не работает VK
«Люди, события, факты» — вы делаете те новости, которые происходят вокруг нас. А мы о них говорим. Это рубрика о самых актуальных событиях. Интересные сюжеты и горячие репортажи, нескучные интервью и яркие мнения.
События внутренней, внешней и международной политики, политические интриги и тайны, невидимые рычаги принятия публичных решений, закулисье переговоров, аналитика по произошедшим событиям и прогнозы на ближайшее будущее и перспективные тенденции, публичные лица мировой политики и их «серые кардиналы», заговоры против России и разоблачения отечественной «пятой колонны» – всё это и многое вы найдёте в материалах отдела политики Царьграда.
Идеологический отдел Царьграда – это фабрика русских смыслов. Мы не раскрываем подковёрные интриги, не «изобретаем велосипеды» и не «открываем Америку».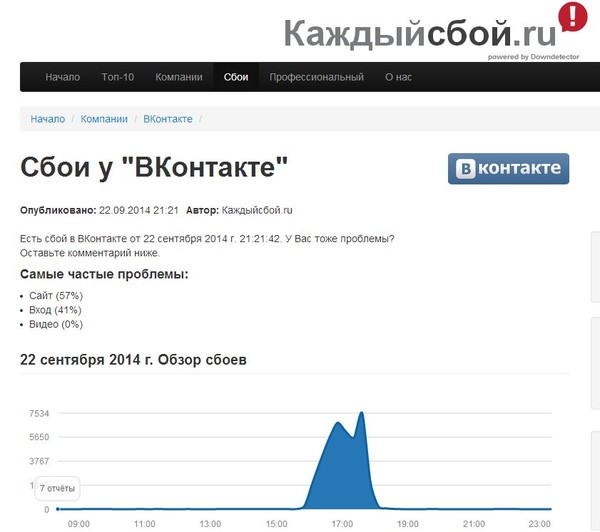
Расследования Царьграда – плод совместной работы группы аналитиков и экспертов. Мы вскрываем механизм работы олигархических корпораций, анатомию подготовки цветных революций, структуру преступных этнических группировок. Мы обнажаем неприглядные факты и показываем опасные тенденции, не даём покоя прокуратуре и следственным органам, губернаторам и «авторитетам». Мы защищаем Россию не просто словом, а свидетельствами и документами.
Экономический отдел телеканала «Царьград» является единственным среди всех крупных СМИ, который отвергает либерально-монетаристские принципы.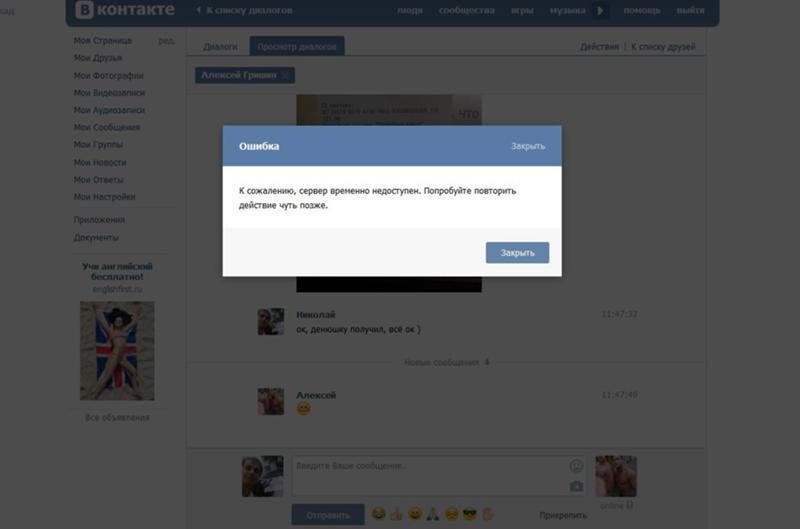 Мы являемся противниками встраивания России в глобалисткую систему мироустройства, выступаем за экономический суверенитет и независимость нашего государства.
Мы являемся противниками встраивания России в глобалисткую систему мироустройства, выступаем за экономический суверенитет и независимость нашего государства.
Не работает VK Coin — что делать?
Автор Евгений На чтение 4 мин Опубликовано Обновлено
С момента запуска ВК коин прошло 5 дней, но уже набралось рекордное количество посетителей, которые просто сносят сайт. Заманчивое предложение «Стань самым богатым в контакте» коснулось очень многих, все хотят себе, как можно больше коинов. Для чего они нужны и как их зарабатывать мы рассказывали в этой статье ссылка. В связи с большой активностью постоянно лагает и может не заходить на сайт, не работать приложение. Мы расскажем вам, как поступать в такой ситуации. Давайте разберемся, что делать если VK Coin не запускается или вовсе не поддерживаться на вашем устройстве.
В чем проблема?
При переходе на свою страницу она не грузится ни с компьютера, ни с телефона. На экране появляется грустный смаил как на картинке ниже. Из – за чего же это случается? Это происходит из – за огромные количества людей, которые все время заходят на платформу и майнит. Иногда случается такой перегруз, что сайт просто не в силах справится и «слетает» на некоторое время, то есть перестает работать.
Что-то пошло не такЧто делать в такой ситуации?
- Если проблема не в вашем устройстве, то нужно просто подождать. У нас тоже такое случалось, спустя пол часа вход снова стал доступен. Это стандартные системные сбои, тем более приложение новое;
- Если неполадки в вашем смартфоне, тогда следует заняться очисткой кэша. Таким образом вы удалите все то, что захламляет вашу память и мешает другим приложениям работать.
- Посмотрите не требуется ли вашему телефону обновить версию Вконтакте. Сделать это можно в зависимости от телефона в PlayMarket, AppStore, приложения и друге.

- Просто перезайдите в приложения, иногда случаются такие небольшие глюки. Если все в норме, то не обращайте внимания на это;
- Меняем время, возможно у вас в настройках не ваш часовой пояс? Это нужно изменить или все приложения, которые есть на вашем смартфоне не смогут работать в обычном режиме. Даже если и получится, потому будет происходит множество новых ошибок.
Возможные варианты решения
Интернет-соединение
Убедитесь, что ваше устройство может подключаться к Интернету. Если он не может подключиться, приложения не будут работать.
Переустановка
Вы можете попробовать полностью удалить приложение Вконтакте, а затем переустановить из магазина Google Play. Просто откройте приложение Play Store, откройте строку меню слева и нажмите Мои приложения и игры . Найдите ВК и нажмите «Удалить» — это займет несколько секунд. После этого вы можете установить его снова.
Перезагрузка
Вы также можете просто перезагрузить ваш смартфон. Это очень простой и довольно эффективной способ, если ваш телефон был включен в течение длительного времени.
Это очень простой и довольно эффективной способ, если ваш телефон был включен в течение длительного времени.
Рекомендуется выключать телефон каждые несколько дней на несколько минут — это поможет вашему телефону с множеством проблем, связанных с запуском приложений.
Полный сброс
Если вышеуказанные решения не помогли, вы можете вернуться к заводским настройкам телефона. Выполняя сброс к заводским настройкам, убедитесь, что вы сделали резервные копии всех своих данных заранее.
Я повторяю: сначала сделайте резервную копию всех ваших данных . Сброс настроек приведет к стиранию вашего устройства и возврату к заводским настройкам по умолчанию. Вы можете легко восстановить ваши приложения и данные, если вы сделали резервную копию.
VK Coin к сожалению ваше устройство не поддерживается
Ниже приведены различные методы, которые могут помочь вам легко исправить ошибку «к сожалению ваше устройство не поддерживается».
- Зайдите в Настройки на вашем устройстве.
- Нажмите «Диспетчер приложений».
- Найдите «Google Play Store» и нажмите на то же самое.
- Нажмите на кнопку «Удалить обновления».
- Нажмите на кнопку «ОК».

Это удалит все последние обновления в Google Play Store, которые могут быть причиной ошибки.
Еще как вариант:
Просто скачайте любое приложение VPN, предпочтительно Touch VPN установите и запустите.
Заключение:
Сегодня мы рассказали о решении проблемы vk coin, что делать, если он не хочет запускаться. Надеемся, что статья была для вас полезной. Если это так, то напишите нам об этом ниже, спасибо, что читаете нас.
Почему моя модель ML не работает?
Дата публикации Sep 23, 2019
Изучая курс машинного обучения, вы легко внедряете и тестируете модели машинного обучения в курсовых проектах. Все работает хорошо Однако в реальных сценариях ваша модель просто приводит к бессмысленным результатам, и вы можете быть не уверены, в чем проблема.
Все работает хорошо Однако в реальных сценариях ваша модель просто приводит к бессмысленным результатам, и вы можете быть не уверены, в чем проблема.
В этой статье я обсуждаю три компонента, которые должны быть соизмеримы друг с другом, чтобы модель ML работала:сложность проблемы, сложность модели и размер выборки, Как специалист по обработке данных, мы несем ответственность за определение и идентификацию каждого из компонентов. Мы определяем ясную проблему, определяем модель и решаем, нужно ли нам больше данных.
В оставшейся части этой статьи я рассмотрю каждый из этих компонентов в отдельности, а затем рассмотрю различные сценарии, за которыми последуют некоторые предложения.
Сложность проблемы, сложность модели и размер выборки должны совпадать.В некоторых случаях проблема может быть неясной, и нам может потребоваться определить точную проблему самостоятельно. Это первый шаг, и хорошее начало всегда дает хороший конец. Постарайтесь определить проблему как можно проще и в то же время убедиться, что она решит бизнес-задачу.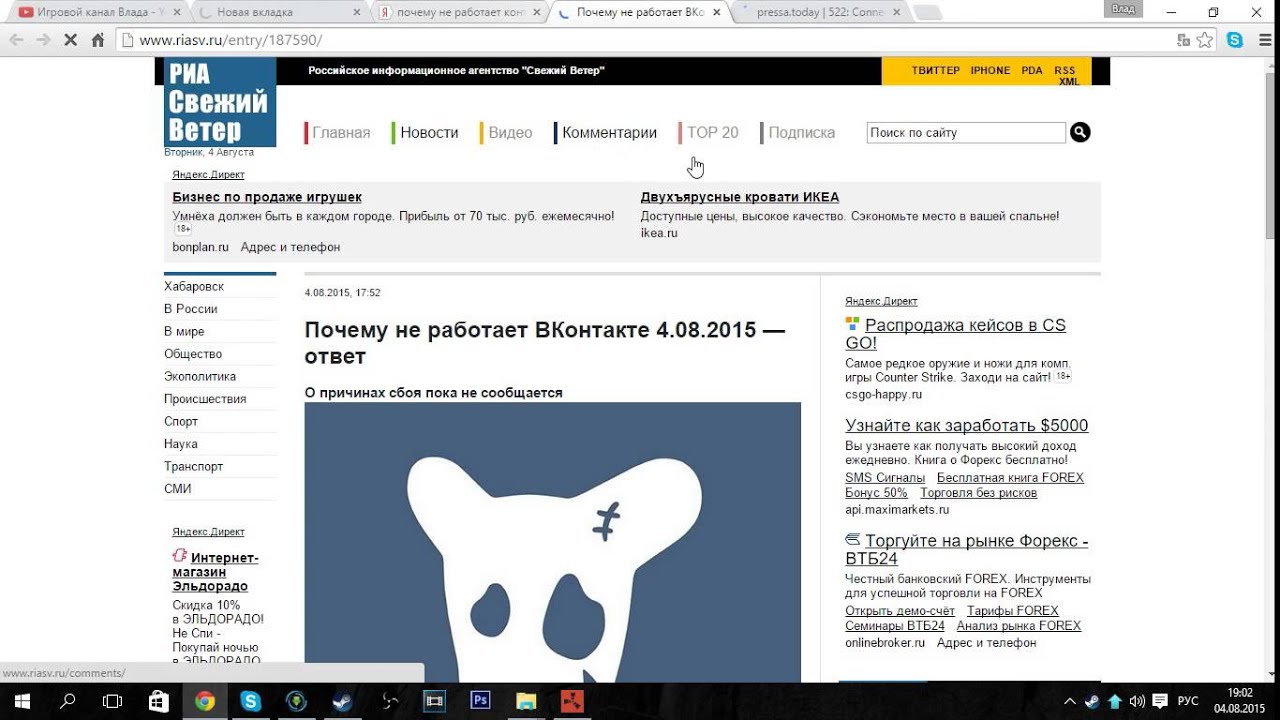 Вот два примера, чтобы прояснить обсуждение:
Вот два примера, чтобы прояснить обсуждение:
а) Предположим, вам дали проект видеонаблюдения, где камера записывает кадры комнаты. Задача состоит в том, чтобы определить, есть ли кто-то в комнате или нет. Один из подходов заключается в развертывании алгоритма обнаружения человека на видеоданных. Второй подход заключается в обнаружении любого движения в видео, поскольку вы знаете, что движение в комнате может быть вызвано только человеком. Второй подход намного проще, чем первый, и ожидается, что более простая модель даст желаемые результаты.
б) Сложность проблемы заключается в том, насколько разнообразными могут быть данные. Поэтому, если у нас меньшее количество измерений, проблема будет менее сложной.
Предположим алгоритм классификации документов, в котором вы хотите классифицировать официальные документы. Первый подход заключается в применении подхода, основанного на видении, который учитывает каждый пиксель документа. Другой подход — посмотреть на текст в документах.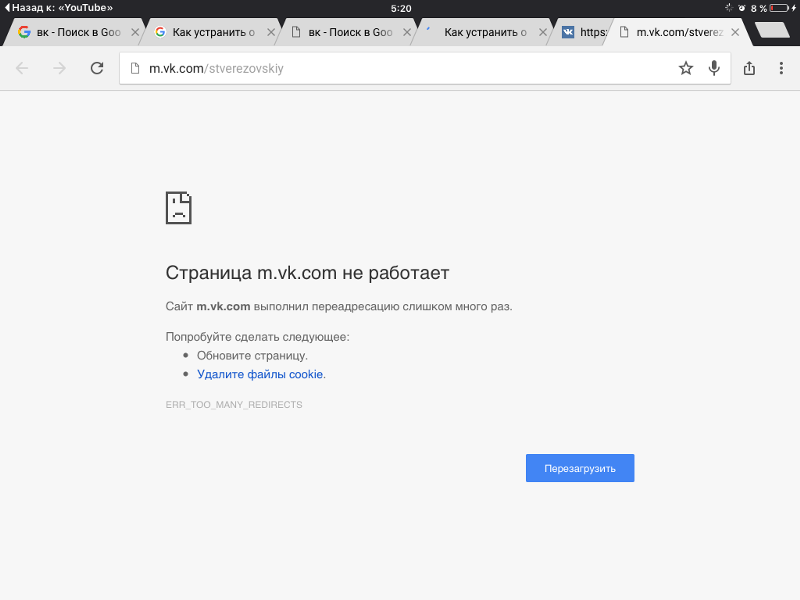 Если документы содержат другой текст, то они различимы по тексту. Сложность проблемы во втором подходе намного меньше, чем в первом подходе, потому что текст имеет меньший размер по сравнению с изображением. Низкий размер означает меньшую гибкость и меньшую сложность.
Если документы содержат другой текст, то они различимы по тексту. Сложность проблемы во втором подходе намного меньше, чем в первом подходе, потому что текст имеет меньший размер по сравнению с изображением. Низкий размер означает меньшую гибкость и меньшую сложность.
Сложность модели может быть выведена изколичество весовэто должно быть установлено на этапе обучения. Если модель включает в себя большое количество весов внутри, то она более гибкая для изучения вещей. В свою очередь, вам нужно больше данных для обучения модели.
