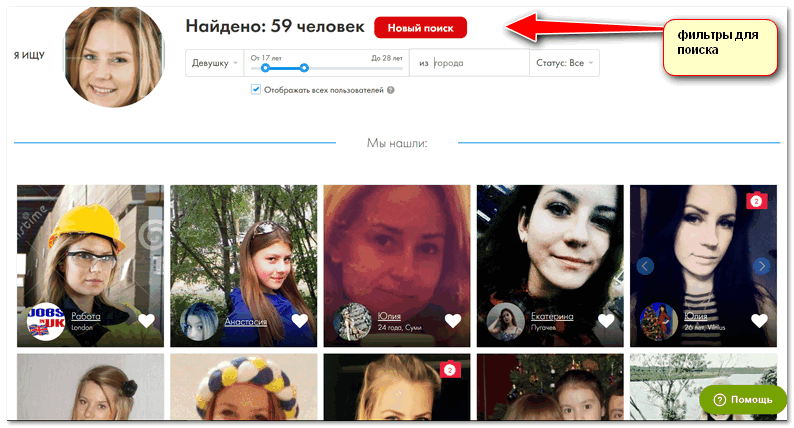 Проверка того, является ли человек реальным и соответствует ли он описанию, до того, как вы встретились, может помочь избежать неприятных сюрпризов и повысить безопасность пользователей.
Проверка того, является ли человек реальным и соответствует ли он описанию, до того, как вы встретились, может помочь избежать неприятных сюрпризов и повысить безопасность пользователей.
Есть случай, когда технические журналисты-расследователи использовали распознавание лиц для разведывательной работы с открытым исходным кодом, и были случаи, когда FindClone или PimsEye оказались полезными для проверки дезинформации и отдельных источников. В обоих случаях здесь вопрос заключается в том, является ли угроза конфиденциальности большей, чем польза.
Распознавание лиц остается спорной темой, и различные правительства решили, что безопаснее объявить его вне закона. Некоторые опасения связаны с предостережениями, такими как неточность и опасения, связанные с расовой предвзятостью.Недавние протесты Black Lives Matter, подчеркивающие отсутствие расового равенства, только усилят давление.
В январе комиссия ЕС заявила, что рассмотрит вопрос о запрете распознавания лиц на срок до пяти лет, пока не будут найдены приемлемые способы предотвращения злоупотреблений системой.
Компаниям, работающим в социальных сетях, это не нравится: использование PimEyes контента Instagram и YouTube побудило их подать в суд на поисковую систему, и PimEyes рискует получить большие штрафы за потенциальное нарушение правил GDPR — подробности о том, насколько высокими могут быть эти штрафы, остаются неясными. быть, но аналогичные нарушения предполагают, что они могут быть значительными.В прошлом году на компанию был наложен штраф в размере 200 000 евро за использование персональных данных из открытых источников.
Итак, как решить загадку конфиденциальности? Может сработать более радикальное политическое вмешательство. Есть и другие, более технические решения. Одним из них является маскировка изображений, которая относится к методу, усложняющему системам распознавания лиц идентифицировать людей по изображениям. Чередование крошечных изменений на уровне пикселей, невидимых для человеческого глаза, делает личное изображение неузнаваемым системой распознавания лиц, если исходная модель была обучена на основе измененного изображения. Результаты других, в том числе тесты, проведенные New York Times , подтвердили, что он работает на новых алгоритмах, использующих «замаскированные» изображения.
Результаты других, в том числе тесты, проведенные New York Times , подтвердили, что он работает на новых алгоритмах, использующих «замаскированные» изображения.
Остается один существенный недостаток: «Маскировка фотографий с помощью Фоукса не затрудняет их распознавание», — объясняет Бен И Чжао, профессор компьютерных наук Чикагского университета. Компания E&T протестировала маскировку изображений из первых рук, запустив предыдущий эксперимент на моем лице, хотя на этот раз мы использовали систему закрытия Fawkes для входных изображений.Программный пакет Mac OS с открытым исходным кодом предлагает легкий доступ для локального запуска инструмента на изображениях. Объяснение Чжао является причиной того, что замаскированные изображения все еще могут сопоставляться с нашей самодельной системой распознавания лиц, несмотря на то, что они замаскированы. Короче говоря, маскировка не работает сразу и окупится только со временем, поскольку алгоритмы будут использовать мои скрытые изображения, которые я сначала должен сделать доступными в Интернете.
Такие системы, как Fawkes, по-прежнему дают некоторую надежду в борьбе за конфиденциальность в Интернете (все изображения в этой статье подверглись маскировке).Возможно, однажды мы сможем снова стать анонимными пользователями сети, что в первую очередь сделало Интернет хитом.
Подпишитесь на электронную рассылку E&T News, чтобы каждый день получать подобные замечательные истории на свой почтовый ящик.
Объяснение | Технология распознавания лиц в аэропортах Индии
В рамках какой схемы Диги-ятры реализуется FRT? Какие опасения связаны с биометрическими технологиями?
В рамках какой схемы Диги-ятры реализуется FRT? Какие опасения связаны с биометрическими технологиями?
История на данный момент: На прошлой неделе государственный министр гражданской авиации В.К. Сингх сказал, что в четырех аэропортах страны скоро будет установлена система посадки пассажиров на основе технологии распознавания лиц (FRT).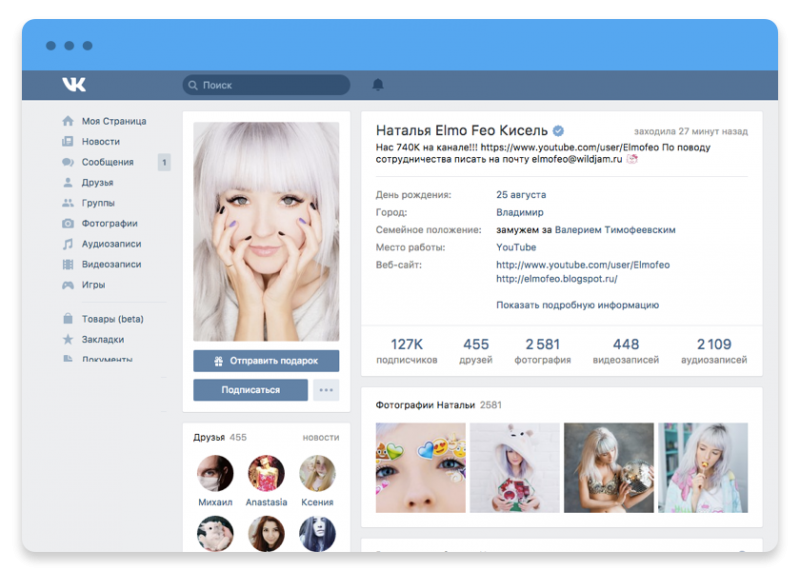 В письменном ответе на вопрос в Lok Sabha в четверг г-н Сингх сказал, что Управление аэропортов Индии (AAI) работает над биометрической системой посадки в аэропортах Варанаси, Пуны, Калькутты и Виджаявады.
В письменном ответе на вопрос в Lok Sabha в четверг г-н Сингх сказал, что Управление аэропортов Индии (AAI) работает над биометрической системой посадки в аэропортах Варанаси, Пуны, Калькутты и Виджаявады.
«Эта биометрическая система регистрации является частью первого этапа реализации схемы Digi Yatra», — сказал г-н Сингх в ответе.
Что такое схема Диги-ятры?
Инициатива Digi Yatra направлена на то, чтобы сделать авиаперелеты в стране безбумажными и беспроблемными, и предлагает упростить процессы, связанные с пассажирами, на различных контрольно-пропускных пунктах в аэропорту с помощью биометрического сканирования на основе FRT.
После внедрения авиапассажирам, решившим воспользоваться этой услугой, не нужно будет предъявлять свои билеты, посадочные талоны или удостоверения личности в нескольких точках аэропорта. Это, в свою очередь, сократит время ожидания в очереди и ускорит время обработки.
Как Министерство гражданской авиации (MoCA) планирует это реализовать?
MoCA планирует создать платформу управления идентификацией, которая позволит осуществлять биометрическое сканирование во всех аэропортах Индии.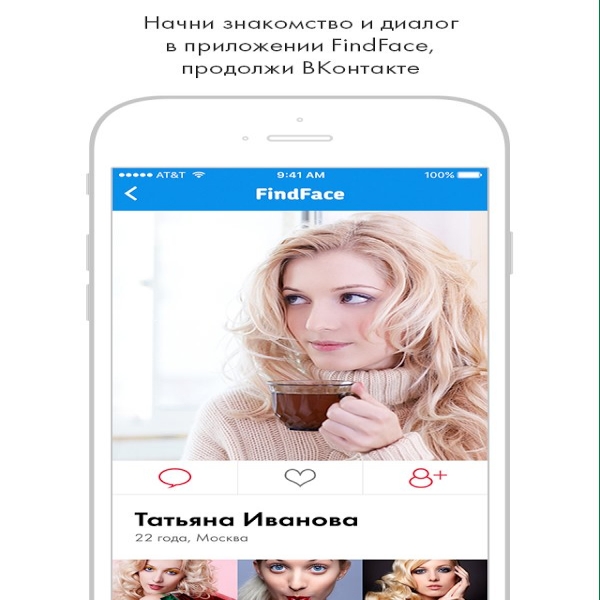 Платформа будет включать цифровые удостоверения личности пассажиров, такие как Aadhaar, паспортные данные или другие удостоверения личности.