Давайте посмотрим несколько примеров:
а) Модель глубокого обучения с 3 входами и одним скрытым слоем с десятью нейронами, имеет около 50 весов.
б) Дерево решений с глубиной 4 имеет 15 весов (пороги рассматриваются как весовые коэффициенты).
в) Модель линейной регрессии для 3 входов имеет 4 веса.
Специалисты по данным должны иметь некоторые знания о различных алгоритмах, которые он или она использует. Если вы знаете, как работает алгоритм, у вас есть представление о количестве весов и сложности алгоритма. В этом случае вам не нужно тратить время на передачу небольших данных в сложную модель.
В этом случае вам не нужно тратить время на передачу небольших данных в сложную модель.
В следующем разделе я дам несколько советов о количестве выборок, основанных на количестве весов.
Это самый важный компонент, который необходимо учитывать при разработке модели ML. Я видел много случаев, когда размер выборки слишком мал, но инженеры машинного обучения тратят время на развертывание различных моделей и параметров настройки. В некоторых случаях для обучения достаточно нескольких сотен образцов, в то время как в других модель не может учиться на тысячах образцов.
Рассматривая три компонента, теперь пришло время проверить, достаточно ли у вас данных для указанной модели ML и проблемы.
Правильное количество образцов — открытая проблема. Никто не может сказать, сколько образцов необходимо для обучения модели без анализа данных. Это основано больше на опыте. Однако очень важно иметь ощущение правильного диапазона. В середине встречи вас могут спросить о приблизительном количестве необходимых вам образцов. Ваш ответ 100, 10000 или 1000000?
Ваш ответ 100, 10000 или 1000000?
Здесь я собираюсь дать вам несколько советов по оценке правильного количества образцов.
Количество весов в модели, которые представляют сложность модели, не должно превышать количество выборок. Подумайте о простой задаче линейной регрессии, которая имеет 10 весов (9 функций), и у вас есть 8 выборок. С математической точки зрения существуют бесконечные линейные модели, которые соответствуют образцам. По моему опыту, количество образцов должно быть как минимум в десять раз больше, чем количество функций Это означает, что для обучения регрессионной модели с 10 функциями нам нужно как минимум 100 выборок. Помните, что число десять основано на опыте, и этому нет никаких доказательств, поскольку оно зависит от характеристик данных. В нашем примере, если данные имеют линейную характеристику, мы можем обучить нашу модель меньшему количеству выборок. Кроме того, если все образцы выглядят одинаково, нам нужно больше, чтобы иметь более надежную модель. Есть и другие параметры, которые влияют на правильное количество образцов. Однако, учитывая количество весов в модели, вы получите подсказку о количестве образцов, которые вам примерно необходимы.
Есть и другие параметры, которые влияют на правильное количество образцов. Однако, учитывая количество весов в модели, вы получите подсказку о количестве образцов, которые вам примерно необходимы.
Исходя из состояния каждого параметра, у нас есть 8 различных сценариев. На рисунках 1 и 2 показан пример графика для каждого сценария. Я буду обсуждать каждый сценарий отдельно.
Малый размер выборки:Если количество выборок слишком мало, лучше подумать о модели на основе правил, а не обучать модели ML. Вообще говоря, используя менее 50 образцов, мы не используем модель ML.
a) Сложность модели = низкая, сложность проблемы = низкая, размер выборки = малая: это единственный случай, когда вы можете получить значимый результат, когда у вас недостаточно данных. Если проблема не сложная, выберите простую модель и обучите ее этим образцам.
б) Сложность модели = Высокая, Сложность проблемы = Низкая, Размер выборки = Маленький: Вы должны выбрать более простую модель, поскольку сложность модели должна соответствовать сложности задачи и размеру выборки. Даже если вы получаете более высокую производительность от очень сложной модели, простая модель работает лучше для невидимых данных. Причина в том, что оценка основана только на небольшом количестве данных, которые не являются надежными, и, настраивая параметры сложной модели, вы, вероятно, превосходите модель. Простая модель была бы более надежной на практике.
Даже если вы получаете более высокую производительность от очень сложной модели, простая модель работает лучше для невидимых данных. Причина в том, что оценка основана только на небольшом количестве данных, которые не являются надежными, и, настраивая параметры сложной модели, вы, вероятно, превосходите модель. Простая модель была бы более надежной на практике.
c) Сложность модели = низкая, сложность проблемы = высокая, размер выборки = малая: если это возможно, попытайтесь решить подзадачу или более простую версию проблемы. По крайней мере, вы можете достичь значимого результата.
d) Сложность модели = высокая, сложность проблемы = высокая, размер выборки = малая: даже если вы получите высокую точность, модель потерпит неудачу в реальной ситуации при работе с невидимыми данными.
Большой размер выборки:Наличие достаточного количества образцов является ключом к созданию хорошей модели ML. Следует отметить, что образцы не должны быть смещены. В противном случае нет большой разницы между маленькими и большими размерами выборки.
e) Сложность модели = низкая, сложность проблемы = низкая, размер выборки = большой: выбор модели не является большой проблемой со сложной проблемой и большим размером выборки. Большинство моделей ML дают хороший результат.
f) Сложность модели = высокая, сложность проблемы = низкая, размер выборки = большая: сложная модель может дать несколько лучший результат по сравнению с типичной моделью. Учитывая простоту объяснения и обслуживания модели, вы можете выбрать более простую модель.
g) Сложность модели = низкая, сложность проблемы = высокая, размер выборки = большая: если вам нравится работать с самыми современными методами, это подходящий вариант для вас. Выберите сложную модель (например, глубокое обучение), и вы получите желаемый результат.
h) Сложность модели = высокая, сложность задачи = высокая, размер выборки = большая: в этом случае вы можете увидеть всю мощь и красоту машинного обучения. Волшебство здесь происходит.
То, что я написал в этой статье, основано исключительно на моем опыте работы с моделями ML. Вы никогда не найдете их в курсе или книге, потому что это качественные понятия. Все данные разные, и вы не можете сформулировать количество необходимых данных. У вас не может быть правила выбора лучшей модели без анализа данных. Однако на практике очень важно иметь приблизительное понимание каждого из трех компонентов, обсуждаемых в этой статье. Это поможет вам принять правильные меры для исправления модели ML, когда она не работает.
Вы никогда не найдете их в курсе или книге, потому что это качественные понятия. Все данные разные, и вы не можете сформулировать количество необходимых данных. У вас не может быть правила выбора лучшей модели без анализа данных. Однако на практике очень важно иметь приблизительное понимание каждого из трех компонентов, обсуждаемых в этой статье. Это поможет вам принять правильные меры для исправления модели ML, когда она не работает.
Как всегда, я очень благодарен всем, кто читает мои работы, и я надеюсь, что вам понравится это! Если у вас есть какие-либо вопросы или комментарии, не стесняйтесь оставлять свои отзывы ниже, или вы можете связаться со мной поLinkedIn,
Оригинальная статья
Mobile Legends Bang Bang не загружается: проблемы с Mobile Legends Bang Bang
Главная »Проблемы» Mobile Legends Bang Bang не загружается: проблемы с Mobile Legends Bang Bang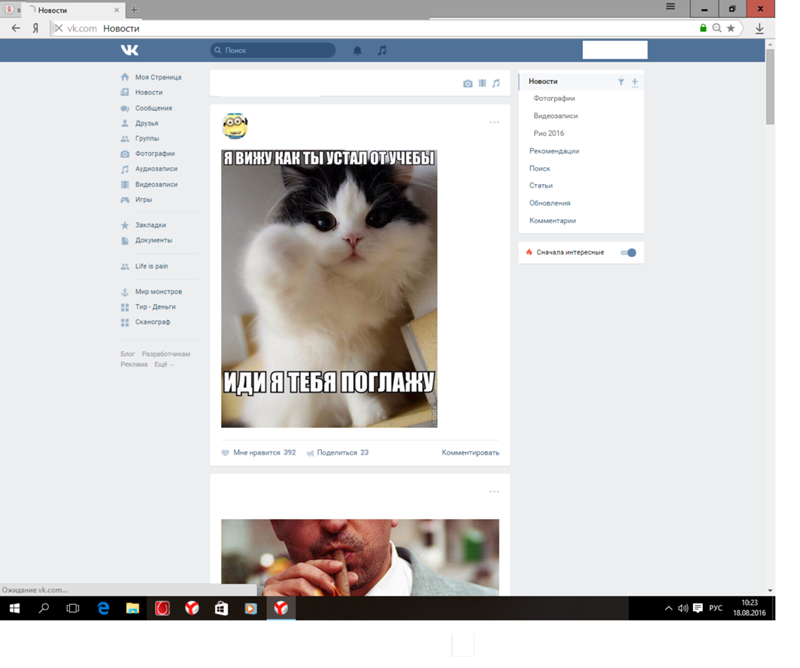
Это может сильно раздражать, когда приложение из App Store не может быть загружено и, таким образом, обновлено. Загрузка или обновление начаты, но через несколько часов загружается только часть приложения.
Между прочим, могут возникать и другие проблемы и ошибки, которые вы можете найти в обзоре всех проблем Mobile Legends Bang Bang, найденных .
Mobile Legends Bang Bang не загружается
Вы хотите загрузить или обновить Mobile Legends Bang Bang, и загрузка или загрузка приложения занимает целую вечность, потому что оно просто не загружается. Многие потом отчаянно пытаются перезапустить загрузку Mobile Legends Bang Bang, но это тоже не приводит ни к какому полезному результату.
Следующей попыткой многих будет проверка интернет-соединения. Но WLAN показывает полный прием и все равно не работает или работает очень медленно.
Mobile Legends Bang Bang загружается очень медленно
Если Mobile Legends Bang Bang загружается очень медленно, это также может быть связано с размером самого приложения. Индикатор выполнения показывает медленную загрузку, но это может появиться только из-за размера приложения. В случае обновления вы можете проверить в соответствующем магазине приложений, насколько велик установочный файл, и узнать, может ли он загружаться так долго из-за своего размера.
Mobile Legends Bang Bang Обновление не запускается
Хотите ли вы обновить Mobile Legends Bang Bang или загрузить его снова.Если одно не работает, вероятно, у вас те же проблемы с другим, и вам следует искать те же решения.
Поэтому мы собрали несколько возможных решений, чтобы вы могли без проблем загрузить приложение Mobile Legends Bang Bang.
Для того, чтобы Mobile Legends Bang Bang скачать для работы:
Мы надеемся, что следующие решения помогут вам загрузить Mobile Legends Bang Bang, и загрузка не займет много времени. Если вам известны другие возможные решения, мы с нетерпением ждем сообщения от вас в конце этой статьи.
Если вам известны другие возможные решения, мы с нетерпением ждем сообщения от вас в конце этой статьи.
- Проверьте подключение к Интернету
Причины, по которым Mobile Legends Bang Bang не может быть загружен, не могут быть более разными. В большинстве случаев это связано с вашим собственным подключением к Интернету. Вполне возможно, что ваше устройство подключено к сети Wi-Fi, но оно по-прежнему не работает, поэтому вам следует попытаться получить доступ к веб-сайту в Интернете с помощью браузера. Если все работает нормально, значит, это не ваш смартфон или планшет. Если вы попытаетесь загрузить приложение через мобильную сеть - Перезагрузите смартфон или планшет
Часто возникают проблемы с App Store после обновления операционной системы Android или iOS. После обновления системы вполне может случиться так, что соединение с данными для входа в соответствующий магазин больше не будет надежно работать.В этом случае вам следует перезагрузить смартфон или планшет, что перезагрузит все настройки и функции и, при необходимости, восстановит соединение с App Store.
Если перезапуск и рабочее интернет-соединение не помогли решить проблему, а Mobile Legends Bang Bang по-прежнему загружается медленно или не загружается вообще, то это также может быть на серверах iTunes Store для iOS или Android. на серверах Google Play Store лежат. Это не должно быть связано с серверами разработчика Moonton, поскольку приложение находится на серверах App Store, в редких случаях они могут быть перегружены или возникать сбои из-за работ по техническому обслуживанию.проверить статус сервера Apple
проверить статус сервера Google- Для Android: Очистите кеш и удалите данные в Play Store.
- Откройте на устройстве приложение « Настройки ».
- Коснитесь Приложения и уведомления , затем щелкните Просмотреть все приложения .
- Прокрутите вниз и коснитесь Google Play Store.
- Tap Память Пустой кеш .
- Затем нажмите Очистить данные .
- Снова откройте Play Store и повторите попытку загрузки.

Итак, мы надеемся, что советы и рекомендации были полезны, и загрузка Mobile Legends Bang Bang снова работает быстро и без каких-либо проблем.

Если у вас по-прежнему возникают проблемы, а Mobile Legends Bang Bang по-прежнему загружается медленно, мы с нетерпением ждем вашего ответа.
Mobile Legends Bang Bang Сообщить о проблемеАналогичные выпуски Mobile Legends Bang Bang:
Подобные сообщения:
Mobile Legends Bang Bang не загружается или работает медленно? Сообщите здесь:
Почему моя модель ML не работает ?. Подсказка: сложность модели, проблема… | by Amin Sadri
Изучая курс машинного обучения, вы легко развертываете и тестируете модели машинного обучения в курсовых проектах. Все работает хорошо. Однако в реальных сценариях ваша модель просто дает бессмысленные результаты, и вы можете не знать, в чем проблема.
В этой статье я обсуждаю три компонента, которые должны быть соизмеримы друг с другом, чтобы модель машинного обучения работала: сложность задачи , сложность модели и размер выборки . Как специалист по данным, мы несем ответственность за определение и идентификацию каждого из компонентов. Мы определяем четкую проблему, определяем модель и решаем, нужны ли нам дополнительные данные.
Мы определяем четкую проблему, определяем модель и решаем, нужны ли нам дополнительные данные.
В оставшейся части статьи я рассмотрю каждый из этих компонентов по отдельности, а затем исследую различные сценарии с последующими некоторыми предложениями.
Сложность задачи, сложность модели и размер выборки должны соответствовать.В некоторых случаях проблема может быть неясной, и нам может потребоваться определить точную проблему самостоятельно. Это первый шаг, и хорошее начало всегда делает хороший конец. Постарайтесь определить проблему как можно проще и в то же время убедитесь, что она решит бизнес-задачу. Вот два примера, чтобы прояснить обсуждение:
a) Предположим, вам дается проект видеонаблюдения, в котором камера записывает кадры комнаты.Задача — определить, есть ли кто-нибудь в комнате или нет. Один из подходов — применить алгоритм обнаружения человека к видеоданным. Второй подход — обнаружить любое движение на видео, поскольку вы знаете, что движение в комнате может быть вызвано только человеком. Второй подход намного проще первого, и ожидается, что более простая модель даст желаемые результаты.
Второй подход намного проще первого, и ожидается, что более простая модель даст желаемые результаты.
б) Сложность проблемы заключается в том, насколько разнообразными могут быть данные. Следовательно, чем меньше размерностей, тем сложнее проблема.
Предположим, алгоритм классификации документов, в котором вы хотите классифицировать официальные документы. Первый подход заключается в применении подхода, основанного на видении, который учитывает каждый пиксель документа. Другой подход — посмотреть текст в документах. Если документы содержат разный текст, они различимы по тексту. Сложность проблемы во втором подходе намного меньше, чем сложность в первом подходе, потому что текст имеет небольшую размерность по сравнению с изображением.Низкие размеры означают меньшую гибкость и меньшую сложность.
Сложность модели может быть выведена из числа весов , которые должны быть установлены на этапе обучения. Если модель включает в себя большое количество грузов, она более гибкая для изучения вещей. Взамен вам нужно больше данных для обучения модели.
Взамен вам нужно больше данных для обучения модели.