Платформа будет включать цифровые удостоверения личности пассажиров, такие как Aadhaar, паспортные данные или другие удостоверения личности.
Платформа Common Digi Yatra ID будет использоваться для регистрации пассажиров, аутентификации их данных и обмена профилями пассажиров с другими аэропортами-партнерами. Интерфейс на основе приложений будет построен как общая национальная инфраструктура, которая будет предоставлять API для аэропортов. Это также позволит интегрировать с ним другие приложения, согласно директивному документу MoCA 2018 года по схеме.
Каков статус реализации?
Планировалось, что схема будет введена в действие в начале 2019 года с пилотным запуском в аэропортах Бангалора и Хайдарабада.К середине 2019 года международный аэропорт Кемпегоуда в Бангалоре успешно протестировал систему самообслуживания на основе биометрических данных.
AAI планировала запустить схему в Калькутте, Варанаси, Пуне и Виджаяваде к апрелю 2019 года. Но развертывание было отложено, возможно, из-за пандемии COVID-19. В настоящее время MoCA пересматривает свои планы развертывания и предлагает запустить систему Digi Yatra в марте 2022 года, а затем поэтапно масштабировать ее для внедрения в различных аэропортах страны.
В настоящее время MoCA пересматривает свои планы развертывания и предлагает запустить систему Digi Yatra в марте 2022 года, а затем поэтапно масштабировать ее для внедрения в различных аэропортах страны.
AAI наняла NEC Corporation Pvt. ООО внедрить FRT в четырех аэропортах.
Как насчет конфиденциальности данных пассажиров?
«Данные, переданные пассажиром, должны использоваться для определенной цели и не будут передаваться никаким другим внешним заинтересованным сторонам», — сказал г-н Сингх.
Биометрические данные пассажиров будут собираться через приложение и удаляться через 24 часа после вылета рейса. По словам министра, безопасность системы FRT будет проверяться самостоятельно.
Он также отметил, что развернутый FRT будет соответствовать принятым в стране правилам конфиденциальности и защиты данных.
Но недавно принятый в Индии законопроект о защите персональных данных (PDPB) 2019 года не соответствует стандартам, установленным Комитетом юстиции Шрикришны. Законопроект не может создать юридическую структуру на ориентире Судья К.С. Путтасвами против Союза Индии решение о праве на неприкосновенность частной жизни. Он отличается от проекта Комитета от 2018 года, в котором предлагался судебный надзор при выборе членов Управления по защите данных.
Законопроект не может создать юридическую структуру на ориентире Судья К.С. Путтасвами против Союза Индии решение о праве на неприкосновенность частной жизни. Он отличается от проекта Комитета от 2018 года, в котором предлагался судебный надзор при выборе членов Управления по защите данных.
Во всем мире быстрое внедрение FRT вызывает несколько опасений, в первую очередь связанных с возможностью того, что эта технология может подорвать право на неприкосновенность частной жизни. Политика, направленная на снижение рисков, связанных с использованием FRT, должна быть разработана для защиты персональных данных.
Какие проблемы возникают при использовании биометрического сканирования в аэропорту?
В последние несколько лет в некоторых международных аэропортах используется сканирование радужной оболочки глаза, отпечатки пальцев и распознавание лиц для идентификации путешественников.Они используют алгоритмические системы, чтобы захватить лица пассажиров на первом контрольно-пропускном пункте.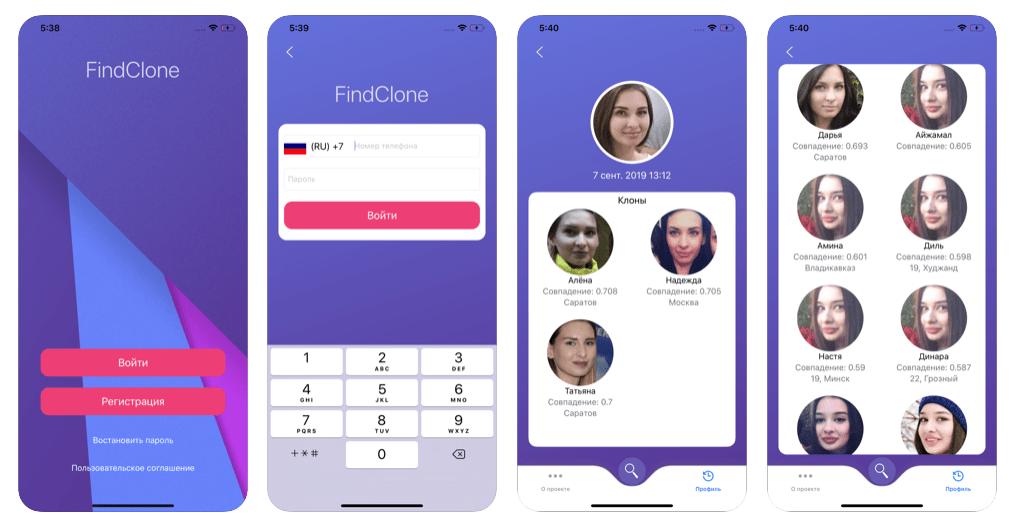
Камера сканирует лицо пассажира и измеряет его черты лица, чтобы построить его биометрический профиль. А затем, когда тот же человек садится в самолет, другая камера делает снимок его лица и запускает алгоритм, чтобы проверить, совпадают ли два изображения с посадочным талоном. В 2019 году твит путешественницы стал вирусным — она рассказала о своем опыте прохождения системы биометрического сканирования для авиакомпании JetBlue без ее ведома.В основе ее беспокойства была возможность подписаться на услугу или отказаться от нее.
Не имея четкого представления о том, где будут храниться биометрические данные и кто еще будет иметь к ним доступ, некоторые пассажиры предпочитают держать свои личные данные в тайне. «Это может показаться банальным, но прямо сейчас ключом к отказу от распознавания лиц является бдительность», — написала в своем блоге группа Electronic Frontier Foundation, занимающаяся цифровыми правами. «Нет ни одного пункта, который вы можете отметить, и, что важно, это может быть невозможно для не-U. S. лицам полностью отказаться от распознавания лиц».
S. лицам полностью отказаться от распознавания лиц».
Существуют ли другие проблемы при использовании биометрического сканирования?
Растущее количество исследований показывает, что технологии биометрического сканирования в сочетании с искусственным интеллектом имеют присущую им предвзятость. В отчете Национального института стандартов и технологий США отмечается, что технология распознавания лиц показала, что чернокожие, коричневые и азиатские лица в 100 раз чаще ошибочно идентифицируются, чем лица белых мужчин.
Исследовательская работа 2018 года, в соавторстве с бывшим ведущим специалистом Google по искусственному интеллекту Тимнитом Гебру и Джой Буоламвини из MIT Media Labs, показала, что алгоритмы машинного обучения различают такие классы, как раса и пол.
Распознавание эмоций по геометрическим чертам лица с помощью самоорганизующейся карты
Анима Маджумдер получила степень бакалавра технических наук. степень Северо-восточного регионального института науки и технологий (NERIST), Итанагар, Индия, в 2005 г. и степень магистра технических наук. в 2007 году получила степень в Инженерно-технологическом институте Шри Гуру Говинд Сингджи (SGGS), Нандед, Индия. Она работала старшим инженером-программистом в компании Robert Bosch Engineering and Business Solutions Ltd., Бангалор, Индия. В настоящее время она кандидат наук.D. Стипендиат кафедры электротехники Индийского технологического института Канпура (IITK), Канпур, Индия. Ее исследовательские интересы включают компьютерное зрение, машинное обучение и обработку изображений.
и степень магистра технических наук. в 2007 году получила степень в Инженерно-технологическом институте Шри Гуру Говинд Сингджи (SGGS), Нандед, Индия. Она работала старшим инженером-программистом в компании Robert Bosch Engineering and Business Solutions Ltd., Бангалор, Индия. В настоящее время она кандидат наук.D. Стипендиат кафедры электротехники Индийского технологического института Канпура (IITK), Канпур, Индия. Ее исследовательские интересы включают компьютерное зрение, машинное обучение и обработку изображений.
Лаксмидхар Бехера получил степень бакалавра наук. и магистр наук. степени инженера Национального технологического института Руркела, Руркела, Индия, в 1988 и 1990 годах соответственно, и докторскую степень. степень Индийского технологического института (IIT) Дели, Нью-Дели, Индия. В 2000–2001 годах он продолжил обучение в аспирантуре Немецкого национального исследовательского центра информационных технологий (GMD), Санк-Августин, Германия.В 1995–1999 годах он был доцентом Института технологии и науки Бирла, Пилани, Индия. Он также работал читателем в Университете Ольстера, Лондондерри, Великобритания, и в качестве приглашенного исследователя в Fraunhofer-Gesellschaft, Санкт-Августин, Бонн, и в Eidgenoessische Technische Hochschule Zurich, Цюрих, Швейцария. В настоящее время он является профессором кафедры электротехники Индийского технологического института Канпура (IITK), Канпур, Индия. На его счету более 125 статей, опубликованных в реферируемых журналах и представленных в материалах конференций.Его исследовательские интересы включают интеллектуальное управление, робототехнику, нейронные сети и когнитивное моделирование.