Давайте посмотрим на несколько примеров:
a) Модель глубокого обучения с 3 входами и одним скрытым слоем с десятью нейронами имеет около 50 весов.
b) Дерево решений с глубиной 4 имеет 15 весов (пороги считаются весами).
c) Модель линейной регрессии для 3 входных данных имеет 4 веса.
Специалисты по обработке данных должны иметь некоторое представление о различных алгоритмах, которые он использует. Если вы знаете, как работает алгоритм, у вас есть некоторое представление о количестве весов и сложности алгоритма. В этом случае вам не нужно будет тратить время на ввод данных в сложную модель.
В следующем разделе я дам несколько подсказок о количестве выборок в зависимости от количества весов.
Это наиболее важный компонент, который следует учитывать при разработке модели машинного обучения.Я видел много случаев, когда размер выборки слишком мал, но инженеры по машинному обучению тратят время на развертывание различных моделей и настройку параметров. В некоторых случаях для обучения достаточно нескольких сотен образцов, в то время как в других модель не может учиться на тысячах образцов.
В некоторых случаях для обучения достаточно нескольких сотен образцов, в то время как в других модель не может учиться на тысячах образцов.
Рассматривая три компонента, теперь пора проверить, достаточно ли у вас данных для указанной модели машинного обучения и проблемы.
Правильное количество образцов — открытая проблема. Никто не может сказать, сколько образцов необходимо для обучения модели, не анализируя данные.Это больше основано на опыте. Однако очень важно иметь чувство правильного диапазона. В середине встречи вас могут спросить о примерном количестве необходимых вам образцов. Ваш ответ 100, 10000 или 1000000?
Здесь я дам вам несколько советов по оценке правильного количества образцов.
Количество весов в модели, которые представляют сложность модели, не должно быть больше количества выборок. Подумайте о простой задаче линейной регрессии, которая имеет 10 весов (9 признаков) и у вас есть 8 выборок.С математической точки зрения существует бесконечное количество линейных моделей, которые соответствуют образцам. По моему опыту, количество образцов должно быть как минимум в десять раз больше, чем количество функций. Это означает, что для обучения регрессионной модели с 10 функциями нам понадобится не менее 100 образцов. Помните, что число десять основано на опыте, и для этого нет никаких доказательств, поскольку оно зависит от характеристик данных. В нашем примере, если данные имеют линейную характеристику, мы можем обучить нашу модель с меньшим количеством выборок.Кроме того, если все образцы выглядят одинаково, нам нужно больше, чтобы иметь более надежную модель. Есть также другие параметры, которые способствуют правильному количеству выборок. Однако рассмотрение количества гирь в модели дает вам подсказку о количестве образцов, которые вам примерно нужны.
По моему опыту, количество образцов должно быть как минимум в десять раз больше, чем количество функций. Это означает, что для обучения регрессионной модели с 10 функциями нам понадобится не менее 100 образцов. Помните, что число десять основано на опыте, и для этого нет никаких доказательств, поскольку оно зависит от характеристик данных. В нашем примере, если данные имеют линейную характеристику, мы можем обучить нашу модель с меньшим количеством выборок.Кроме того, если все образцы выглядят одинаково, нам нужно больше, чтобы иметь более надежную модель. Есть также другие параметры, которые способствуют правильному количеству выборок. Однако рассмотрение количества гирь в модели дает вам подсказку о количестве образцов, которые вам примерно нужны.
В зависимости от статуса каждого параметра у нас есть 8 различных сценариев. На рисунках 1 и 2 показан пример графика для каждого сценария. Я расскажу о каждом сценарии отдельно.
Маленький размер выборки: Если количество выборок слишком мало, лучше подумать о модели, основанной на правилах, а не обучать модель машинного обучения.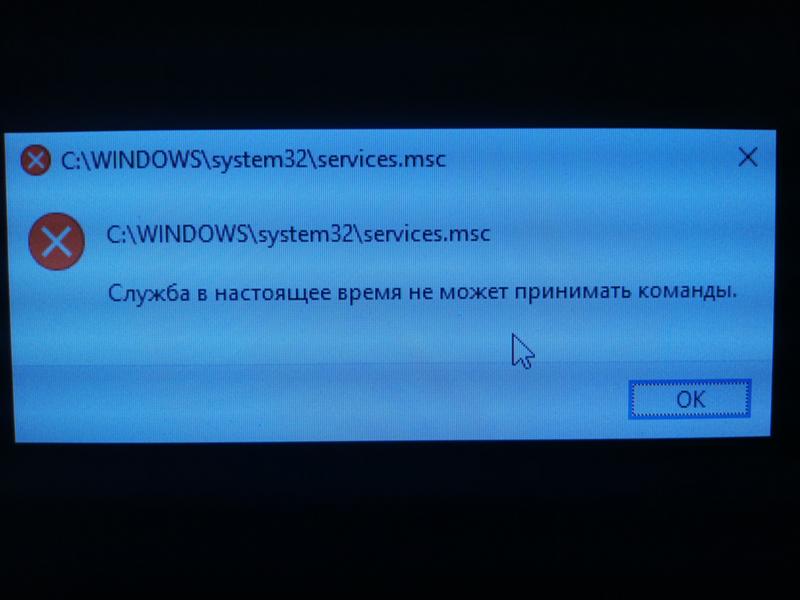 Вообще говоря, с менее чем 50 образцами мы не используем модель машинного обучения.
Вообще говоря, с менее чем 50 образцами мы не используем модель машинного обучения.
a) Сложность модели = низкая, сложность проблемы = низкая, размер выборки = небольшой: это единственный случай, когда вы можете получить значимый результат, когда у вас недостаточно данных. Если проблема несложная, выберите простую модель и обучите ее этим образцам.
b) Сложность модели = высокая, сложность задачи = низкая, размер выборки = небольшой: вам следует выбрать более простую модель, поскольку сложность модели должна быть соизмеримой со сложностью задачи и размером выборки.Даже если вы получите более высокую производительность от очень сложной модели, простая модель лучше работает с невидимыми данными. Причина в том, что оценка основана только на небольшом количестве данных, которые не являются надежными, и, настраивая параметры сложной модели, вы, вероятно, переобучите модель. На практике простая модель была бы более надежной.
c) Сложность модели = низкая, сложность проблемы = высокая, размер выборки = небольшой: если возможно, попробуйте решить подзадачу или более простой вариант проблемы. По крайней мере, можно добиться значимого результата.
По крайней мере, можно добиться значимого результата.
d) Сложность модели = высокая, сложность проблемы = высокая, размер выборки = малый: даже если вы получите высокую точность, модель выйдет из строя в реальной ситуации при работе с невидимыми данными.
Большой размер выборки: Наличие достаточного количества выборок — ключ к созданию хорошей модели машинного обучения. Следует отметить, что выборки не должны быть предвзятыми. В остальном разница между малым и большим размером выборки невелика.
e) Сложность модели = низкая, сложность проблемы = низкая, размер выборки = большой: выбор модели не является большой проблемой при сложной проблеме и большом размере выборки.Большинство моделей машинного обучения дают хороший результат.
f) Сложность модели = высокая, сложность проблемы = низкая, размер выборки = большой: сложная модель может дать немного лучший результат по сравнению с типичной моделью. Учитывая объяснимость и поддержку модели, вы можете выбрать более простую модель.
g) Сложность модели = низкая, сложность проблемы = высокая, размер выборки = большой: если вам нравится работать с современными методами, это подходящий случай. Выберите сложную модель (например,глубокое обучение), и вы получите желаемый результат.
h) Сложность модели = высокая, сложность проблемы = высокая, размер выборки = большой: в этом случае вы можете убедиться в силе и красоте машинного обучения. Здесь происходит волшебство.
То, что я написал в этой статье, основано исключительно на моем опыте работы с моделями машинного обучения. Вы никогда не найдете их в курсе или книге, потому что это качественные концепции. Все данные разные, и вы не можете сформулировать количество требуемых данных. У вас не может быть правила для выбора лучшей модели без анализа данных.Однако на практике очень важно иметь общее представление о каждом из трех компонентов, обсуждаемых в этой статье. Это поможет вам предпринять правильные действия по исправлению вашей модели машинного обучения, когда она не работает._2005_2011_kopia/000/003_m-class-5.jpg)
Как всегда, я очень благодарен всем, кто читает мои работы, и надеюсь, вам понравится эта работа! Если у вас есть какие-либо вопросы или комментарии, не стесняйтесь оставлять свои отзывы ниже или вы можете связаться со мной через LinkedIn.
Настройка обучающего прогона — Машинное обучение Azure
- Статья .
- 10 минут на чтение
Оцените свой опыт
да Нет
Любой дополнительный отзыв?
Отзыв будет отправлен в Microsoft: при нажатии кнопки «Отправить» ваш отзыв будет использован для улучшения продуктов и услуг Microsoft.Политика конфиденциальности.
Представлять на рассмотрение
Спасибо.
В этой статье
Из этой статьи вы узнаете, как настроить и отправить прогоны машинного обучения Azure для обучения ваших моделей. Фрагменты кода объясняют ключевые части настройки и отправки обучающего скрипта. Затем используйте один из примеров записных книжек, чтобы найти полные сквозные рабочие примеры.
Обычно обучение начинается на локальном компьютере, а затем выполняется масштабирование до облачного кластера. С помощью машинного обучения Azure вы можете запускать сценарий на различных целевых объектах вычислений, не изменяя сценарий обучения.
Все, что вам нужно сделать, это определить среду для каждого целевого объекта вычислений в конфигурации запуска сценария . Затем, если вы хотите запустить свой обучающий эксперимент на другом целевом объекте вычислений, укажите конфигурацию запуска для этого вычисления.
Предварительные требования
Что такое конфигурация запуска сценария?
ScriptRunConfig используется для настройки информации, необходимой для отправки обучающего прогона как части эксперимента.
Вы отправляете свой обучающий эксперимент с объектом ScriptRunConfig. Этот объект включает:
- source_directory : исходный каталог, содержащий ваш обучающий сценарий
- сценарий : обучающий сценарий для запуска
- compute_target : цель вычислений для запуска на
- среда : среда, используемая при запуске сценария
- и некоторые дополнительные настраиваемые параметры (дополнительную информацию см. В справочной документации)
Обучите свою модель
Шаблон кода для отправки обучающего прогона одинаков для всех типов вычислительных целей:
- Создать эксперимент для запуска
- Создать среду, в которой будет запускаться сценарий
- Создайте ScriptRunConfig, который указывает цель вычислений и среду
- Отправить пробег
- Дождитесь завершения прогона
Или вы можете:
Создать эксперимент
Создайте эксперимент в своем рабочем пространстве. Experiemnt — это легкий контейнер, который помогает организовать отправку запусков и отслеживать код.
Experiemnt — это легкий контейнер, который помогает организовать отправку запусков и отслеживать код.
из эксперимента по импорту azureml.core
эксперимент_имя = 'мой_эксперимент'
эксперимент = эксперимент (рабочая область = ws, имя = имя_эксперимента)
Выберите цель вычислений
Выберите цель вычислений, на которой будет выполняться ваш обучающий сценарий. Если цель вычислений не указана в ScriptRunConfig или compute_target = 'local' , Azure ML выполнит ваш сценарий локально.
В примере кода в этой статье предполагается, что вы уже создали цель вычислений my_compute_target из раздела «Предварительные требования».
Примечание
Azure Databricks не поддерживается в качестве целевого объекта вычислений для обучения модели. Вы можете использовать Azure Databricks для подготовки данных и задач развертывания.
Создать среду
Среды машинного обучения Azure — это инкапсуляция среды, в которой происходит обучение машинному обучению.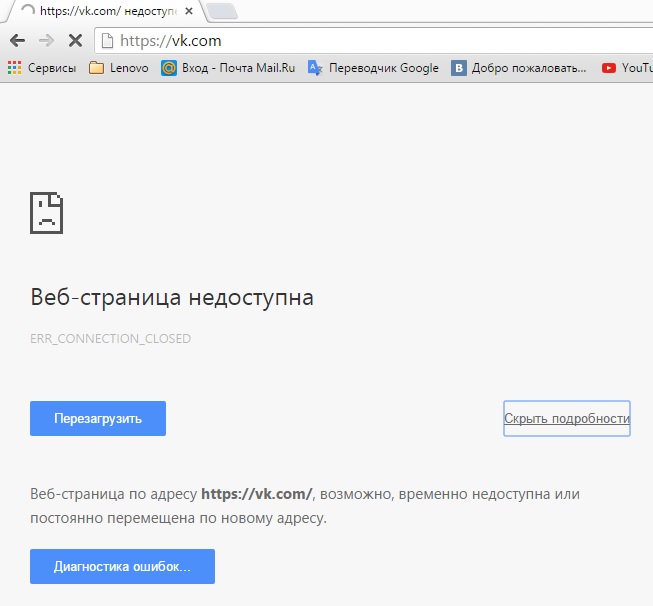 Они определяют пакеты Python, образ Docker, переменные среды и настройки программного обеспечения для ваших сценариев обучения и оценки. Они также определяют время выполнения (Python, Spark или Docker).
Они определяют пакеты Python, образ Docker, переменные среды и настройки программного обеспечения для ваших сценариев обучения и оценки. Они также определяют время выполнения (Python, Spark или Docker).
Вы можете определить свою собственную среду или использовать специально подобранную среду Azure ML. Курируемые среды — это предопределенные среды, доступные в вашем рабочем пространстве по умолчанию. Эти среды поддерживаются кэшированными образами Docker, что снижает затраты на подготовку к запуску. См. Полный список доступных настраиваемых сред в разделе «Курируемые среды машинного обучения Azure».
Для удаленных целевых вычислений вы можете использовать одну из этих популярных курируемых сред, чтобы начать с:
из azureml.core import Workspace, Environment
ws = Workspace.from_config ()
myenv = Environment.get (workspace = ws, name = "AzureML-Minimal")
Дополнительные сведения и сведения о средах см. В разделе Создание и использование программных сред в Машинном обучении Azure.
Локальная цель вычислений
Если вашей целью вычислений является ваш локальный компьютер , вы несете ответственность за обеспечение доступности всех необходимых пакетов в среде Python, в которой выполняется сценарий.Используйте python.user_managed_dependencies , чтобы использовать текущую среду Python (или Python по указанному вами пути).
из среды импорта azureml.core
myenv = Environment ("окружение, управляемое пользователем")
myenv.python.user_managed_dependencies = Истина
# Вы можете выбрать конкретную среду Python, указав путь к Python
# myenv.python.interpreter_path = '/ home / johndoe / miniconda3 / envs / myenv / bin / python'
Создайте конфигурацию запуска сценария
Теперь, когда у вас есть цель вычислений ( my_compute_target , см. Предварительные требования и среда ( myenv , см. Создание среды), создайте конфигурацию запуска сценария, которая запускает ваш обучающий сценарий ( train.), расположенный в вашем каталоге  py
py project_folder :
из azureml.core импорт ScriptRunConfig
src = ScriptRunConfig (исходный_каталог = папка_проекта,
script = 'train.py',
compute_target = my_compute_target,
среда = myenv)
# Установить цель вычислений
# Пропустите это, если вы работаете на локальном компьютере
script_run_config.run_config.target = my_compute_target
Если вы не укажете среду, для вас будет создана среда по умолчанию.
Если у вас есть аргументы командной строки, которые вы хотите передать своему обучающему сценарию, вы можете указать их с помощью параметра arguments конструктора ScriptRunConfig, например аргументов = ['- arg1', arg1_val, '--arg2', arg2_val] .
Если вы хотите изменить максимальное время, разрешенное по умолчанию для выполнения, вы можете сделать это с помощью параметра max_run_duration_seconds . Система попытается автоматически отменить запуск, если он займет больше времени, чем это значение.