Он также работал читателем в Университете Ольстера, Лондондерри, Великобритания, и в качестве приглашенного исследователя в Fraunhofer-Gesellschaft, Санкт-Августин, Бонн, и в Eidgenoessische Technische Hochschule Zurich, Цюрих, Швейцария. В настоящее время он является профессором кафедры электротехники Индийского технологического института Канпура (IITK), Канпур, Индия. На его счету более 125 статей, опубликованных в реферируемых журналах и представленных в материалах конференций.Его исследовательские интересы включают интеллектуальное управление, робототехнику, нейронные сети и когнитивное моделирование.
Венкатеш К. Субраманиан получил степень бакалавра. степень Бангалорского университета, Индия, в 1987 году. Он получил степень магистра технических наук. и доктор философии степени Индийского технологического института Канпура (IIITK), Канпур, Индия, в 1989 и 1995 годах соответственно. В настоящее время он является адъюнкт-профессором кафедры электротехники Индийского технологического института в Канпуре. Его исследовательские интересы включают обработку сигналов, обработку изображений и видео, теорию сигналов и систем, а также компьютерное зрение с приложениями в робототехнике.
Его исследовательские интересы включают обработку сигналов, обработку изображений и видео, теорию сигналов и систем, а также компьютерное зрение с приложениями в робототехнике.
Copyright © 2013 Elsevier Ltd. Все права защищены.
В этих 4 аэропортах Индии к марту 2022 года будет реализовано распознавание лиц и Виджаявада к марту 2022 года в рамках правительственной схемы Диги-ятры. Эшита Шринивас
Государственный министр гражданской авиации В. К. Сингх заявил, что Управление аэропортов Индии работает над созданием первых в стране систем биометрического посадки на основе распознавания лиц для аэропортов Варанаси, Пуны, Калькутты и Виджаявады.
Схема Диги-ятры будет внедряться поэтапно
Эта биометрическая система является частью первого этапа правительственной программы Digi Yatra, которая была ранее обнародована в октябре 2018 года и запланирована на апрель 2019 года. плоскости сервис будет запущен в марте 2022 года.
Администрация аэропортов Индии работает над первой в Индии системой посадки пассажиров на основе распознавания лиц: MoS для гражданской авиации В.
— Press Trust of India (@PTI_News) 2 декабря 2021 г.
 К. Сингх
К. СингхВ письменном ответе на вопрос в Lok Sabha В. К. Сингх сказал: «Центральная экосистема Digi Yatra предусматривает оценку (независимыми группами для оценки уровня безопасности и устойчивости системы для защиты PII) и периодические проверки со стороны руководящих или регулирующих органов. дважды каждый год.Распознавание лиц соответствует отраслевым стандартам ISO с лучшими в своем классе алгоритмами, перечисленными Национальным институтом стандартов и технологий (NIST), которые соответствуют требованиям конфиденциальности и защиты данных, установленным правительством».
Хотя распознавание лиц еще не было установлено ни в одном из аэропортов, В. К. Сингх добавил, что Управление аэропортов Индии (AAI) наняло NEC Corporation Private Limited для установки технологии в четырех вышеуказанных аэропортах, находящихся в ведении AAI. .После этого технология будет внедрена во всех крупных аэропортах страны, согласно отчету Economic Times .
Регистрация в системе распознавания лиц необязательна
Отвечая на опасения по поводу безопасности данных пассажиров, В. К. Сингх заявил, что регистрация в службе не является обязательной для пассажиров. Регистрация потребует от них отправки сведений о поездке, таких как номер PNR и биометрические данные лица, через приложение в биометрическую систему посадки соответствующего аэропорта вылета.Однако пассажир может вместо этого использовать существующий ручной процесс посадки, согласно отчету Hindustan Times .
«Данные, предоставленные пассажирами, будут использоваться для определенной цели и не будут передаваться никаким другим внешним заинтересованным сторонам. Данные, предоставленные пассажирами, будут храниться во время их транзита в аэропорту и не будут храниться более 24 часов после вылета рейса». он сказал.
Связано: Вариант Omicron: выпущены новые правила для авиапассажиров, путешествующих в Махараштру
Программная среда распознавания лиц на основе основного компонента анализ
В этом разделе сначала представлен классический процесс распознавания лиц на основе PCA,
который показывает весь рабочий процесс и предлагает некоторые общие подходы к процессу.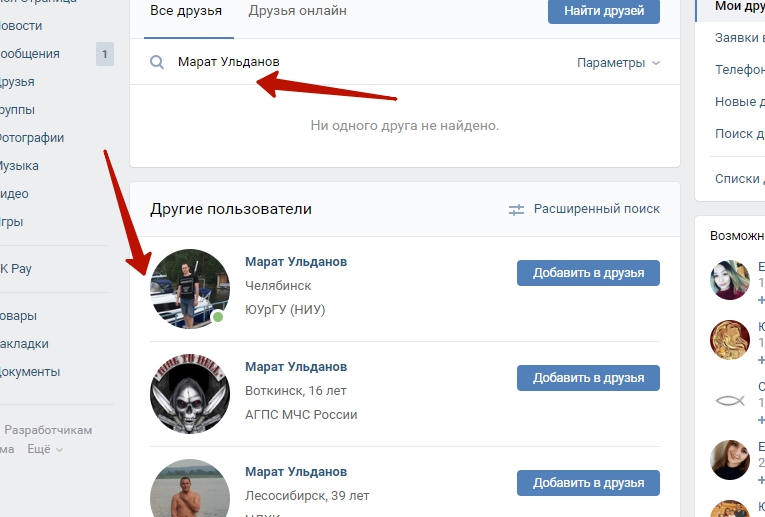 Затем предлагается программная среда для системы распознавания лиц на основе PCA. Все
компоненты, содержащиеся в структуре, демонстрируются в деталях.
Затем предлагается программная среда для системы распознавания лиц на основе PCA. Все
компоненты, содержащиеся в структуре, демонстрируются в деталях.
Процесс распознавания лица на основе PCA
показывает все лицо Процесс распознавания с помощью PCA включает шесть основных этапов: (1) изображение представление, (2) обнаружение областей лица, (3) обнаружение черт лица, (4) предварительная обработка, (5) проведение PCA и (6) проверка. Представление изображения шаг, во время которого данные изображения преобразуются в нужный формат.Лицо определение области и определение черт лица воздействуют на метаданные, подготавливая их к следующие шаги. Предварительная обработка — это этап, на котором окружающая среда влияние, такое как освещение, уменьшается, так что точная информация об изображении можно выставлять. Наконец, при проведении PCA пороги, определенные на Шаг проверки используется в классификации изображений.
Поток системы распознавания лиц на основе PCA.
Верификация изображения лица при использовании PCA требует двух наборов данных изображений: один и тестовый.Прежний набор данных предоставляет данные, так что настроенный Модель PCA может быть построена. Последний набор данных содержит изображения для проверки.
Представление изображения
Обычно изображения хранятся в компьютере в двумерной (2D) матрице
формат. Элементы этой матрицы представляют собой пиксели со значениями в диапазоне от
от нуля до 255. Цветные изображения имеют 3 разных канала, которые используются для
представляют цвета, такие как красный, зеленый и синий. Дополнительный канал, названный α используется для представления прозрачности изображения.Размер
матрица, количество ее строк и столбцов зависит от разрешения изображения. В виде
как следствие, изображения с более высоким разрешением занимают больше места для хранения.
Кроме того, размер матрицы существенно влияет на скорость вычисления матрицы, т.к.
создание потребности в методах сжатия данных.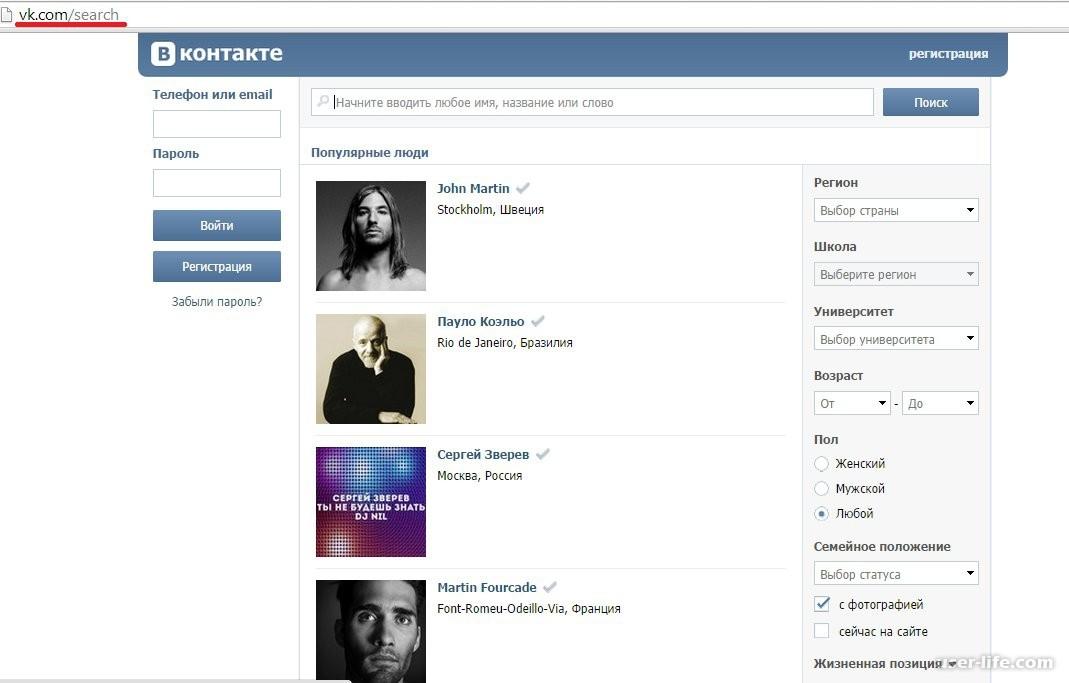 Это мотивирует наше использование
СПС.
Это мотивирует наше использование
СПС.
Представление изображения относится не только к минимизации размера изображения. То выбор подходящего подхода к представлению изображения для алгоритм распознавания повышает эффективность и точность.Это обсуждается в более подробно в разделе.
Обнаружение лиц
При обнаружении лиц область, содержащая лицо, извлекается из
фон изображения. Этот метод широко используется в большинстве смартфонов.
на сегодняшний день и хорошо работает в большинстве ситуаций. При обнаружении лиц с помощью
камеры смартфона, приблизительной области лица может быть достаточно, однако
важно отметить, что при распознавании лиц незначительный шум
влияет на конечный результат. Наш фреймворк зависит от выбранного распознавания лиц
техника, которая затем зависит от качества изображения, содержащего лицо
для получения точного результата.В некоторых ситуациях, например, когда цвет кожи
подобен фоновому цвету, когда часть лица находится в тени или когда
человек не смотрит прямо в камеру, получение области лица
более сложной.
Обнаружение признаков
Совмещение изображения выполняется для достижения высокой точности распознавания при использовании СПС. Обычно предпочтение отдается аффинному преобразованию из-за его простота и скорость вычислений. Чтобы выполнить аффинное преобразование, три характерные точки на изображении лица обязательны.Один общий выбор для этих три точки — это зрачки глаз и центральная точка рта. Таким образом, основная задача этого шага состоит в том, чтобы выявить эти три характерные точки. в образе лица.
В 2003 г. Пэн и др. предложили метод обнаружения признаков на основе веса
сходство [48].
Первоначально подход преобразует анализируемое изображение в бинарное
формат, а область лица может быть представлена Б ( х , у ). Уравнение (9) показывает
порог для бинарного изображения, где H ( i )
обозначает гистограмму исходного изображения.На основе пикселя
распределение изображения лица, примерные площади слева и справа
глаза можно измерить. Они могут быть представлены как л ( х , у ) и Р ( х , и ),
соответственно. Так как цвет зрачков отличается от остальной части глаза,
один раз точка P л ( x , y ) = 1 найдено, можно принять за левый зрачок
кандидат. Точно так же, как только точка P р ( х , y ) = 1 найдено, можно принять за правый зрачок
кандидат.Если оба из P l и P r соответствует показанному условию
в уравнении (10),
их можно подтвердить как центральные точки двух зрачков. Обратите внимание, что в
Уравнение (10), γ ( P л , P r ) есть подобие
окрестности P l и Р р и Д ( П л , Р р ) и А ( П л , P r ) расстояние
ограничение и угловое ограничение Р л и P r соответственно.
Они могут быть представлены как л ( х , у ) и Р ( х , и ),
соответственно. Так как цвет зрачков отличается от остальной части глаза,
один раз точка P л ( x , y ) = 1 найдено, можно принять за левый зрачок
кандидат. Точно так же, как только точка P р ( х , y ) = 1 найдено, можно принять за правый зрачок
кандидат.Если оба из P l и P r соответствует показанному условию
в уравнении (10),
их можно подтвердить как центральные точки двух зрачков. Обратите внимание, что в
Уравнение (10), γ ( P л , P r ) есть подобие
окрестности P l и Р р и Д ( П л , Р р ) и А ( П л , P r ) расстояние
ограничение и угловое ограничение Р л и P r соответственно. После
определение двух зрачков, центральной точки рта P m можно подтвердить
интегральная проекция. показывает поток обнаружения признаков.
После
определение двух зрачков, центральной точки рта P m можно подтвердить
интегральная проекция. показывает поток обнаружения признаков.
B(x,y)={0ifA(x,y)≥θ1ifA(x,y)≤θ,∑i=0θH(i)=15%×∑255i=0H(i)}
(9)
B(x,y)=max(γ(Pl,Pr)D(Pl,Pr)A(Pl,Pr))
(10)
Предварительная обработка
Предварительная обработка изображения является важным этапом в распознавании лиц, поскольку оно находится в
На этом шаге большинство факторов, потенциально влияющих на распознавание лиц, могут быть
устранено.Существует множество различных методов снижения шума, в том числе
нормализация гистограммы или преобразование изображения в двоичное представление.
Снижение шума является целью большинства этих методов, но некоторые из них также
изменить формат изображения, который затем можно будет использовать на последующих этапах. Эта секция
продолжает описание обнаружения признаков и знакомит с процессом
аффинное преобразование изображений.
Как обсуждалось ранее, три характерные точки, т. е. два зрачка и центральную точку рта можно представить как П л , Р р и P м .Аффинный трансформация выравнивает изображения по одному и тому же шаблону. Эти три характерные точки остаются в том же положении, а другие пиксели перемещаются. Уравнение (11) описывает основную идею аффинного преобразования. Обратите внимание, что ( x , y ) обозначают пиксели на исходное изображение лица и ( x ′, y ′ ) их результирующее место в образе шаблона после преобразования.
[x′y′]=[a11a12a13a21a22a23][xy1],[a11a12a21a22]≠0
(11)
Анализ главных компонент
Карл Пирсон изобрел концепции PCA в 1901 году [11].В исходной идее
ортогональное преобразование используется для преобразования набора наблюдений
возможно коррелированные переменные в набор значений линейно некоррелированных
переменные, называемые главными компонентами.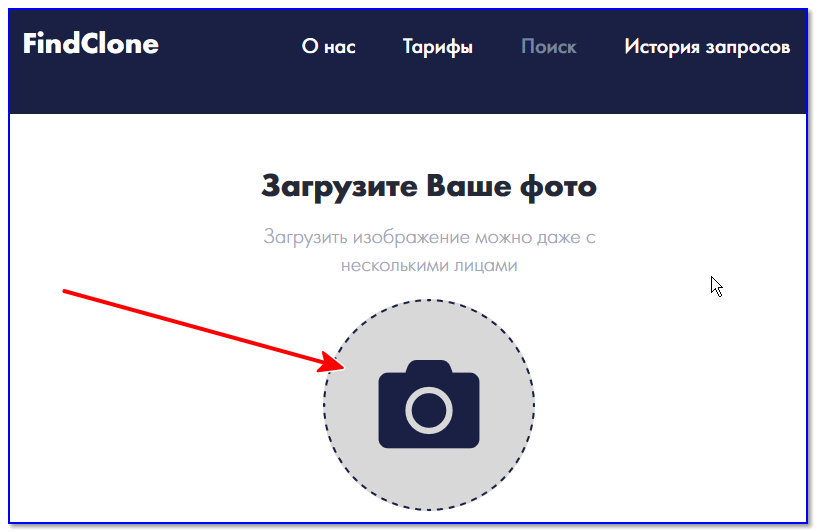 Спустя годы, в 1991 году, Пентленд и
Терк представил PCA для распознавания лиц и предложил новый метод, названный
eigenface, часто используемый в современных исследованиях по распознаванию лиц. Его основной
идея состоит в том, чтобы извлечь наиболее важную информацию из изображений лиц и
создайте подпространство, называемое пространством признаков.Размерность функции
пространство должно быть намного меньше, чем у оригинальных изображений, но компоненты
используемые при распознавании лиц, сохраняются. Набор изображений, использованный для создания этого
подпространство называется обучающим набором, а набор изображений, отражающий
компонентов в подпространстве называется собственной гранью. После создания этого
подпространство, этап проверки выполняется путем проецирования тестового изображения
на пространство, генерируя новое изображение и проверяя сходство между
это новое изображение и исходное.
Спустя годы, в 1991 году, Пентленд и
Терк представил PCA для распознавания лиц и предложил новый метод, названный
eigenface, часто используемый в современных исследованиях по распознаванию лиц. Его основной
идея состоит в том, чтобы извлечь наиболее важную информацию из изображений лиц и
создайте подпространство, называемое пространством признаков.Размерность функции
пространство должно быть намного меньше, чем у оригинальных изображений, но компоненты
используемые при распознавании лиц, сохраняются. Набор изображений, использованный для создания этого
подпространство называется обучающим набором, а набор изображений, отражающий
компонентов в подпространстве называется собственной гранью. После создания этого
подпространство, этап проверки выполняется путем проецирования тестового изображения
на пространство, генерируя новое изображение и проверяя сходство между
это новое изображение и исходное.
В уравнениях (12) и
(13), M обозначает размерность элемента
подпространство, U k , k = 1, 2, …, M — собственные грани, ω означает среднее лицо.
показан набор собственные грани, сгенерированные из обучающего набора данных, который содержит около 200 картинки.