Система попытается автоматически отменить запуск, если он займет больше времени, чем это значение.
Укажите конфигурацию распределенного задания
Если вы хотите запустить распределенное задание по обучению, укажите конфигурацию распределенного задания для параметра distribution_job_config . Поддерживаемые типы конфигурации включают MpiConfiguration, TensorflowConfiguration и PyTorchConfiguration.
Для получения дополнительной информации и примеров по запуску распределенных заданий Horovod, TensorFlow и PyTorch см .:
Провести эксперимент
запустить = эксперимент.отправить (config = src)
run.wait_for_completion (show_output = True)
Важно
Когда вы отправляете тренировочный прогон, создается моментальный снимок каталога, который содержит ваши обучающие сценарии, и он отправляется в цель вычислений. Он также сохраняется как часть эксперимента в вашем рабочем пространстве. Если вы измените файлы и снова отправите запуск, будут загружены только измененные файлы.
Если вы измените файлы и снова отправите запуск, будут загружены только измененные файлы.
Чтобы предотвратить включение ненужных файлов в снимок, создайте файл игнорирования (.gitignore или .amlignore ) в каталоге. Добавьте в этот файл файлы и каталоги, которые нужно исключить. Дополнительные сведения о синтаксисе для использования в этом файле см. В разделе синтаксис и шаблоны для .gitignore . Файл .amlignore использует тот же синтаксис. Если существуют оба файла, используется файл .amlignore , а файл .gitignore не используется.
Для получения дополнительной информации о снимках см. Снимки.
Важно
Специальные папки Две папки, выводит и , журналы , получают особую обработку в Машинном обучении Azure.Во время обучения, когда вы записываете файлы в папки с именем , выходы и , журналы , относящиеся к корневому каталогу ( . и  /outputs
/outputs ./logs , соответственно), файлы автоматически загружаются в вашу историю запусков, поэтому что у вас есть доступ к ним после завершения вашего запуска.
Чтобы создавать артефакты во время обучения (например, файлы моделей, контрольные точки, файлы данных или изображения на графике), запишите их в папку ./outputs .
Точно так же вы можете записывать любые журналы с вашего тренировочного пробега на .Папка / logs . Чтобы использовать интеграцию TensorBoard Машинного обучения Azure, убедитесь, что вы записываете свои журналы TensorBoard в эту папку. Во время выполнения вы сможете запустить TensorBoard и транслировать эти журналы. Позже вы также сможете восстановить журналы любого из ваших предыдущих запусков.
Например, чтобы загрузить файл, записанный в папку , выводит , на локальный компьютер после запуска удаленного обучения: run.download_file (name = 'output / my_output_file', output_file_path = 'my_destination_path')
Отслеживание и интеграция Git
Когда вы запускаете обучающий прогон, где исходный каталог является локальным репозиторием Git, информация о репозитории сохраняется в истории прогона. Дополнительные сведения см. В разделе «Интеграция Git для машинного обучения Azure».
Дополнительные сведения см. В разделе «Интеграция Git для машинного обучения Azure».
Примеры ноутбуков
Примеры настройки запусков для различных сценариев обучения см. В этих записных книжках:
Узнайте, как запускать записные книжки, прочитав статью Использование записных книжек Jupyter для изучения этой службы.
Поиск и устранение неисправностей
AttributeError: объект ‘RoundTripLoader’ не имеет атрибута ‘comment_handling’ : Эта ошибка возникает из новой версии (v0.17.5) из
ruamel-yaml, зависимостиazureml-core, которая вносит критическое изменение вazureml-core. Чтобы исправить эту ошибку, удалитеruamel-yaml, запустивpip uninstall ruamel-yamlи установив другую версиюruamel-yaml; поддерживаемые версии: от v0.15.35 до v0.17.4 (включительно). Вы можете сделать это, запустивpip install "ruamel-yaml> = 0.15.35, <0.. 17.5" Ошибка при выполнении
jwt.exceptions.DecodeError: точное сообщение об ошибке:jwt.exceptions.DecodeError: требуется, чтобы вы передали значение для аргумента «алгоритмы» при вызове decode ().Рассмотрите возможность обновления до последней версии azureml-core:
pip install -U azureml-core.Если вы столкнулись с этой проблемой при локальных запусках, проверьте версию PyJWT, установленную в вашей среде, в которой вы запускаете запуски. Поддерживаемые версии PyJWT: <2.0,0. Удалите PyJWT из среды, если версия> = 2.0.0. Вы можете проверить версию PyJWT, удалить и установить нужную версию следующим образом:
- Запустите командную оболочку, активируйте среду conda, в которой установлено azureml-core.
- Введите
pip freezeи найдитеPyJWT, если он найден, указанная версия должна быть <2.0.0 - Если указанная версия не является поддерживаемой,
pip удалите PyJWTв командной оболочке и введите y для подтверждения. - Установить с помощью
pip install 'PyJWT <2.0.0'
Если вы отправляете среду, созданную пользователем, вместе с запуском, подумайте об использовании последней версии azureml-core в этой среде. Версии> = 1.18.0 azureml-core уже закрепили PyJWT <2.0.0. Если вам нужно использовать версию azureml-core <1.18.0 в отправляемой вами среде, обязательно укажите PyJWT <2.0.0 в зависимостях вашего пакета.
ModuleErrors (модуль не назван) : если вы запускаете ModuleErrors при отправке экспериментов в Azure ML, обучающий сценарий ожидает, что пакет будет установлен, но не добавлен.После того, как вы укажете имя пакета, Azure ML установит пакет в среде, используемой для вашего учебного прогона.
Если вы используете оценщики для отправки экспериментов, вы можете указать имя пакета с помощью параметра
pip_packagesилиconda_packagesв оценщике в зависимости от того, из какого источника вы хотите установить пакет. Вы также можете указать yml-файл со всеми своими зависимостями, используя conda_dependencies_file, или перечислить все ваши требования к pip в текстовом файле, используя параметрpip_requirements_file.Если у вас есть собственный объект среды машинного обучения Azure, который вы хотите переопределить изображение по умолчанию, используемое оценщиком, вы можете указать эту среду с помощью параметраenvironmentконструктора оценщика.Azure ML обслуживает образы докеров, и их содержимое можно увидеть в контейнерах AzureML. Зависимости, специфичные для фреймворка, перечислены в соответствующей документации фреймворка:
Примечание
Если вы считаете, что конкретный пакет достаточно распространен, чтобы его можно было добавить в образы и среды, поддерживаемые Azure ML, пожалуйста, поднимите проблему GitHub в контейнерах AzureML.
NameError (имя не определено), AttributeError (объект не имеет атрибута) : это исключение должно исходить из ваших обучающих сценариев.
Вы можете просмотреть файлы журнала на портале Azure, чтобы получить дополнительные сведения о том, что конкретное имя не определено, или об ошибке атрибута. Из SDK вы можете использовать run.get_details (), чтобы просмотреть сообщение об ошибке. Здесь также будут перечислены все файлы журнала, созданные для вашего запуска. Обязательно ознакомьтесь со своим сценарием тренировки и исправьте ошибку перед повторной отправкой пробежки.Запуск или удаление эксперимента : Эксперименты можно заархивировать с помощью Experiment.archive или на вкладке «Эксперимент» в клиенте студии машинного обучения Azure с помощью кнопки «Архивировать эксперимент». Это действие скрывает эксперимент из списковых запросов и представлений, но не удаляет его.
Окончательное удаление отдельных экспериментов или прогонов в настоящее время не поддерживается. Дополнительные сведения об удалении ресурсов рабочей области см. В разделе Экспорт или удаление данных рабочей области службы машинного обучения.
Документ метрики слишком велик : Машинное обучение Azure имеет внутренние ограничения на размер объектов метрики, которые могут быть зарегистрированы сразу после прогона обучения. Если вы столкнулись с ошибкой «Документ метрики слишком большой» при регистрации метрики со списком, попробуйте разделить список на более мелкие части, например:
run.log_list ("имя моей метрики", my_metric [: N]) run.log_list ("название моей метрики", my_metric [N:])Внутри Azure ML объединяет блоки с одинаковым именем метрики в непрерывный список.
Запуск целевого объекта вычислений занимает много времени : образы Docker для целевых объектов вычислений загружаются из реестра контейнеров Azure (ACR). По умолчанию Машинное обучение Azure создает ACR, который использует базовый уровень обслуживания . Изменение ACR для рабочего пространства на стандартный или премиум-уровень может сократить время, необходимое для создания и загрузки образов.
Дополнительные сведения см. В разделе Уровни службы реестра контейнеров Azure.
 17.5"
17.5" 
 Вы также можете указать yml-файл со всеми своими зависимостями, используя
Вы также можете указать yml-файл со всеми своими зависимостями, используя  Вы можете просмотреть файлы журнала на портале Azure, чтобы получить дополнительные сведения о том, что конкретное имя не определено, или об ошибке атрибута. Из SDK вы можете использовать
Вы можете просмотреть файлы журнала на портале Azure, чтобы получить дополнительные сведения о том, что конкретное имя не определено, или об ошибке атрибута. Из SDK вы можете использовать 
 Дополнительные сведения см. В разделе Уровни службы реестра контейнеров Azure.
Дополнительные сведения см. В разделе Уровни службы реестра контейнеров Azure.Следующие шаги
Мобильные данные не работают? Вот несколько решений.
Наши смартфоны - незаменимые крошечные карманные компьютеры, но они стали настолько удобными, что мы почти не можем жить без них.Интернет-соединение - это основа работы со смартфоном, поэтому всякий раз, когда данные перестают работать, кажется, что мир останавливается. Что вы делаете, чтобы вернуться в сетку? Возможно, вы столкнулись с проблемой передачи данных по сотовой сети. Вот несколько решений для восстановления мобильных данных.
Читать далее: Вот как устранить и устранить наиболее распространенные проблемы Wi-Fi
Примечание редактора: Некоторые инструкции в этой статье были созданы с использованием Pixel 4a с 5G под управлением Android 12.Имейте в виду, что шаги могут немного отличаться в зависимости от используемого вами устройства.
Проверить, включен ли режим полета
В режиме полета отключаются все беспроводные антенны, включая мобильные данные, Wi-Fi и Bluetooth. Обычно его включают случайно (по крайней мере, со мной такое случается постоянно!). Идите и проверьте, случилось ли это с вами. Часто в быстрых настройках области уведомлений есть переключатель, но вы также можете сделать это в настройках.
Как включить / выключить режим полета:
- Откройте приложение Settings .
- Войдите в Сеть и Интернет .
- Ищите Режим полета . Рядом с ним будет переключатель. Нажмите на него, чтобы включить или выключить.
Кроме того, включение и выключение режима полета может сбросить настройки и вернуть все в нормальное состояние. Если ваш телефон не был в режиме полета, включите и выключите эту функцию и посмотрите, снова ли это заставит ваши данные работать.
А перезагрузку пробовали?
Каким бы необъяснимым это ни было, мы находим, что большинство проблем со смартфоном решаются простой перезагрузкой. Множество возможных расхождений может вызвать проблемы с вашими мобильными данными, и есть вероятность, что если вы здесь ищете ответы, проблема с телефоном будет немного сложнее, но не помешает напомнить вам попробовать старый добрый перезапуск. Это может сработать.
Множество возможных расхождений может вызвать проблемы с вашими мобильными данными, и есть вероятность, что если вы здесь ищете ответы, проблема с телефоном будет немного сложнее, но не помешает напомнить вам попробовать старый добрый перезапуск. Это может сработать.
Читайте также: Мой телефон не заряжается! Что я могу сделать?
Проверить свой план?
Edgar Cervantes / Android Authority
Некоторые тарифные планы мобильной передачи данных имеют ограничения и ограничения. Изучите условия своего плана и посмотрите, не было ли использовано больше данных, чем следовало бы.Вы можете быть ограничены или задушены. Также примите во внимание тот факт, что вы можете задержать платеж. Даже лучшие из нас иногда забывают о счетах. Не говоря уже о том, что иногда карты отклоняются без видимой причины.
Switch: Лучшие доступные безлимитные тарифные планы
Проверьте вашу SIM-карту
SIM-карты могут перемещаться, и иногда контакты могут выходить из строя. Если описанные выше действия вам не подходят, рекомендуется немного поиграть с SIM-картой. Вытащите и снова вставьте.Может, попробуй немного почистить? Не помешает попробовать! Это отличный способ снова заставить мобильные данные работать.
Если описанные выше действия вам не подходят, рекомендуется немного поиграть с SIM-картой. Вытащите и снова вставьте.Может, попробуй немного почистить? Не помешает попробовать! Это отличный способ снова заставить мобильные данные работать.
Это гугл?
Если конкретно приложения Google не работают с мобильными данными, есть небольшая вероятность, что это что-то связано с Search Giant. Попробуйте выполнить следующие действия, чтобы убедиться, что все вернется в норму.
- Очистите кеш в приложении "Сервисы Google Play": Настройки> Приложения> Просмотреть все приложения> Сервисы Google Play> Хранилище и кеш> Очистить кеш.
- Найдите доступные обновления системного программного обеспечения: Настройки> Система> Обновление системы> Проверить наличие обновлений .
- Удалите и повторно добавьте свою учетную запись Google: перейдите в «Настройки »> «Пароли и учетные записи»> «Учетная запись Google»> «Удалить учетную запись ».

Связано: Это лучшие продукты Google, которые вы можете купить
Отключение и прием
Вы на природе? Может быть, вы находитесь в бетонном здании.Или вы просто проезжаете через зону с нестабильным приемом. Всегда есть вероятность, что вы недоступны для сети, что вызовет проблемы с вашими мобильными данными.
Также учтите, что, хотя это бывает редко, сети операторов связи тоже могут выходить из строя, вызывая перебои в обслуживании. Нам нравится рекомендовать DownDetector.com проверять, когда службы не работают. Веб-сайт собирает отчеты потребителей и сообщает вам о сбоях в работе. Также есть живая карта, чтобы увидеть, является ли проблема локальной. Просто войдите туда, введите своего оператора связи и нажмите кнопку поиска.Если сеть не работает, все, что вы можете сделать, это подождать.
Сбросить APN
APN - это то, как ваш телефон подключается к сети вашего оператора мобильной связи. Думайте об этом как о пароле Wi-Fi для мобильных данных, но гораздо более сложном, с настройками IP, данными шлюза и т. Д.
Д.
Как сбросить настройки APN:
- Откройте приложение Settings .
- Войдите в Сеть и Интернет .
- Выберите Мобильная сеть .
- Развернуть Расширенный .
- Hit Имена точек доступа .
- Нажмите на кнопку меню с тремя точками.
- Выберите Сбросить до значений по умолчанию .
Сбросить настройки сети
Эдгар Сервантес / Android Authority
Если ни одна из вышеперечисленных опций не работает, это может означать, что некоторые посторонние настройки были изменены в процессе. Вероятно, это связано с сетью, поэтому сброс настроек сети до заводских значений по умолчанию может решить проблему.
Как сбросить настройки сети:
- Откройте приложение Settings .
- Выберите Система .
- Войдите в Параметры сброса .
- Hit Сбросить Wi-Fi, мобильный телефон и Bluetooth .
- Нажмите Сбросить настройки .

Сброс заводских данных
Если ничего не помогает восстановить мобильные данные, выполните сброс данных до заводских. Это сотрет все на вашем телефоне и вернет все настройки к заводским значениям по умолчанию.Это означает, что ваш телефон останется таким, каким вы его включили в первый раз (программно).
Это устраняет практически все проблемы с программным обеспечением, с которыми вы можете столкнуться. Это лучшее решение многих проблем, но его следует использовать в крайнем случае из-за неудобств, связанных с удалением всех данных.