показывает 3 пары изображения, содержащие исходное и изображение, созданное после проецируется в подпространство. Поскольку изображения обучающего набора данных имеют один и тот же человек, поэтому проецируемые изображения относительно похожи на оригинал те.
X′=∑k=0MωkUk,k=1,2,…,M
(12)
ωk=UkT(X−φ),k=1,2,…,M
(13)
Исходные изображения и проецируемые изображения [49].Проверка
На этапе проверки исходное входное изображение сравнивается с его проекция подпространства признаков. Существует множество подходов к расчет подобия и правильный выбор подхода могут привести к лучшему Результаты.
Как объяснялось, изображения представлены в виде матрицы. Это означает, что проверка становится задачей сравнения подобия двух матриц или векторы.Это можно сделать статистическими методами.
Популярные меры расстояния, такие как евклидово расстояние, манхэттенское расстояние,
Расстояние Чебышева и расстояние Минковского хорошо подходят для этой задачи. Каждая мера расстояния имеет свои преимущества и недостатки, поэтому выберите
подходящая мера для проблемы важна.
Каждая мера расстояния имеет свои преимущества и недостатки, поэтому выберите
подходящая мера для проблемы важна.
Каркасная модель
В этом разделе мы представляем и обсуждаем систему распознавания лиц с помощью PCA. (). Рамки описывает весь процесс распознавания лиц и для каждой фазы процесса представлены некоторые возможные варианты, так что подходы к распознаванию лиц могут быть адаптированы к различным случаям, и разработчикам программного обеспечения оказывается помощь, когда настройки своих приложений.Рамки учитывают лицо распознавание в экстремальных ситуациях, таких как неравномерное освещение, преувеличенное выражение лица, угол съемки изображений и тип данных изображения. В В дополнение к опциям, включенным в структуру, мы также предлагаем другие потенциальные подходы. Структура описана ниже.
Для этапа представления лица мы обсудим подходы Gabor
вейвлет, выражение PCA, выражение формы и текстуры. Кроме того, для
шаг обнаружения лица, мы поговорим о статистической модели, нейронных сетях и
методы, основанные на цвете. Для предварительной обработки мы учитываем разделение граней и локальные
двоичный шаблон (LBP). Наконец, для шага PCA, который является основным, мы
поговорим о Kernel PCA и стандартном PCA.
Для предварительной обработки мы учитываем разделение граней и локальные
двоичный шаблон (LBP). Наконец, для шага PCA, который является основным, мы
поговорим о Kernel PCA и стандартном PCA.
Структура может быть представлена в виде диаграммы функций, как показано на , где каждый из шагов
процесс предполагает другую технику. Выбор функций дает разные
вариации для каждого шага процесса распознавания лиц, каждый со своими собственными
выгода и подходящая ситуация. Сочетание этих вариаций позволяет
фреймворк для предоставления минимум 108 экземпляров приложения: три варианта
для шагов распознавания лиц, обнаружения лиц и проверки; и два
вариации для этапов предварительной обработки и PCA.Однако фактическое количество
возможные экземпляры приложения, которые могут быть захвачены нашей структурой,
значительно выше 108, так как в реальности некоторые вариации можно комбинировать
(на одном шаге), пропустить или сотрудничать с другими простыми
математические операции. В результате консервативная оценка числа
число экземпляров приложения, захваченных нашей структурой, превышает 150. Хотя эти
экземпляры не охватывают все возможные ситуации для распознавания лиц, наши
framework оказывает большую помощь разработчикам программного обеспечения.
Хотя эти
экземпляры не охватывают все возможные ситуации для распознавания лиц, наши
framework оказывает большую помощь разработчикам программного обеспечения.
Платформа в виде функциональной диаграммы.
Представление изображения
В качестве первого шага обработки распознавания лиц воспроизводится представление изображения важную роль не только в явном представлении информации об изображении но и в уменьшении шума и сжатии данных. Надлежащий выбор подходы к представлению изображений облегчают более поздние шаги и улучшают общая производительность всей системы. В этом разделе мы представляем три различные варианты представления изображений, такие как Gabor Wavelet, PCA Сжатие, форма и текстура, как показано на рис.
Вейвлет Габора . Методы обработки изображений в основном делятся
на две категории: анализ в пространственной области и анализ в частотной области.
анализ. Анализ пространственной области напрямую обрабатывает матрицу изображения;
однако подходы частотной области преобразуют изображение из пространственного
области в частотную область, а затем анализировать функцию изображения из
другая перспектива.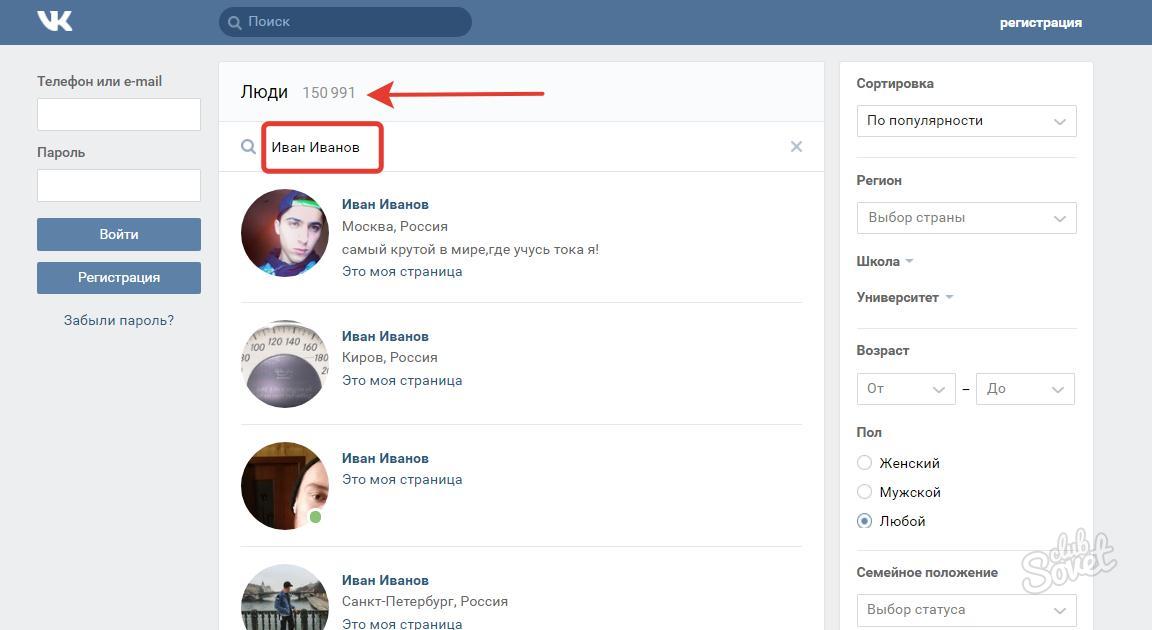 Анализ пространственной области широко используется в изображениях.
усиление, реконструкция изображения и сжатие изображения [44].
Анализ пространственной области широко используется в изображениях.
усиление, реконструкция изображения и сжатие изображения [44].
Преобразование Фурье — один из самых ранних методов передачи сигналов из пространственной области в частотную область, как показано в уравнении (14). После Обрабатывая сигнал, обратное преобразование может передать сигнал обратно в пространственную область с помощью уравнения (15).
F(ω)=∫−infinff(t)e−jωtdt=F[f(t)]
(14)
f(t)=12π∫−infinfF(ω)e−jωtdω=F−1 [f(t)]
(15)
Классическое преобразование Фурье предоставляет мощный инструмент для обработки изображений; однако он способен отражать только интегральные признаки сигналов, что означает, что ему не хватает возможности проводить локальный анализ.
Основываясь на преобразовании Фурье, Деннис Габор предложил новое преобразование, которое только зависит от части сигнала и может извлекать локальную информацию [50].
Основная идея преобразования Габора состоит в том, чтобы разделить сигнал на несколько
интервалы, а затем анализировать каждый интервал с помощью преобразования Фурье, чтобы
можно получить частоту в определенном интервале.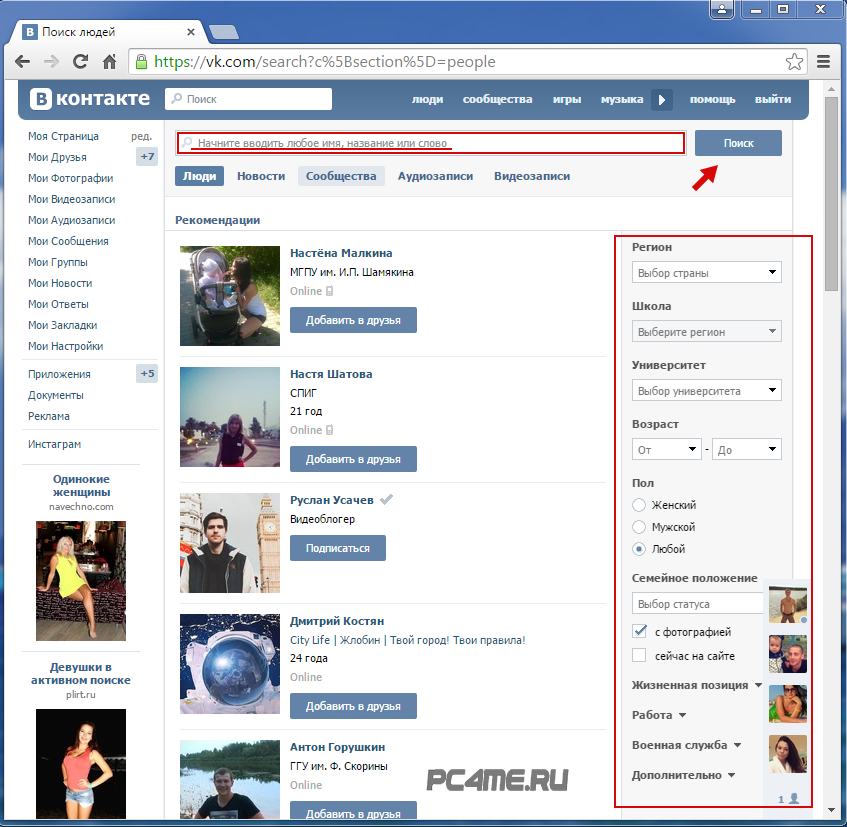 При обработке изображений
Преобразование Габора также известно как вейвлет Габора.
При обработке изображений
Преобразование Габора также известно как вейвлет Габора.
Вейвлет Габора подобен стимуляции простой клетки в организме человека зрительная система существа [51].Он фиксирует важные визуальные свойства, такие как пространственное локализация, избирательность ориентации и пространственная частота. Более того, поскольку вейвлет Габора нечувствителен к изменению освещенности, он обеспечивает хорошее адаптивность к изменению освещения в представлении изображения.
Вейвлет Габора особенно подходит для разложения изображений и представление, когда целью является выведение локальных и различающих Особенности. В 1999 г. Донейт и соавт. [52] показали, что фильтр Габора представление имело лучшую производительность для классификации лицевых движений.В 2003, Лю и др. [53] представил независимый метод признаков Габора для распознавания лиц. То метод достиг 98,5% правильной точности распознавания лиц в наборе данных FERET, и 100% точность набора данных ORL.
Сжатие PCA .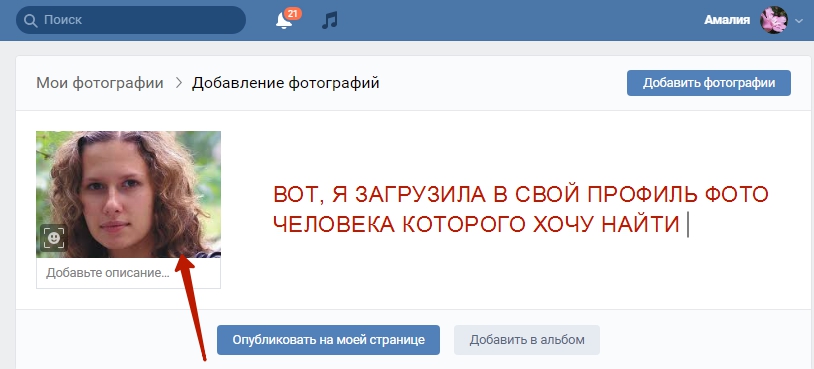 Ядро этого исследования состоит в том, что PCA является основным
шаг системы распознавания лиц, которую мы обсуждаем. Однако также может быть
используется в качестве метода представления изображения при объединении с другими распознающими
подходит. При представлении изображения лица с помощью PCA основная идея состоит в том, чтобы
перевести исходное изображение в формат с меньшими размерами, т.е.е., к
представлены меньшим числом параметров.
Ядро этого исследования состоит в том, что PCA является основным
шаг системы распознавания лиц, которую мы обсуждаем. Однако также может быть
используется в качестве метода представления изображения при объединении с другими распознающими
подходит. При представлении изображения лица с помощью PCA основная идея состоит в том, чтобы
перевести исходное изображение в формат с меньшими размерами, т.е.е., к
представлены меньшим числом параметров.
PCA был впервые применен в области распознавания образов в 1965 году Ватанабэ.
[54]. В 1990 г.
Кирби и др. представил метод распознавания лиц, в частности
характеристика человеческих лиц [55]. В работе вводится понятие
оптимальная система координат, в которой множество базисных векторов, составляющих
система называется собственными изображениями. Они на самом деле
собственные функции ковариационной матрицы ансамбля граней.Для
оценка процедуры, изображения лиц вне набора данных
проецируется на множество оптимальных базисных векторов. Результат показывает 3,68%
частота ошибок из более чем десяти изображений лиц, которые доминировали в этой области на
время.
По мере развития технологии распознавания лиц некоторые варианты Был изобретен метод представления изображений на основе PCA. Кроме того, Представление изображений на основе PCA всегда сочетается с другими средствами распознавания. подходы для достижения большей точности распознавания.
В 2005 г. Zhang et al. предложил двунаправленный двухмерный PCA для лица представление и узнавание [56]. Доказано, что 2DPCA превосходит стандартный PCA по точности распознавания. Тем не менее, 2DPCA требует больше коэффициентов для представления изображения, чем PCA. Таким образом, Даоцян и Чжи-Хуа одновременно проводят PCA в направлениях строк и столбцов, что приводит к такой же или даже более высокой точности распознавания, чем 2DPCA, хотя с меньшим количеством необходимых коэффициентов.
Выражение формы и текстуры .Выражение формы и текстуры
методы представляют человеческие лица с помощью геометрических элементов. Так как цвет лица или
освещение не учитывается в выражении формы и фактуры
расчетов количество шума, влияющего на точность распознавания,
уменьшенный. На самом деле методы, основанные на форме и текстуре, были независимыми.
изначально. Доказав, что метод, основанный на форме, не может полностью решить
проблема, вызванная выражением, масштабом и освещением, текстура
введено в сочетании с формой для достижения большей точности распознавания
[56].
На самом деле методы, основанные на форме и текстуре, были независимыми.
изначально. Доказав, что метод, основанный на форме, не может полностью решить
проблема, вызванная выражением, масштабом и освещением, текстура
введено в сочетании с формой для достижения большей точности распознавания
[56].
Статья Лю и др. в 2001 г. [57] четко объясняет рабочий процесс на основе формы и текстуры. приемы выражения лица. Мы используем некоторые рисунки и пояснения, чтобы подробно продемонстрируйте принцип.
Форма изображения лица отражает контуры лица, поэтому набор контрольных
точки, полученные с помощью ручной аннотации, используются для описания контура. К
подчеркивают особенности формы лица, эти точки игнорируют другие черты лица.
информация, такая как цвет, шкала серого. Они отображают только характерные точки, такие как
брови, глаза, нос, рот и контур лица.Как правило, форма
изображение генерируется из большого набора обучающих изображений. После получения
форма из каждого тренировочного изображения, формы выравниваются путем вращения,
перевод и масштабирование преобразований.
Сначала вычислите среднее значение выровненных форм обучающих изображений, чтобы получить изображение средней формы. Затем деформируйте нормализованное (бесформенное) лицо. изображение к средней форме, чтобы создать новое изображение, которое является текстурой. То Преобразование деформации в основном разделяло изображение на несколько небольших треугольные области, а затем выполнили аффинное преобразование на каждой из них чтобы деформировать исходное лицо до средней формы.Эти два шага приводят к текстура (бесформенное изображение), которая имеет тот же контур лица, что и среднее форма.
Экспериментальный результат работы Лю и др. показывает, что интегральная форма а особенности текстуры захватывают наиболее важную информацию о лице, что способствует их высокой точности распознавания. Помимо своей работы, другие исследования [58–60] продемонстрировать преимущества использования метода формы и текстуры для представления изображение лица.