Как восстановить заводские настройки телефона Android:
- Откройте приложение Settings .
- Выберите Система .
- Войдите в Параметры сброса .
- Hit Стереть все данные (возврат к заводским настройкам) .
- Нажмите Стереть все данные .

Подробнее: Как восстановить заводские настройки устройств Android
Обратиться за профессиональной помощью
Эдгар Сервантес / Android Authority
Теперь, если это не поможет, вам, вероятно, потребуется профессиональная проверка устройства. На данный момент это может быть аппаратная проблема. Обратитесь к производителю телефона, оператору связи или, возможно, даже к Google.Возможно, пришло время обратиться к вашей страховой компании, если она у вас есть.
Next: Лучшие варианты страховки для смартфонов
КомментарииИзвестные проблемы и ограничения
При использовании машинного обучения Cloudera вы можете столкнуться с некоторыми известными проблемами.
Максимальная длина поля имени пользователя составляет 50 байтов (DSE-18016)
В CML длина поля имени пользователя ограничена 50 байтами, что меньше соответствующего
длина поля в Microsoft Active Directory. Это может вызвать ошибки при подключении пользователя, у которого
длинное имя.
Это может вызвать ошибки при подключении пользователя, у которого
длинное имя.
Сбой доступа к озеру данных с поддержкой RAZ (DSE-18290)
Если вы пытаетесь получить доступ к хранилищу в озере данных версии 7.2.11 или выше, и RAZ включен, устаревшие движки не будут работать. Эта проблема не возникает при использовании среды выполнения машинного обучения. с последней версией дополнения Spark.
Не удалось установить рабочее пространство (CDPSDX-3207)
Установка может завершиться ошибкой: Ошибка установки.Время установки истекло. Это периодическая ошибка.
Решение: попробуйте снова установить рабочую область.
Графана (DSE-18499)
Пользователи могут не видеть какие-либо предварительно заполненные информационные панели Grafana (кластер, контейнеры, Node, Models) внутри рабочего пространства машинного обучения.
Происхождение данных не сообщается в Атлас (DSE-16706)
Регистрация происхождения обучающих данных с помощью файла связывания не работает.
Дополнение среды выполнения не загружается (DSE-16200)
Надстройка среды выполнения Spark может дать сбой при обновлении рабочей области.
Решение: Чтобы решить эту проблему, попробуйте перезагрузить надстройку. В в меню параметров рядом с отказавшей надстройкой выберите Перезагрузить.
Истекло время инициализации рабочего пространства CML
При инициализации рабочего пространства CML для процесса может истечь время ожидания с ошибкой, аналогичной Предупреждение FailedMount или Не удалось синхронизировать секретный кеш: время ожидания истекло
жду состояния. Это может произойти в AWS или Azure.
Решение: удалите рабочую область и повторите подготовку.
Подключение конечных точек CML от DataHub и Cloudera Data Engineering (DSE-14882)
Когда службы CDP подключаются к службам CML, если рабочее пространство ML предоставляется в общедоступном
подсети, трафик сначала маршрутизируется из VPC, а затем возвращается обратно. В частном облаке
CML, трафик не маршрутизируется извне.
В частном облаке
CML, трафик не маршрутизируется извне.
Предупреждение браузера Chrome при доступе к рабочей области машинного обучения (DSE-14652)
Некоторые браузеры (Chrome 86 и выше) могут отображать следующее сообщение, когда пользователь пытается для доступа к рабочей области, настроенной без TLS. Информация, которую вы
собирается отправить небезопасно. Обходной путь: примите и обойдите предупреждение браузера.
Explanation: Chrome 86 и выше отображает предупреждения при отправке или перенаправлении форм. на http: //, что имеет место при подключении к рабочей области, настроенной без TLS, с использованием SSO. Рабочее пространство по-прежнему будет функционально во всех отношениях, если вы примете и обойдете браузер. предупреждение. Невозможно включить TLS в рабочей области, созданной без TLS.
Среда с поддержкой Ranger и RAZ (OPSAPS-59476)
При использовании сред с поддержкой Ranger и RAZ в CML общедоступного облака выполните следующие действия. команды на терминале сеанса или встроенные в код пользователя перед выполнением любых других
операции:
команды на терминале сеанса или встроенные в код пользователя перед выполнением любых других
операции: sed -i "s / http: / https: / g"
/etc/hadoop/conf/core-site.xml sed -i "s / http: / https: / g"
/etc/hive/conf/core-site.xml Сиротские блочные тома EBS после удаления рабочего пространства машинного обучения (DSE-14606)
Если рабочее пространство CML на AWS удалено с помощью выпуска от 3 февраля 2021 г. (1.15.0-b72) из
CML Control Plane, бесхозные блочные тома EBS могут быть оставлены позади. Состояние любого сироты
тома отображаются как Доступные в консоли EC2 (вы можете увидеть список
томов, перейдя к). Тома имеют имена, похожие на kubernetes-dynamic-pvc- , помечены kubernetes.io/created-for/pvc/namespace":"mlx ". Эти бесхозные тома EBS
необходимо удалить, чтобы предотвратить утечку облачных ресурсов.
Обновление не поддерживается в NFS v4.х (DSE-14519, DSE-14077)
Обновление рабочих областей машинного обучения в Azure, настроенных с использованием внешних служб NFS с использованием NFS v4.x протокол в настоящее время не поддерживается.
Приложения могут не запускаться после обновления Kubernetes (DSE-14355)
В некоторых случаях приложения, которые работали до обновления Kubernetes, могут не запускаться. после обновления Kubernetes. Пользователи, имеющие доступ к таким приложениям, должны перезапустить их. вручную.
Прозрачный прокси-сервер поддерживается только на AWS (DSE-13937)
Cloudera Machine Learning при использовании в общедоступном облаке AWS поддерживает прозрачные прокси.Прозрачный прокси-сервер позволяет CML проксировать веб-запросы без использования какого-либо конкретного браузера.
настраивать. В нормальном режиме работы CML требует доступа к нескольким внешним доменам. За
для получения дополнительной информации см .: Назначения исходящего сетевого доступа.
За
для получения дополнительной информации см .: Назначения исходящего сетевого доступа.
Невозможно ограничить доступ к приложению (DSE-13928, DSE-6651)
Авторизация, используемая приложениями, может быть устаревшей. Например, если пользователь удален из проекта в CDSW или CML (больше нет доступа для чтения к проекту и его приложения), этот пользователь может продолжать иметь доступ к приложению, если он получил доступ приложение до того, как их доступ был отозван.
Обходной путь: при обновлении разрешений проекта, в котором есть приложения, перезапустите приложения, чтобы гарантировать, что приложения используют актуальную авторизацию.
Время ожидания сеансов Jupyter Notebook не истекает (DSE-13741)
сеансов Jupyter Notebook в устаревшем движке: с 8 по
двигатель: 13 не выходить после IDLE_MAXIMUM_MINUTES из
бездействие. Они будут работать до SESSION_MAXIMUM_MINUTES (что составляет семь
дней по умолчанию).
Временное решение
Вы можете изменить конфигурацию кластера, чтобы применить исправление для этой проблемы. Изменять команда редактора для Jupyter Notebook в каждом движке, который ее использует, на следующее:
NOTEBOOK_TIMEOUT_SECONDS = $ (python3 -c «print ($ {IDLE_MAXIMUM_MINUTES} * 60)«)
/ usr / local / bin / jupyter notebook --no-browser --ip = 127.0.0.1 --port = $ {CDSW_APP_PORT}
--NotebookApp.token = --NotebookApp.allow_remote_access = True --NotebookApp.quit_button = Ложь
--log-level = ОШИБКА --NotebookApp.shutdown_no_activity_timeout = 300
--MappingKernelManager.cull_idle_timeout = $ {NOTEBOOK_TIMEOUT_SECONDS}
--TerminalManager.cull_inactive_timeout = $ {NOTEBOOK_TIMEOUT_SECONDS}
--MappingKernelManager.cull_interval = 60 --TerminalManager.cull_interval = 60
--MappingKernelManager.cull_connected = Истина Это делает следующее:- Убивает все работающие записные книжки после IDLE_MAXIMUM_MINUTES бездействия
- Завершает сеанс CDSW / CML, в котором запущен Jupyter, через 5 минут без ноутбуки
Отсутствует кнопка воспроизведения в сеансах CML со средами выполнения ML (DSE-13629)
Для сеансов ML Runtime кнопка Play может не отображаться.
Временное решение:
Вы все еще можете запустить код сеанса, выбрав Run–> Run All или Выполнить -> Выполнить строки, когда кнопка Воспроизвести не отображается в пользовательском интерфейсе.
Запланированное задание не выполняется после переключения на среду выполнения, приложение не может быть перезапущен (DSE-13573)
ML Runtimes - это новая функция в текущем выпуске. Хотя теперь вы можете изменить свой существующие проекты с Engine на ML Runtime, в настоящее время не рекомендуется переносить существующие проекты.
Приложения и задания, созданные с помощью движков, могут быть затронуты после изменения их проекта. использовать среды выполнения ML на основе следующего:- Вы будете вынуждены перейти на среды выполнения ML, если попытаетесь обновить соответствующий редактор / ядро настройки заданий, моделей, экспериментов или приложений
- Приложения не могут быть перезапущены из пользовательского интерфейса в перенесенном проекте, если только ML Runtime
настройки обновляются для этого приложения.

Проблемы с производительностью NFS на AWS EFS (DSE-12404)
CML использует NFS в качестве файловой системы для хранения данных приложений и пользователей.Производительность NFS может быть намного медленнее, чем ожидалось, в ситуациях, когда специалист по данным пишет очень большое число (обычно тысячи) небольших файлов. Примеры задач включают: использование git clone для клонирования очень большого репозитория исходного кода (например, TensorFlow) или с помощью pip для установки пакета Python, который включает код JavaScript (например, сюжетно). Снижение производительности особенно характерно для CML на AWS. (который использует EFS), но его можно увидеть в других средах.
Отключить загрузку и скачивание файлов (DSE-12065)
Вы не можете отключить загрузку и загрузку файлов при использовании Jupyter Notebook.
Сбой операции удаления рабочего пространства (DSE-8834)
Операция удаления рабочего пространства завершается ошибкой, если создание рабочего пространства все еще продолжается.
CML не поддерживает изменение ограничений масштабирования ЦП / графического процессора для подготовленных рабочих пространств машинного обучения. (DSE-8407)
При инициализации рабочего пространства CML в настоящее время поддерживает максимум 30 узлов каждого типа: Процессоры и графические процессоры.В настоящее время CML не позволяет увеличить этот предел для существующих рабочие места.
Временное решение:- Войдите в веб-интерфейс CDP по адресу https://console.us-west-1.cdp.cloudera.com, используя свои корпоративные учетные данные или любые другие учетные данные, полученные от администратора CDP.
- Щелкните "Рабочие области машинного обучения".
- Выберите рабочее пространство, пределы которого вы хотите изменить, и перейдите в его Страница с подробностями.
- Скопируйте идентификатор Liftie Cluster ID рабочего пространства. Он должен быть формата,
лифти- abcdefgh. - Войдите в консоль AWS EC2 и нажмите Auto Scaling. Группы.
- Вставьте идентификатор кластера Liftie в поле поискового фильтра и нажмите клавишу ВВОД.
- Щелкните группу автоматического масштабирования с таким именем, как:
liftie-abcdefgh-ml-pqrstuv-xyz- cpu-worker -0-NodeGroup.Особенно обратите внимание на «cpu-worker» в середине строки. - На странице «Подробности» этой группы автоматического масштабирования нажмите «Изменить».
- Установите желаемое значение Max capacity и нажмите Save .
 Он должен быть формата,
Он должен быть формата, Обратите внимание, что CML не поддерживает уменьшение максимального количества экземпляров группы автоматического масштабирования из-за
с определенными ограничениями в AWS.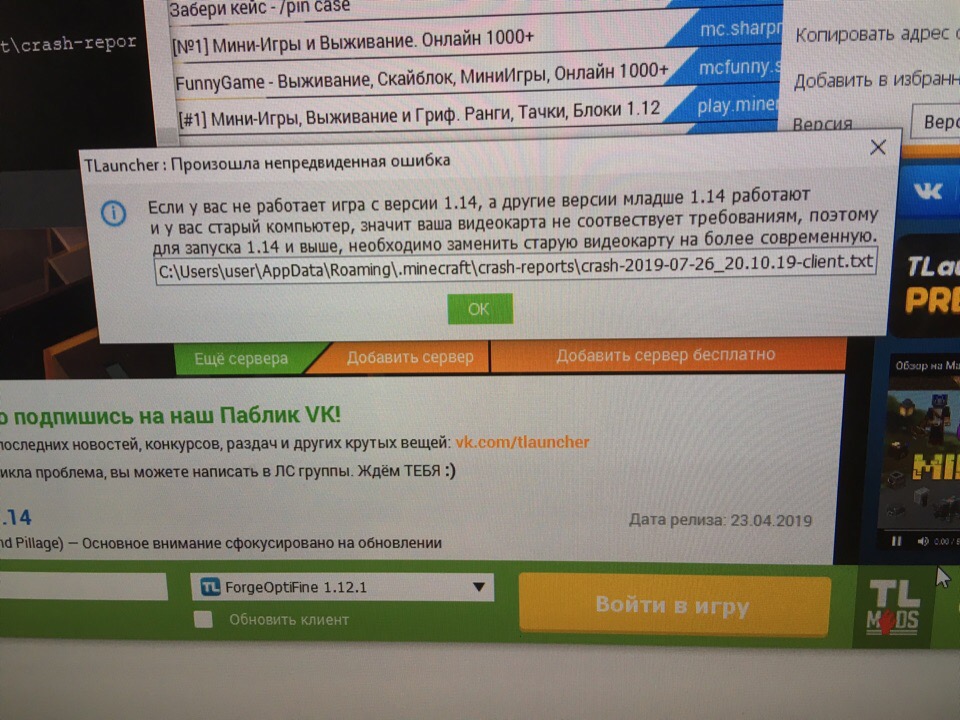
SSO не работает, если первый пользователь, получивший доступ к рабочей области машинного обучения, не является сайтом Администратор
Проблема: Если пользователь, которому назначена роль MLUser, является первым пользователем, веб-приложение отобразит ошибку.
Обходной путь: Любой пользователь, которому назначена роль MLAdmin, всегда должен быть первым пользователем, получить доступ к рабочему пространству машинного обучения.
API не предписывает максимальное количество узлов для рабочих пространств машинного обучения
Проблема: Когда API используется для предоставления новых рабочих пространств машинного обучения, он не обеспечивает принудительное верхний предел диапазона автомасштабирования.
Узлы рабочего пространства машинного обучения с уменьшением масштаба не работают должным образом (MLX-637, MLX-638)
Проблема: Узлы масштабирования не работают так плавно, как ожидалось, из-за отсутствия
Bin Packing в планировщике Spark по умолчанию, а также потому, что динамическое размещение в настоящее время не выполняется. включено.В результате в настоящее время модули инфраструктуры, модули драйвера / исполнителя Spark и сеанс
стручки помечаются как не подлежащие выселению с помощью
включено.В результате в настоящее время модули инфраструктуры, модули драйвера / исполнителя Spark и сеанс
стручки помечаются как не подлежащие выселению с помощью cluster-autoscaler.kubernetes.io/safe-to-evict: "ложная" аннотация .
Типы измерений
Типы измерений
Эта страница относится к параметру
типа, который является частью меры.