Обнаружение лиц
Обнаружение лиц определяет область изображения, содержащую лицо, которое будет
использоваться в течение всего процесса распознавания.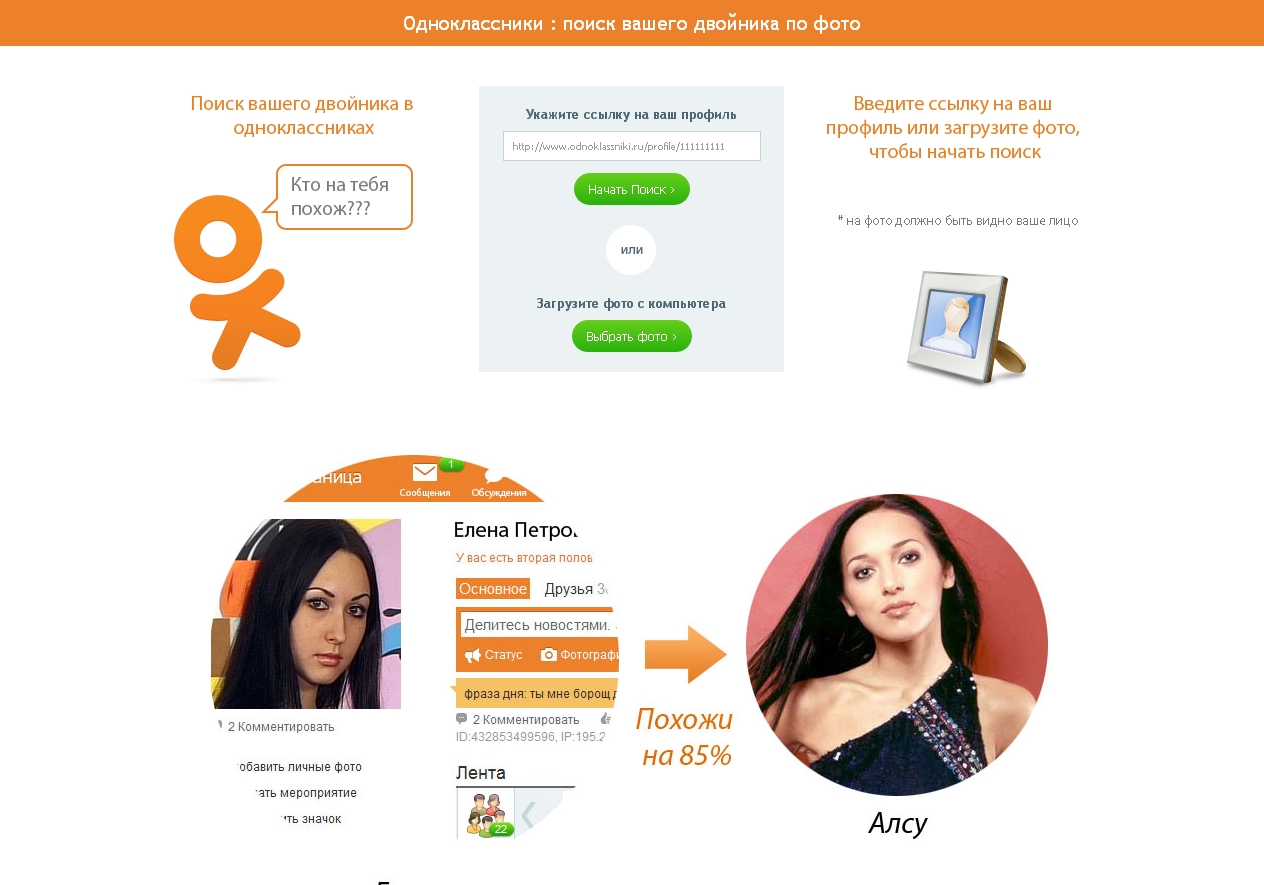 Точность этого обнаружения
оказывает большое влияние на конечный результат, так как наличие фонового шума
влияет на большинство алгоритмов распознавания лиц. Для этого этапа мы предоставляем
три варианта: статистическая модель, нейронная сеть и
цветовой метод, как показано на рис.
Точность этого обнаружения
оказывает большое влияние на конечный результат, так как наличие фонового шума
влияет на большинство алгоритмов распознавания лиц. Для этого этапа мы предоставляем
три варианта: статистическая модель, нейронная сеть и
цветовой метод, как показано на рис.
Статистическая модель . Сложность изображений человеческого лица делает обнаружение черт лица затруднено, поэтому основано на статистике методы обнаружения привлекают внимание исследователей.Этот метод рассматривает область лица как тип узора, также известный как элемент узора, и использует большое количество изображений лица и изображения без лица для обучения и создать классификатор. Таким образом, чем больше обучается метод обнаружения, тем крепче он будет.
Методы на основе пространственных признаков, такие как PCA, LDA, вероятностные модели
методы и методы на основе машины опорных векторов (SVM) относятся к
статистические методы обнаружения. Собственно, методы на основе нейронных сетей,
которые обсуждаются далее, также используют статистические принципы; однако мы
объяснить его индивидуально из-за некоторых его особенностей.
В 2000 г. Schneiderman et al. [61] предложили статистический метод для обнаружения 3D-объектов. То метод использует произведение гистограмм и обнаруживает как внешний вид объекта, так и «беспредметный» внешний вид. Каждая гистограмма представляет совместную статистику подмножество вейвлет-коэффициентов и их положение на объекте. Многие из такие гистограммы используются подходом, и они представляют большое разнообразие визуальных атрибутов. Результат демонстрирует точность обнаружения.
В 1997 г. Moghaddam et al.предложил вероятностное визуальное обучение для объекта представление, основанное на оценке плотности в многомерных пространств с помощью разложения по собственному пространству [62]. Техника была применена к не только распознавание лиц, но и распознавание жестов.
Искусственная нейронная сеть . Искусственная нейронная сеть — это
вычислительная модель, состоящая из множества нейронов, в которой каждый нейрон включает в себя
особая выходная функция, называемая функцией активации. Связь
между каждыми двумя нейронами имеет вес, который обрабатывает выходные данные
первый нейрон.
Связь
между каждыми двумя нейронами имеет вес, который обрабатывает выходные данные
первый нейрон.
Наиболее важными атрибутами искусственных нейронных сетей являются их адаптивность и параллелизм. Адаптивность дает способность учиться через обучение и самостоятельно корректировать веса в соединениях, чтобы избежать те же неисправности. Поскольку каждый нейрон в сети отвечает за определенный работа, искусственная нейронная сеть может работать параллельно, что облегчает обработку больших данных, таких как изображения.
Благодаря этим двум замечательным свойствам искусственные нейронные сети
привлекает внимание исследователей в области распознавания лиц.В 1997 году Лин
и другие. предложил метод обнаружения лиц с использованием вероятностного решения, основанного на
нейронная сеть [63].
Точность обнаружения достигает 98,34%. В 1998 году Роули и соавт. [64] представил лицо
система обнаружения, которая идентифицирует вертикальные лица с помощью нейронных сетей.
Сначала получается часть изображения, которая может содержать область лица. Затем следует ряд шагов предварительной обработки, таких как коррекция света и
нормализация гистограммы, используются с целью уменьшения шума. Ну наконец то,
нейронная сеть решает, существует ли лицо.Отчет о результатах
точность распознавания лиц от 77,9% до 90,3% при использовании набора из 130 тестов
изображений с приемлемым количеством ложных срабатываний.
Затем следует ряд шагов предварительной обработки, таких как коррекция света и
нормализация гистограммы, используются с целью уменьшения шума. Ну наконец то,
нейронная сеть решает, существует ли лицо.Отчет о результатах
точность распознавания лиц от 77,9% до 90,3% при использовании набора из 130 тестов
изображений с приемлемым количеством ложных срабатываний.
Цветовые методы . Традиционные подходы к обнаружению лиц всегда выполняются в полутоновом пространстве, где серая шкала является только та информация, которую можно зафиксировать. Более того, поскольку нет предела площадь или пропорция, необходимо искать все пространство, которое довольно трудоемкий. Однако, если информация о цвете может быть введена, область поиска будет сужена, т.к. цвет кожи наиболее прямая информация о человеческом лице.Кроме того, на лице преобладает цвет кожи.
Проблемой, которую необходимо учитывать, является разница в цвете кожи.
К счастью, исследования в этой области показывают, что цвет кожи определенного цвета
пространственные агрегаты, особенно при исключении фактора освещенности [65]. Поэтому, используя
цвет кожи как ключ к исключению любой области, которая не является кожей, может быть легко
выполненный.
Поэтому, используя
цвет кожи как ключ к исключению любой области, которая не является кожей, может быть легко
выполненный.
Применительно к распознаванию лиц информация о цвете кожи всегда используется в три разных этапа распознавания лиц.Его можно использовать в качестве основного функция, метод предварительной обработки или пост-проверка. Например, в 2002 г. Sahbi et al. предложил подход по цвету кожи для распознавания лиц в сочетании с сегментацией изображений 2002. В их подходе изображения сначала грубо разделены, чтобы обеспечить области однородного статистического цвета распределение. Затем цветовое распределение будет использоваться для обучения нейрона. сети для распознавания лиц. Результат эксперимента показывает точность около 90%.
Предварительная обработка
Этап предварительной обработки можно рассматривать как фильтр, уменьшающий основной шум
влияет на следующий процесс распознавания.Она направлена на создание четких
изображения с сохраненной полезной информацией. В этом разделе представлены два
подходы предварительной обработки: разделение лиц и LBP (). Первый обрабатывает изображения лиц
с преувеличенными выражениями, а второй имеет дело с неоднородными
освещение.
В этом разделе представлены два
подходы предварительной обработки: разделение лиц и LBP (). Первый обрабатывает изображения лиц
с преувеличенными выражениями, а второй имеет дело с неоднородными
освещение.
Разделение лиц . При съемке ожидается, что у людей будет мимика, и хорошая система распознавания лиц должны хорошо работать в этих условиях. Однако большинство систем не ждите преувеличенной мимики, а наличие оных выражения влияют на процесс распознавания, особенно для обнаружения признаков и выравнивание изображения.Чтобы смягчить эту проблему, этот метод предварительной обработки делит изображение лица на четыре части: глаза, нос, рот и весь лицо. Это позволяет системе выполнять следующие шаги для каждой детали, как Показано в .
В 2013 г. Peng et al. используется разделение граней для стандартной грани на основе PCA
расчет распознавания [49]. Они применяли PCA на каждой упомянутой части лица.