Типтакже может использоваться как часть измерения или фильтра, описанного на странице документации по типам измерений, фильтров и параметров.Тип
также может использоваться как часть группы измерений, описанной на странице документации параметрагруппа_измерений.
view: view_name {
measure: field_name {
type: measure_field_type
}
}
Эта страница содержит подробную информацию о различных типах, которые могут быть присвоены мере. У меры может быть только один тип, и по умолчанию используется значение
У меры может быть только один тип, и по умолчанию используется значение , строка , если тип не указан.
Некоторые типы мер имеют вспомогательные параметры, которые описаны в соответствующем разделе.
Каждый тип меры попадает в одну из следующих категорий. Эти категории определяют, выполняет ли тип меры агрегирование, тип полей, на которые может ссылаться этот тип меры, и можно ли отфильтровать тип меры с помощью параметра Filters :
- Агрегатные меры : Типы агрегированных мер выполняют агрегирование, например,
суммаисреднее. Агрегированные меры могут ссылаться только на измерения, но не на другие меры.Это единственный тип меры, который работает с параметромFilters. - Неагрегированные меры : Неагрегированные меры, как следует из названия, представляют собой типы мер, которые не выполняют агрегирование, например
номерида нет. Эти типы мер выполняют простые преобразования и, поскольку они не выполняют агрегирования, могут ссылаться только на агрегированные меры или ранее агрегированные измерения. Вы не можете использовать параметр Filtersс этими типами мер. - Меры Post-SQL : Меры Post-SQL - это особые типы мер, которые выполняют определенные вычисления после того, как Looker сгенерировал запрос SQL. Они могут ссылаться только на числовые меры или числовые измерения. Вы не можете использовать параметр
Filtersс этими типами мер.
 Эти типы мер выполняют простые преобразования и, поскольку они не выполняют агрегирования, могут ссылаться только на агрегированные меры или ранее агрегированные измерения. Вы не можете использовать параметр
Эти типы мер выполняют простые преобразования и, поскольку они не выполняют агрегирования, могут ссылаться только на агрегированные меры или ранее агрегированные измерения. Вы не можете использовать параметр | Тип | Категория | Описание |
|---|---|---|
среднее | Совокупный | Создает среднее (среднее) значений в столбце |
average_distinct | Совокупный | Правильно генерирует среднее (среднее) значений при использовании денормализованных данных. Полное описание см.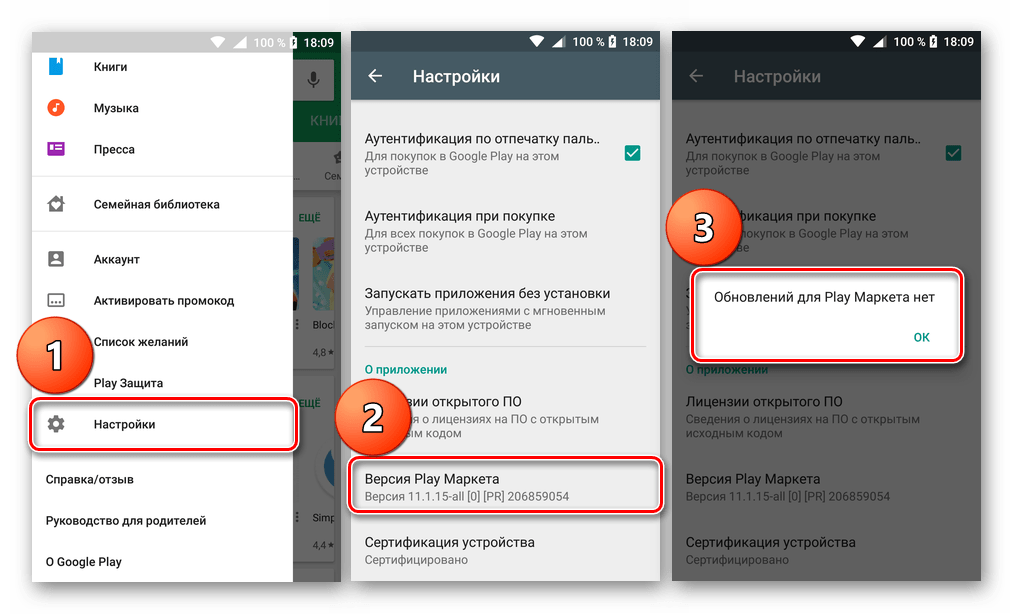 В приведенном ниже определении. В приведенном ниже определении. |
счетчик | Совокупный | Создает количество строк |
count_distinct | Совокупный | Создает количество уникальных значений в столбце |
дата | Неагрегатное | Для мер, содержащих даты |
список | Совокупный | Создает список уникальных значений в столбце |
макс | Совокупный | Создает максимальное значение в столбце |
медиана | Совокупный | Создает медианное значение (среднее значение) значений в столбце |
median_distinct | Совокупный | Правильно генерирует медианное значение (среднее значение) значений, когда соединение вызывает разветвление.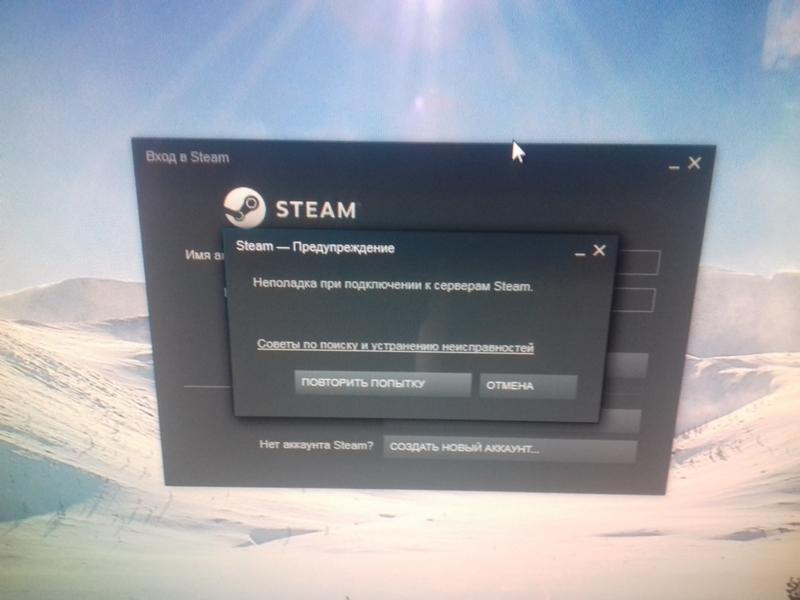 Полное описание см. В приведенном ниже определении. Полное описание см. В приведенном ниже определении. |
мин | Совокупный | Создает минимальное значение в столбце |
номер | Неагрегатное | Для мер, содержащих числа |
процентов от предыдущего | Post-SQL | Создает процентную разницу между отображаемыми строками |
процентов от общей суммы | Post-SQL | Создает процент от общего количества для каждой отображаемой строки |
процентиль | Совокупный | Создает значение в указанном процентиле в столбце |
percentile_distinct | Совокупный | Правильно генерирует значение в указанном процентиле, когда соединение вызывает разветвление. Полное описание см. В приведенном ниже определении. |
рабочий_общий | Post-SQL | Создает промежуточную сумму для каждой отображаемой строки |
строка | Неагрегатное | Для показателей, содержащих буквы или специальные символы (как в MySQL GROUP_CONCAT функция) |
сумма | Совокупный | Создает сумму значений в столбце |
sum_distinct | Совокупный | Правильно генерирует сумму значений при использовании денормализованных данных. Полное описание см. В приведенном ниже определении. |
да нет | Неагрегатное | Для полей, которые покажут, правда ли что-то или нет. |
внутр | Неагрегатное | УДАЛЕНО 5.4 Заменено на тип: номер |
тип: среднее усредняет значения в заданном поле. Это похоже на функцию SQL
Это похоже на функцию SQL AVG .Однако, в отличие от написания необработанного SQL, Looker будет правильно вычислять средние значения, даже если соединения вашего запроса содержат разветвления.
Параметр sql для типа : среднее значение мер может принимать любое допустимое выражение SQL, которое приводит к столбцу числовой таблицы, измерению LookML или комбинации измерений LookML.
тип: среднее значение полей можно отформатировать с помощью параметров value_format или value_format_name .
Например, следующий LookML создает поле с именем avg_order путем усреднения измерения sales_price , а затем отображает его в денежном формате ($ 1,234.56):
measure: avg_order { тип: средний sql: $ {sales_price} ;; value_format_name: usd }
type: average_distinct предназначен для использования с денормализованными наборами данных. Он усредняет неповторяющиеся значения в данном поле на основе уникальных значений, определенных параметром
Он усредняет неповторяющиеся значения в данном поле на основе уникальных значений, определенных параметром sql_distinct_key .
Это продвинутая концепция, которую можно более четко пояснить на примере. Рассмотрим денормализованную таблицу, подобную этой:
| Код позиции для заказа | Номер заказа | Заказать Доставка |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10,00 |
| 3 | 2 | 20,00 |
| 4 | 2 | 20,00 |
| 5 | 2 | 20,00 |
В этой ситуации вы можете видеть, что для каждого заказа есть несколько строк. Следовательно, если вы добавите простой показатель типа
Следовательно, если вы добавите простой показатель типа : среднее значение для столбца order_shipping , вы получите значение 16.00, хотя фактическое среднее значение составляет 15,00.
# НЕ будет вычислять правильное среднее значение measure: avg_shipping { тип: средний sql: $ {order_shipping} ;; }
Чтобы получить точный результат, вы можете объяснить Looker, как он должен идентифицировать каждый уникальный объект (в данном случае каждый уникальный порядок), используя параметр sql_distinct_key . Этот будет вычислить правильную сумму 15,00:
# Подсчитает правильное среднее measure: avg_shipping { тип: average_distinct sql_distinct_key: $ {order_id} ;; sql: $ {order_shipping} ;; }
Обратите внимание, что каждое уникальное значение sql_distinct_key должно иметь только одно соответствующее значение в sql .Другими словами, приведенный выше пример работает, потому что каждая строка с order_id из 1 имеет тот же order_shipping из 10,00, каждая строка с order_id из 2 имеет тот же order_shipping из 20,00, и скоро.
type: average_distinct Поля можно отформатировать с помощью параметров value_format или value_format_name .
type: count выполняет подсчет таблицы, аналогично функции SQL COUNT .Однако, в отличие от написания необработанного SQL, Looker будет правильно вычислять счетчики, даже если соединения вашего запроса содержат разветвления.
type: count не поддерживают параметр sql , поскольку мера типа type: count выполняет подсчет таблиц на основе первичного ключа таблицы. Если вы хотите выполнить подсчет таблицы для поля, отличного от первичного ключа таблицы, используйте показатель типа : count_distinct .
Например, следующий LookML создает поле number_of_products :
view: products { measure: number_of_products { тип: количество Drill_fields: [product_details *] # необязательно } }
Очень часто при определении меры типа : count предоставляют параметр Drill_fields (для полей), чтобы пользователи могли видеть отдельные записи, составляющие счетчик, при нажатии на нее.
Когда вы используете меру типа
: счетчикв Исследовании, визуализация помечает полученные значения именем представления, а не словом «Счетчик». Чтобы избежать путаницы, мы рекомендуем использовать множественное число для имени вашего представления, выбрав Показать полное имя поля в разделе Series в настройках визуализации или использоватьview_labelс версией во множественном числе имени вашего представления.
Если вы хотите выполнить COUNT (а не COUNT_DISTINCT ) для поля, которое не является первичным ключом, вы можете сделать это, используя показатель типа : число .Дополнительные сведения см. В статье Справочного центра «Разница между типами показателей count и count_distinct ».
Вы можете добавить фильтр к показателю типа : подсчитать , используя параметр Filters .
type: count_distinct вычисляет количество различных значений в заданном поле. Он использует функцию SQL COUNT DISTINCT .
Параметр sql для type: count_distinct Показатели могут принимать любое допустимое выражение SQL, которое приводит к столбцу таблицы, измерению LookML или комбинации измерений LookML.
Например, следующий LookML создает поле number_of_unique_customers , которое подсчитывает количество уникальных идентификаторов клиентов:
measure: number_of_unique_customers { тип: count_distinct sql: $ {customer_id} ;; }
Вы можете добавить фильтр к показателю типа : count_distinct , используя параметр Filters .
тип: дата используется с полями, содержащими даты.
Параметр sql для мер type: date может принимать любое допустимое выражение SQL, которое приводит к дате. На практике этот тип используется редко, поскольку большинство агрегатных функций SQL не возвращают даты. Одним из распространенных исключений является
На практике этот тип используется редко, поскольку большинство агрегатных функций SQL не возвращают даты. Одним из распространенных исключений является MIN или MAX измерения даты.
Например, следующий LookML создает поле most_recent_order_date , взяв максимальное значение из поля order_date :
measure: most_recent_order_date { тип: дата sql: MAX ($ {order_date}) ;; convert_tz: нет }
В этом примере type: date можно опустить, и значение будет рассматриваться как строка, потому что string является значением по умолчанию для типа .Однако вы получите лучшую возможность фильтрации для пользователей, если вы используете тип : дата . Параметр convert_tz предотвращает двойное преобразование часового пояса. Эта концепция более подробно описана в этой статье Справочного центра.
Вы можете использовать параметр datatype с type: date , чтобы повысить производительность запроса, указав тип данных даты, которые использует ваша таблица базы данных.
type: list создает список различных значений в данном поле.Это похоже на функцию MySQL GROUP_CONCAT .
Нет необходимости включать параметр sql для типа : список мер . Вместо этого вы воспользуетесь параметром list_field , чтобы указать измерение, на основе которого вы хотите создавать списки.
Использование:
view: view_name {
measure: field_name {
type: list
list_field: my_field_name
}
}
Например, следующий LookML создает меру name_list на основе измерения name :
measure: name_list { тип: список list_field: имя }
Обратите внимание на следующее для списка :
- Список
Тип мерыне поддерживает фильтрацию.Вы не можете использовать параметрFiltersдля показателяtype: list. - Список
Тип мерынельзя указать с помощью оператора подстановки ($). Вы не можете использовать синтаксис $ {}для ссылки на меруtype: list.
 Вы не можете использовать синтаксис
Вы не можете использовать синтаксис Поддерживаемые диалекты базы данных для списка
Чтобы Looker поддерживал тип : список в вашем проекте Looker, диалект вашей базы данных также должен его поддерживать. В следующей таблице показано, какие диалекты поддерживают тип : укажите в Looker 21.20:
type: max находит наибольшее значение в заданном поле. Он использует функцию SQL MAX .
Параметр sql для типа : максимум мер может принимать любое допустимое выражение SQL, которое приводит к столбцу числовой таблицы, измерению LookML или комбинации измерений LookML. Он будет работать с датами , а не ; вместо этого см. пример в type: date выше.
Тип : макс. полей могут быть отформатированы с помощью параметров value_format или value_format_name .
Например, следующий LookML создает поле с именем large_order , просматривая измерение sales_price , а затем отображает его в денежном формате (1234,56 доллара США):
measure: large_order { тип: макс sql: $ {sales_price} ;; value_format_name: usd }
В настоящее время вы не можете использовать тип : max мер для строк или дат, но вы можете вручную добавить функцию MAX для создания такого поля, например:
measure: latest_name_in_alphabet { тип: строка sql: MAX ($ {name}) ;; }
тип: median возвращает среднее значение для значений в данном поле.Это особенно полезно, когда в данных есть несколько очень больших или малых выбросов, которые могут исказить простое среднее (среднее) данных.