ранее и интегрировали результаты с помощью уравнения (16). Обратите внимание, что в уравнении (16) δ F относится к баллу
все лицо, δ M относится к
оценка рта, δ N относится
на счет носа, и δ E относится к баллу
глаза.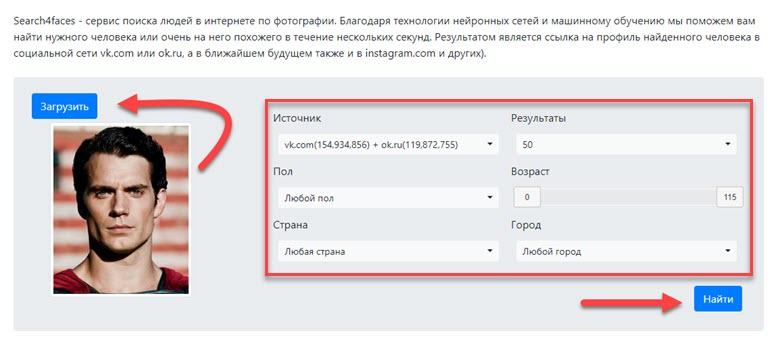 Веса, присвоенные каждой части, получены в результате экспериментов.
Результат показывает значительный прогресс в распознавании изображений лиц с помощью
преувеличенные выражения.
Веса, присвоенные каждой части, получены в результате экспериментов.
Результат показывает значительный прогресс в распознавании изображений лиц с помощью
преувеличенные выражения.
δ=0,40×δF+0,10×δM+0,100×δN+0,40×δE
(16)
Локальный двоичный код . Локальный бинарный паттерн (LBP) был
представленный He et al. в 1990 г. [66]. Проще говоря, его цель состоит в том, чтобы
вычислить взвешенную сумму для одного пикселя с соседними пикселями.
Как правило, размер окна суммы устанавливается равным 3 × 3. Он по-прежнему создает
бинарное представление изображения.LBP перемещает изображение, используя каждый пиксель
в качестве центральной точки и выполняет расчет для всех восьми
соседние пиксели. Если пиксель имеет значение серого меньше, чем значение серого
центральная точка, LBP присваивает этому пикселю нулевое значение; в противном случае это
присваивает единицу, как показано в уравнении (17) и , где я ( з я )
представляет соседние пиксели, и I ( Z 0 ) представляет центр
пиксель. дает
обзор процесса назначения.Веса, присвоенные каждому пикселю,
всегда разные.
показывает одно возможное распределение веса. показывает изображение, которое обрабатывается
по ЛБП.
дает
обзор процесса назначения.Веса, присвоенные каждому пикселю,
всегда разные.
показывает одно возможное распределение веса. показывает изображение, которое обрабатывается
по ЛБП.
f(I(Z0),I(Zi))={0,if(I(Zi)−I(Z0)>0)1,if(I(Zi)−I(Z0)<0),i =1,2,3,…,8
(17)
LBP обычно хорошо работает при классификации изображений. Так как вычисление относительно простой, он также эффективен в большинстве случаев. Однако некоторые следует упомянуть такие ограничения, как низкая расширяемость и масштабируемость.
После десяти лет исследований некоторые варианты алгоритма LBP были
частично преодолеть эти ограничения.В 2002 г. Ojala et al. [67], использовал циркулярный
окрестность с произвольным радиусом вместо окна 3×3 (). В 2010 году Тан и др.
др. [68], предложено
Local Ternary Patterns (LTP) — основанный на LBP метод, который сравнивает значения
соседние пиксели со значением центрального пикселя плюс значение диапазона т . Как следствие, восемь соседних значений могут быть
закодировано. показывает
этот процесс. Помимо этих вариаций, исследователи также комбинировали LBP с
другие алгоритмы для повышения эффективности.
показывает
этот процесс. Помимо этих вариаций, исследователи также комбинировали LBP с
другие алгоритмы для повышения эффективности.
PCA
В этом разделе мы обсудим основной этап распознавания лиц на основе PCA. фреймворк: PCA.Предусмотрены и показаны два варианта: стандартный PCA, в основном используется для данных линейного изображения, а PCA ядра используется для нелинейного изображения. данные.
Стандартный PCA . Анализ главных компонентов (PCA) обычно используется для уменьшения размеров набора данных с минимальной потерей Информация. Здесь весь набор данных с размерами d равен проецируется на новое подпространство с k измерениями, где к ≪ д .
Стандартный подход PCA можно свести к следующим шести шагам [69]:
Вычислить матрицу ковариации, d-мерный набор данных X.
Вычислить собственные векторы и собственные значения набора данных.
Отсортируйте эти собственные значения по убыванию.
Выберите k собственных векторов, соответствующих k наибольшему собственные значения, где k — количество размерностей нового подпространство признаков.
Построить матрицу проекций W из k выбранных собственные векторы.
Преобразование исходного набора данных X для получения k-мерного подпространство признаков Y.

Рис. – пример использование PCA на трехмерном наборе данных. показывает исходный набор данных. Два категории данных смешаны друг с другом и их трудно классифицировать. изображает собственные значения и собственные векторы исходного набора данных. После обработки по PCA размерность снижается до 2 и классификация четче, как показано на .
Собственные значения и собственные векторы [69]. Классификация с использованием стандартного PCA [69]. Терк и Пентланд впервые применили PCA для распознавания лиц в 1991 году [30].Мы представили
основные принципы из предыдущих разделов. Хотя PCA был исследован
на протяжении десятилетий многие до сих пор предпочитают его для задач распознавания лиц из-за его
надежность, расширяемость и простота объединения с другими существующими
методы.
Хотя PCA был исследован
на протяжении десятилетий многие до сих пор предпочитают его для задач распознавания лиц из-за его
надежность, расширяемость и простота объединения с другими существующими
методы.
Ядро PCA . Ядро PCA является расширением алгоритма PCA. который использует методы ядерных методов. Он начинается с сопоставления ввода пространство в пространство признаков с помощью нелинейного отображения, а затем переходит к вычисление главных компонент в этом пространстве признаков.
Стандартный PCA хорошо работает, когда данные линейно разделимы. Однако в на практике это обычно не так из-за воздействия внешних факторы на данные изображения, такие как угол съемки, освещение и другие типы шума. Это показывает необходимость метода, который обрабатывает нелинейные случаи. А сравнение между линейными данными и нелинейными данными показано на рис.
Линейный (слева) и нелинейный (справа) типы данных [69].Реализация Kernel PCA состоит из 2 основных этапов:
Вычисление матрицы ядра (подобия).
Собственные числа разлагают матрицу ядра.
Рис. – пример использование стандартного PCA и ядра PCA с радиальной базисной функцией Гаусса (RBF) на нелинейном наборе данных. Распределение данных показано на рис. Инжир и являются соответствующими Результаты. Хорошо видно, что проекция через PCA ядра RBF произвела подпространство, в котором классы хорошо разделены.
Стандартный результат PCA [69].Проверка
показывает три измерения, которые мы вводим для заключительного шага проверки.Методы в этот шаг — просто математические формулы, связанные с матричными операциями, так как шаг проверки на самом деле заключается в сравнении результатов предыдущих шагов представить в виде матрицы. Три метода корреляции, Махаланобиса расстояние и евклидово расстояние.
Корреляция . Таблица или график статистической корреляции могут
описать отношение и направление отношения между двумя переменными, с
исключением степени корреляции. Чтобы решить эту проблему, Карл Персон,
статистик предложил новый коэффициент корреляции.В целом,
коэффициенты корреляции делятся на простые, множественные и классические.
корреляция. Здесь мы обсуждаем только простую корреляцию.
Чтобы решить эту проблему, Карл Персон,
статистик предложил новый коэффициент корреляции.В целом,
коэффициенты корреляции делятся на простые, множественные и классические.
корреляция. Здесь мы обсуждаем только простую корреляцию.
Корреляция двух переменных X и X ′ рассчитывается, как показано в уравнении (18).
δ(X,X′)=E(XX′)−E(X)E(X′)σ(X)σ(X′)
(18)
Где E ( X ) относится к ожиданию переменная X и σ ( X ) относится к дисперсии X .
Расчет коэффициента корреляции имеет низкую вычислительную мощность сложности, но результат зависит от количества образцов. Для малое количество образцов, результат значительно колеблется при добавлении нового образца; то же самое не верно для большого количества образцов.
Расстояние Махаланобиса . П. К. Махаланобис является создателем
Расстояние Махаланобиса, которое выражает ковариационное расстояние данных.
По сравнению с другими родственными измерениями расстояние Махаланобиса занимает
учитывать взаимосвязь между различными признаками. Одно преимущество этого
расстояние над другими является его масштабно-инвариантным свойством, что означает, что он может
убрать интерференцию между переменными. Уравнение (19) показывает, как рассчитать
Расстояние Махаланобиса двух векторов.
Одно преимущество этого
расстояние над другими является его масштабно-инвариантным свойством, что означает, что он может
убрать интерференцию между переменными. Уравнение (19) показывает, как рассчитать
Расстояние Махаланобиса двух векторов.
D(Xi,Xj)=(Xi-Xj)TS-1(Xi-Xj)
(19)
Где S представляет ковариационная матрица.
Самый существенный недостаток расстояния Махаланобиса заключается в том, что оно может преувеличивать влияние переменной с небольшой вариацией.
Евклидово расстояние .Евклидово расстояние очень популярно. метрика расстояния в статистике. Он представляет собой расстояние двух векторов в космос. В двумерном пространстве евклидово расстояние рассчитывается как показано в уравнении (20).
O(ρ)=(x1−x2)2+(y1−y2)2
(20)
При расширении до n-мерного
пространство, евклидово расстояние вектора а ( х 11, х 12, …, X 1 n ) и еще один вектор б ( Х 21, Х 22, …, X 2 n ) рассчитывается, как показано в уравнении (21).