Рассмотрим такую таблицу:
| Код позиции для заказа | Стоимость | Середина? |
|---|---|---|
| 2 | 10,00 | |
| 4 | 10,00 | |
| 3 | 20,00 | Среднее значение |
| 1 | 80. 00 00 | |
| 5 | 90,00 |
Для удобства просмотра таблица отсортирована по стоимости, но это не влияет на результат. В то время как средний тип вернет 42 (сложение всех значений и деление на 5), тип медианы вернет среднее значение: 20,00.
Если имеется четное количество значений, то среднее значение рассчитывается путем взятия среднего из двух значений, ближайших к средней точке.Рассмотрим такую таблицу с четным числом строк:
| Код позиции для заказа | Стоимость | Середина? |
|---|---|---|
| 2 | 10 | |
| 3 | 20 | Ближайшее до середины |
| 1 | 80 | Ближайшее после середины |
| 4 | 90 |
Медиана, среднее значение, составляет (20 + 80) / 2 = 50 .
Медиана также равна значению 50-го процентиля.
Параметр sql для мер type: median может принимать любое допустимое выражение SQL, которое приводит к столбцу числовой таблицы, измерению LookML или комбинации измерений LookML.
тип: медиана полей можно отформатировать с помощью параметров value_format или value_format_name .
Пример
Например, следующий LookML создает поле с именем median_order путем усреднения измерения sales_price , а затем отображает его в денежном формате ($ 1,234.56):
measure: median_order { тип: срединный sql: $ {sales_price} ;; value_format_name: usd }
Что необходимо учитывать при медиане
Если вы используете median_distinct для поля, участвующего в разветвлении, Looker попытается вместо этого использовать median_distinct . Однако medium_distinct поддерживается только для определенных диалектов. Если
Если median_distinct недоступен для вашего диалекта, Looker возвращает ошибку. Поскольку медиана может считаться 50-м процентилем, ошибка указывает на то, что диалект не поддерживает отдельные процентили.
Поддерживаемые диалекты базы данных для медианы
Для того, чтобы Looker поддерживал средний тип в вашем проекте Looker, диалект вашей базы данных также должен его поддерживать. В следующей таблице показано, какие диалекты поддерживают тип median в Looker 21.20:
Когда в запросе задействовано разветвление, Looker пытается преобразовать медиану в median_distinct . Это успешно только для диалектов, поддерживающих median_distinct .
Используйте type: median_distinct , если ваше соединение включает разветвление. Он усредняет неповторяющиеся значения в данном поле на основе уникальных значений, определенных параметром sql_distinct_key .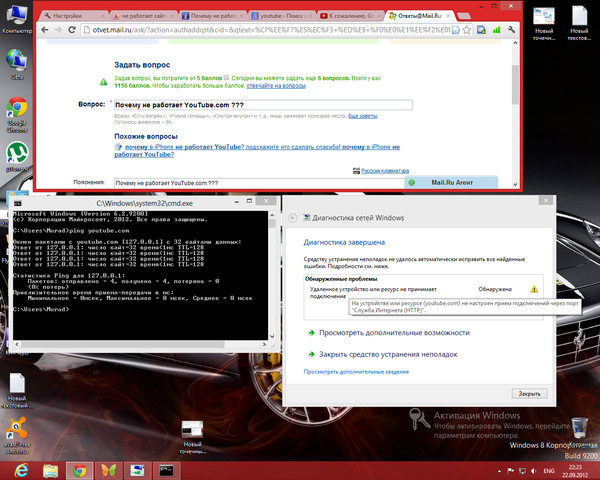 Если у меры нет параметра
Если у меры нет параметра sql_distinct_key , Looker пытается использовать поле primary_key .
Рассмотрим результат запроса, объединяющего таблицы «Позиция заказа» и «Заказ»:
| Код позиции для заказа | Код заказа | Заказать Доставка |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
В этой ситуации вы можете видеть, что для каждого заказа есть несколько строк.Этот запрос включал разветвление, потому что каждый заказ соответствует нескольким элементам заказа.
median_distinct учитывает это и находит медиану между различными значениями 10, 20 и 50, так что вы получите значение 20.
Чтобы получить точный результат, вы можете объяснить Looker, как он должен идентифицировать каждый уникальный объект (в данном случае каждый уникальный порядок), используя параметр sql_distinct_key . Это позволит рассчитать правильную сумму:
measure: median_shipping { тип: median_distinct sql_distinct_key: $ {order_id} ;; sql: $ {order_shipping} ;; }
Обратите внимание, что каждое уникальное значение sql_distinct_key должно иметь только одно соответствующее значение в параметре sql меры.Другими словами, приведенный выше пример работает, потому что каждая строка с order_id из 1 имеет тот же order_shipping из 10, каждая строка с order_id из 2 имеет тот же order_shipping из 20, и скоро.
type: median_distinct полей можно отформатировать с помощью параметров value_format или value_format_name .
Что нужно учитывать для
median_distinct Тип меры medium_distinct поддерживается только для определенных диалектов.Если median_distinct недоступен для диалекта, Looker возвращает ошибку. Поскольку медиана может считаться 50-м процентилем, ошибка указывает на то, что диалект не поддерживает отдельные процентили.
Поддерживаемые диалекты базы данных для
median_distinct Для того, чтобы Looker поддерживал тип median_distinct в вашем проекте Looker, ваш диалект базы данных также должен его поддерживать. В следующей таблице показано, какие диалекты поддерживают тип median_distinct в Looker 21.20:
type: min находит наименьшее значение в заданном поле. Он использует функцию SQL MIN .
Параметр sql для типа : min мер может принимать любое допустимое выражение SQL, которое приводит к столбцу числовой таблицы, измерению LookML или комбинации измерений LookML. Он будет работать с датами , а не ; вместо этого см. пример в
Он будет работать с датами , а не ; вместо этого см. пример в type: date выше.
type: min полей можно отформатировать с помощью параметров value_format или value_format_name .
Например, следующий LookML создает поле с именем smallest_order , просматривая измерение sales_price , а затем отображает его в денежном формате (1234,56 доллара США):
measure: smallest_order { тип: мин sql: $ {sales_price} ;; value_format_name: usd }
В настоящее время вы не можете использовать тип : min мер для строк или дат, но вы можете вручную добавить функцию MIN для создания такого поля, например:
measure: early_name_in_alphabet { тип: строка sql: MIN ($ {name}) ;; }
тип: число используется с числами или целыми числами.Показатель типа : число не выполняет агрегирования и предназначен для выполнения простых преобразований других показателей. Если вы определяете меру на основе другой меры, новая мера должна иметь тип
Если вы определяете меру на основе другой меры, новая мера должна иметь тип : номер , чтобы избежать ошибок вложенной агрегации.
Параметр sql для показателей type: number может принимать любое допустимое выражение SQL, которое дает число или целое число.
тип: число полей можно отформатировать с помощью параметров value_format или value_format_name .
Например, следующий LookML создает показатель с именем total_gross_margin_percentage на основе агрегированных показателей total_sale_price и total_gross_margin , а затем отображает его в процентном формате с двумя десятичными знаками (12,34%):
measure: total_sale_price { тип: сумма value_format_name: usd sql: $ {sale_price} ;; } measure: total_gross_margin { тип: сумма value_format_name: usd sql: $ {ross_margin} ;; } measure: total_gross_margin_percentage { тип: число value_format_name: процент_2 sql: $ {total_gross_margin} / NULLIF ($ {total_sale_price}, 0) ;; }
В приведенном выше примере также используется SQL-функция NULLIF () , чтобы исключить возможность ошибок деления на ноль.
Что нужно учитывать для типа
: номер При использовании типа следует учитывать несколько важных моментов: число меры:
- Мера типа
: числоможет выполнять арифметические действия только с другими мерами, но не с другими измерениями. Симметричные агрегаты - Looker не будут защищать агрегатные функции в SQL типа меры
: числопри вычислении в соединении. - Фильтры
Параметрнельзя использовать с показателями типатип: число, но в документации по фильтрам -
тип: номермеры не будут предлагать пользователям предложения.
type: percent_of_previous вычисляет процентную разницу между ячейкой и предыдущей ячейкой в ее столбце.
Параметр sql для типа : процент_из_предыдущих мер должен ссылаться на другую числовую меру.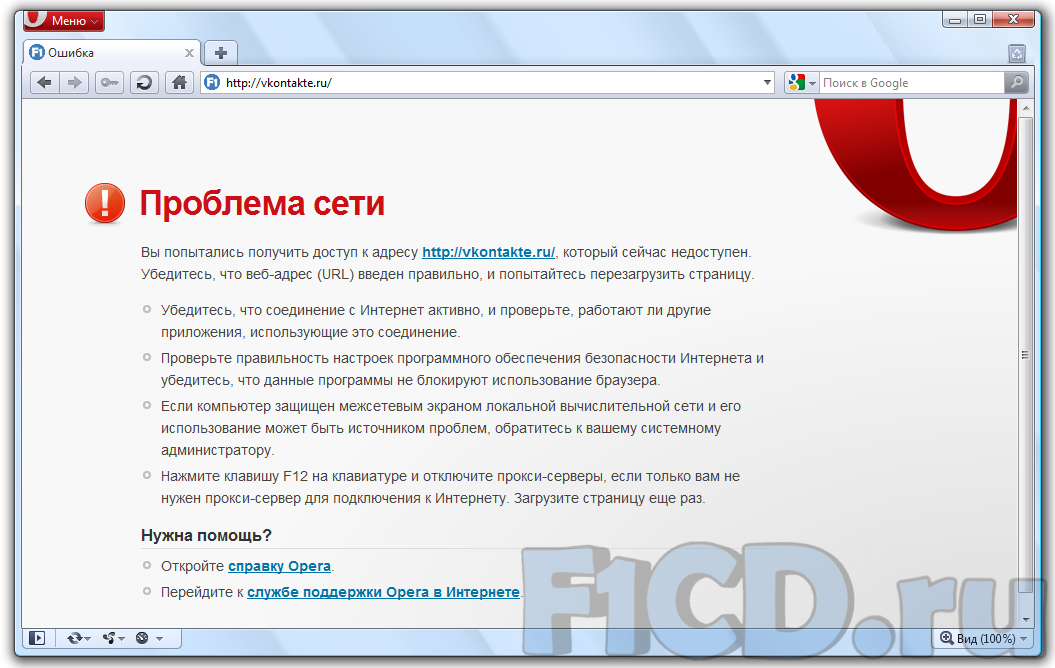
type: percent_of_previous полей можно отформатировать с помощью параметров value_format или value_format_name .Однако процентные форматы параметра value_format_name не работают с мерами типа : percent_of_previous . Эти процентные форматы умножают значения на 100, что искажает результаты предыдущего вычисления в процентах.
В следующем примере этот LookML создает меру count_growth на основе меры count :
measure: count_growth { тип: percent_of_previous sql: $ {count} ;; }
В пользовательском интерфейсе Looker это будет выглядеть так:
Обратите внимание, что процентов_из_предыдущих значений зависят от порядка сортировки.Если вы измените сортировку, необходимо повторно запустить запрос, чтобы пересчитать процентов_предыдущих значений . В случаях, когда запрос вращается, percent_of_previous выполняется по строке, а не по столбцу. В настоящее время вы не можете изменить это поведение.
В настоящее время вы не можете изменить это поведение.
Кроме того, процентов_из_предыдущих показателей вычисляются после того, как данные возвращаются из вашей базы данных. Это означает, что вы не должны ссылаться на меру percent_of_previous внутри другой меры; поскольку они могут быть рассчитаны в разное время, вы можете не получить точных результатов.Это также означает, что процентов_из_предыдущих показателей не могут быть отфильтрованы.
type: percent_of_total вычисляет долю ячейки от итога столбца. Процент рассчитывается относительно общего количества строк, возвращенных вашим запросом, а , а не , - от общего количества всех возможных строк. Однако, если данные, возвращаемые вашим запросом, превышают ограничение на количество строк, значения поля будут отображаться как пустые, поскольку для вычисления процента от общего количества требуются полные результаты.
Параметр sql для типа : percent_of_total мер должен ссылаться на другую числовую меру.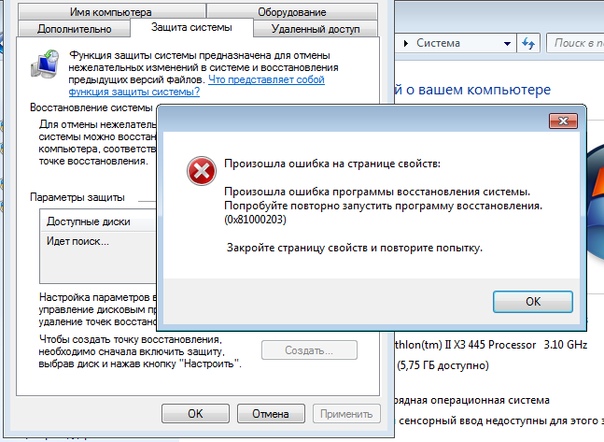
type: percent_of_total полей можно отформатировать с помощью параметров value_format или value_format_name . Однако процентные форматы параметра value_format_name не работают с мерами типа : percent_of_total . Эти процентные форматы умножают значения на 100, что искажает результаты вычисления процент_полного_общего .
В следующем примере этот LookML создает меру percent_of_total_gross_margin на основе меры total_gross_margin :
measure: percent_of_total_gross_margin { тип: percent_of_total sql: $ {total_gross_margin} ;; }
В пользовательском интерфейсе Looker это будет выглядеть так:
В тех случаях, когда запрос вращается, percent_of_total выполняется по строке, а не по столбцу. Если это нежелательно, добавьте direction: "column" к определению меры.
Кроме того, percent_of_total мер вычисляются после того, как данные возвращены из вашей базы данных. Это означает, что вы не должны ссылаться на меру
Это означает, что вы не должны ссылаться на меру percent_of_total внутри другой меры; поскольку они могут быть рассчитаны в разное время, вы можете не получить точных результатов. Это также означает, что percent_of_total мер не могут быть отфильтрованы.
тип: процентиль возвращает значение в указанном процентиле значений в данном поле.Например, указание 75-го процентиля вернет значение, превышающее 75% других значений в наборе данных.
Чтобы определить возвращаемое значение, Looker вычисляет общее количество значений данных и умножает указанный процентиль на общее количество значений данных. Независимо от того, как данные фактически сортируются, Looker определяет относительный порядок значений данных по возрастанию. Значение данных, возвращаемое Looker, зависит от того, дает ли результат вычисления целое число или нет, как обсуждается ниже.
Если вычисленное значение не является целым числом
Looker округляет вычисленное значение в большую сторону и использует его для определения возвращаемого значения данных. В этом примере набора из 19 результатов тестов 75-й процентиль будет обозначен как 19 * 0,75 = 14,25, что означает, что 75% значений находятся в первых 14 значениях данных - ниже 15-й позиции. Таким образом, Looker возвращает 15-е значение данных (87), превышающее 75% значений данных.
В этом примере набора из 19 результатов тестов 75-й процентиль будет обозначен как 19 * 0,75 = 14,25, что означает, что 75% значений находятся в первых 14 значениях данных - ниже 15-й позиции. Таким образом, Looker возвращает 15-е значение данных (87), превышающее 75% значений данных.
Если вычисленное значение является целым числом
В этом немного более сложном случае Looker возвращает среднее значение данных в этой позиции и следующее значение данных.Чтобы понять это, рассмотрим набор из 20 результатов тестов, 75-й процентиль будет идентифицирован как 20 * 0,75 = 15, что означает, что значение данных на 15-й позиции является частью 75-го процентиля, и нам нужно вернуть значение, которое выше 75% значений данных. Возвращая среднее значение 15-й позиции (82) и 16-й позиции (87), Looker обеспечивает это 75%. Это среднее (84,5) не существует в наборе значений данных, но будет больше 75% значений данных.
Обязательные и необязательные параметры
Используйте ключевое слово процентиль: , чтобы указать дробное значение, то есть процент данных, которые должны быть ниже возвращаемого значения. Например, используйте
Например, используйте процентиль: 75 , чтобы указать значение на 75-м процентиле в порядке данных, или процентиль: 10 , чтобы вернуть значение на 10-м процентиле. Если вы хотите найти значение в 50-м процентиле, вы можете указать процентиль: 50 или просто использовать тип медианы.
Параметр sql для мер типа : процентиль может принимать любое допустимое выражение SQL, которое приводит к столбцу числовой таблицы, измерению LookML или комбинации измерений LookML.
тип: процентиль полей можно отформатировать с помощью параметров value_format или value_format_name .
Пример
Например, следующий LookML создает поле с именем test_scores_75th_percentile , которое возвращает значение на 75-м процентиле в измерении test_scores :
measure: test_scores_75th_percentile {
тип: процентиль
процентиль: 75
sql: $ {ТАБЛИЦА}. результаты теста ;;
}
результаты теста ;;
}
Что нужно учитывать при
процентиле Если вы используете процентиль для поля, участвующего в разветвлении, Looker попытается вместо этого использовать percentile_distinct . Если percentile_distinct недоступен для диалекта, Looker возвращает ошибку. Для получения дополнительной информации см. Поддерживаемые диалекты для percentile_distinct .
Поддерживаемые диалекты базы данных для
процентилей Для того, чтобы Looker поддерживал тип процентиля в вашем проекте Looker, диалект вашей базы данных также должен его поддерживать.В следующей таблице показано, какие диалекты поддерживают тип процентиля в Looker 21.20:
Тип : percentile_distinct - это специализированная форма процентиля, которую следует использовать, когда ваше соединение включает разветвление. Он использует неповторяющиеся значения в данном поле на основе уникальных значений, определенных параметром sql_distinct_key . Если у меры нет параметра
Если у меры нет параметра sql_distinct_key , Looker пытается использовать поле primary_key .
Рассмотрим результат запроса, объединяющего таблицы «Позиция заказа» и «Заказ»:
| Код позиции для заказа | Код заказа | Заказать Доставка |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
В этой ситуации вы можете видеть, что для каждого заказа есть несколько строк. Этот запрос включал разветвление, потому что каждый заказ соответствует нескольким элементам заказа.
Этот запрос включал разветвление, потому что каждый заказ соответствует нескольким элементам заказа. percentile_distinct учитывает это и находит значение процентиля, используя различные значения 10, 20, 50, 70 и 110. 25-й процентиль вернет второе отличное значение или 20, а 80-й процентиль вернет среднее значение четвертое и пятое различные значения, или 90.
Обязательные и необязательные параметры
Используйте ключевое слово процентиль: , чтобы указать дробное значение.Например, используйте процентиль: 75 , чтобы указать значение на 75-м процентиле в порядке данных, или процентиль: 10 , чтобы вернуть значение на 10-м процентиле. Если вы пытаетесь найти значение на 50-м процентиле, вы можете вместо этого использовать тип median_distinct .
Чтобы получить точный результат, укажите, как Looker должен идентифицировать каждый уникальный объект (в данном случае каждый уникальный порядок) с помощью параметра sql_distinct_key .
Вот пример использования percentile_distinct для возврата значения на 90-м процентиле:
measure: order_shipping_90th_percentile { тип: percentile_distinct процентиль: 90 sql_distinct_key: $ {order_id} ;; sql: $ {order_shipping} ;; }
Обратите внимание, что каждое уникальное значение sql_distinct_key должно иметь только одно соответствующее значение в параметре sql меры.Другими словами, приведенный выше пример работает, потому что каждая строка с order_id из 1 имеет тот же order_shipping из 10, каждая строка с order_id из 2 имеет тот же order_shipping из 20, и так на.
type: percentile_distinct полей можно отформатировать с помощью параметров value_format или value_format_name .
Что нужно учитывать для
percentile_distinct Если percentile_distinct недоступен для диалекта, Looker возвращает ошибку. Для получения дополнительной информации см. Поддерживаемые диалекты для
Для получения дополнительной информации см. Поддерживаемые диалекты для percentile_distinct .
Поддерживаемые диалекты базы данных для
percentile_distinct Для того, чтобы Looker поддерживал тип percentile_distinct в вашем проекте Looker, ваш диалект базы данных также должен его поддерживать. В следующей таблице показано, какие диалекты поддерживают тип percentile_distinct в Looker 21.20:
type: running_total вычисляет совокупную сумму ячеек по столбцу.Его нельзя использовать для расчета сумм по строке, если только строка не является результатом поворота.
Параметр sql для типа : running_total мер должен ссылаться на другой числовой показатель.
type: running_total полей можно отформатировать с помощью параметров value_format или value_format_name .
Например, следующий LookML создает показатель cumulative_total_revenue на основе показателя total_sale_price :
measure: cumulative_total_revenue { тип: running_total sql: $ {total_sale_price} ;; value_format_name: usd }
В пользовательском интерфейсе Looker это будет выглядеть так:
Обратите внимание, что running_total значений зависят от порядка сортировки. Если вы измените сортировку, необходимо повторно запустить запрос, чтобы повторно вычислить
Если вы измените сортировку, необходимо повторно запустить запрос, чтобы повторно вычислить running_total значений. В случаях, когда запрос вращается, running_total выполняется по строке, а не по столбцу. Если это нежелательно, добавьте direction: "column" к определению меры.
Кроме того, running_total мер вычисляются после того, как данные возвращены из вашей базы данных. Это означает, что вы не должны ссылаться на меру running_total внутри другой меры; поскольку они могут быть рассчитаны в разное время, вы можете не получить точных результатов.Это также означает, что running_total мер не могут быть отфильтрованы.
тип: строка используется с полями, содержащими буквы или специальные символы.
Параметр sql для тип: строка меры могут принимать любое допустимое выражение SQL, которое приводит к строке. На практике этот тип используется редко, поскольку большинство агрегатных функций SQL не возвращают строки. Одним из распространенных исключений является функция MySQL
Одним из распространенных исключений является функция MySQL GROUP_CONCAT , хотя Looker предоставляет type: list для этого варианта использования.
Например, следующий LookML создает поле category_list путем объединения уникальных значений поля с именем category :
measure: category_list { тип: строка sql: GROUP_CONCAT ($ {category}) ;; }
В этом примере тип: строка можно опустить, потому что строка является значением по умолчанию для типа .
тип: сумма складывает значения в данном поле. Это похоже на функцию SQL СУММ .Однако, в отличие от написания необработанного SQL, Looker будет правильно вычислять суммы, даже если соединения вашего запроса содержат разветвления.
Параметр sql для мер type: sum может принимать любое допустимое выражение SQL, которое приводит к столбцу числовой таблицы, измерению LookML или комбинации измерений LookML.
тип: сумма полей можно отформатировать с помощью параметров value_format или value_format_name .
Например, следующий LookML создает поле с именем total_revenue путем добавления измерения sales_price , а затем отображает его в денежном формате ($ 1,234.56):
measure: total_revenue { тип: сумма sql: $ {sales_price} ;; value_format_name: usd }
type: sum_distinct предназначен для использования с денормализованными наборами данных. Он складывает неповторяющиеся значения в данном поле на основе уникальных значений, определенных параметром sql_distinct_key .
Это продвинутая концепция, которую можно более четко пояснить на примере. Рассмотрим денормализованную таблицу, подобную этой:
| Код позиции для заказа | Номер заказа | Заказать Доставка |
|---|---|---|
| 1 | 1 | 10. 00 00 |
| 2 | 1 | 10,00 |
| 3 | 2 | 20,00 |
| 4 | 2 | 20,00 |
| 5 | 2 | 20,00 |
В этой ситуации вы можете видеть, что для каждого заказа есть несколько строк. Следовательно, если вы добавите простой показатель типа : сумма для столбца order_shipping , вы получите в сумме 80.00, хотя на самом деле общая собранная стоимость доставки составляет 30,00.
# НЕ будет рассчитывать правильную сумму доставки measure: total_shipping { тип: сумма sql: $ {order_shipping} ;; }
Чтобы получить точный результат, вы можете объяснить Looker, как он должен идентифицировать каждый уникальный объект (в данном случае каждый уникальный порядок), используя параметр sql_distinct_key . Этот будет вычислить правильную сумму 30,00:
Этот будет вычислить правильную сумму 30,00:
# Подсчитает правильную сумму доставки measure: total_shipping { тип: sum_distinct sql_distinct_key: $ {order_id} ;; sql: $ {order_shipping} ;; }
Обратите внимание, что каждое уникальное значение sql_distinct_key должно иметь только одно соответствующее значение в sql .Другими словами, приведенный выше пример работает, потому что каждая строка с order_id из 1 имеет тот же order_shipping из 10,00, каждая строка с order_id из 2 имеет тот же order_shipping из 20,00, и скоро.
type: sum_distinct полей можно отформатировать с помощью параметров value_format или value_format_name .
тип: yesno создает поле, которое указывает, является ли что-то истинным или ложным.Значения отображаются как Да и Нет в пользовательском интерфейсе исследования.
Параметр sql для типа : да нет мера принимает допустимое выражение SQL, которое принимает значение ИСТИНА, или ЛОЖЬ, . Если условие оценивается как ИСТИНА , Да отображается пользователю; в противном случае отображается № .
Выражение SQL для типа : yesno меры должны включать только агрегаты, что означает агрегаты SQL или ссылки на меры LookML.Если вы хотите создать поле yesno , которое включает ссылку на измерение LookML или выражение SQL, которое не является агрегацией, используйте измерение с типом : yesno , а не мерой.
Подобно мерам с типом : число , мера с типом : да, нет не выполняет агрегирования; он просто ссылается на другие агрегаты.
Например, показатель total_sale_price ниже представляет собой сумму общей продажной цены позиций заказа в заказе. Вторая мера под названием
Вторая мера под названием is_large_total - это , тип: yesno . Мера is_large_total имеет параметр sql , который определяет, превышает ли значение total_sale_price 1000 долларов США.
measure: total_sale_price { тип: сумма value_format_name: usd sql: $ {sale_price} ;; Drill_fields: [деталь *] } measure: is_large_total { описание: "Сумма заказа превышает 1000 долларов?" тип: да нет sql: $ {total_sale_price}> 1000 ;; }
Если вы хотите сослаться на поле type: yesno в другом поле, вы должны рассматривать поле type: yesno как логическое (другими словами, как если бы оно уже содержало истинное или ложное значение).Например:
measure: is_large_total { описание: "Сумма заказа превышает 1000 долларов?" тип: да нет sql: $ {total_sale_price}> 1000 ;; } } # Это верно measure: reward_points { тип: число sql: CASE WHEN $ {is_large_total} THEN 200 ELSE 100 END ;; } # Это НЕ правильно measure: reward_points { тип: число sql: CASE WHEN $ {is_large_total} = 'Yes' THEN 200 ELSE 100 END ;; }
часто задаваемых вопросов по Amazon SageMaker - Amazon Web Services (AWS)
Вопрос: Что такое эксперименты Amazon SageMaker?
Amazon SageMaker Experiments помогает организовать и отслеживать итерации моделей машинного обучения. SageMaker Experiments помогает управлять итерациями, автоматически собирая входные параметры, конфигурации и результаты и сохраняя их как «эксперименты». Вы можете работать в визуальном интерфейсе SageMaker Studio, где вы можете просматривать активные эксперименты, искать предыдущие эксперименты по их характеристикам, просматривать предыдущие эксперименты с их результатами и сравнивать результаты экспериментов визуально.
SageMaker Experiments помогает управлять итерациями, автоматически собирая входные параметры, конфигурации и результаты и сохраняя их как «эксперименты». Вы можете работать в визуальном интерфейсе SageMaker Studio, где вы можете просматривать активные эксперименты, искать предыдущие эксперименты по их характеристикам, просматривать предыдущие эксперименты с их результатами и сравнивать результаты экспериментов визуально.
Вопрос: Что такое отладчик Amazon SageMaker?
Amazon SageMaker Debugger автоматически фиксирует в реальном времени метрики во время обучения, такие как матрицы путаницы и обучающие градиенты, чтобы повысить точность модели.Показатели из SageMaker Debugger можно визуализировать в SageMaker Studio для облегчения понимания. SageMaker Debugger также может генерировать предупреждения и рекомендации по устранению неполадок при обнаружении распространенных проблем с обучением. SageMaker Debugger также автоматически отслеживает и профилирует системные ресурсы, такие как процессоры, графические процессоры, сеть и память, в режиме реального времени и предоставляет рекомендации по перераспределению этих ресурсов. Это позволяет вам эффективно использовать свои ресурсы во время обучения и помогает снизить затраты и ресурсы.
Это позволяет вам эффективно использовать свои ресурсы во время обучения и помогает снизить затраты и ресурсы.
Вопрос: Поддерживает ли Amazon SageMaker распределенное обучение?
Да. Amazon SageMaker может автоматически распределять модели глубокого обучения и большие обучающие наборы по инстансам AWS с графическим процессором за долю времени, необходимого для создания и оптимизации этих стратегий распределения вручную. SageMaker применяет два метода распределенного обучения: параллелизм данных и параллелизм моделей. Параллелизм данных применяется для повышения скорости обучения за счет равномерного разделения данных между несколькими экземплярами графического процессора, что позволяет каждому экземпляру обучаться одновременно.Параллелизм моделей полезен для моделей, слишком больших для хранения на одном графическом процессоре, и требует, чтобы модель была разделена на более мелкие части перед распределением по нескольким графическим процессорам. Имея всего несколько строк дополнительного кода в ваших обучающих скриптах PyTorch и TensorFlow, SageMaker автоматически применит параллелизм данных или параллелизм моделей, что позволит вам быстрее разрабатывать и развертывать модели. SageMaker определит лучший подход к разделению вашей модели, используя алгоритмы разделения графа, чтобы сбалансировать вычисления каждого графического процессора, минимизируя обмен данными между экземплярами графического процессора.SageMaker также оптимизирует ваши распределенные учебные задания с помощью алгоритмов, которые полностью используют вычислительные ресурсы и сеть AWS для достижения почти линейной эффективности масштабирования, что позволяет выполнять обучение быстрее, чем ручные реализации с открытым исходным кодом.
Имея всего несколько строк дополнительного кода в ваших обучающих скриптах PyTorch и TensorFlow, SageMaker автоматически применит параллелизм данных или параллелизм моделей, что позволит вам быстрее разрабатывать и развертывать модели. SageMaker определит лучший подход к разделению вашей модели, используя алгоритмы разделения графа, чтобы сбалансировать вычисления каждого графического процессора, минимизируя обмен данными между экземплярами графического процессора.SageMaker также оптимизирует ваши распределенные учебные задания с помощью алгоритмов, которые полностью используют вычислительные ресурсы и сеть AWS для достижения почти линейной эффективности масштабирования, что позволяет выполнять обучение быстрее, чем ручные реализации с открытым исходным кодом.
Вопрос: Что такое обучающий компилятор SageMaker?
Amazon SageMaker Training Compiler - это компилятор глубокого обучения (DL), который ускоряет обучение модели DL до 50 процентов за счет оптимизации на уровне графа и ядра для более эффективного использования графических процессоров. Training Compiler интегрирован с версиями TensorFlow и PyTorch в SageMaker, поэтому вы можете ускорить обучение в этих популярных фреймворках с минимальными изменениями кода.
Training Compiler интегрирован с версиями TensorFlow и PyTorch в SageMaker, поэтому вы можете ускорить обучение в этих популярных фреймворках с минимальными изменениями кода.
Q: Как работает обучающий компилятор SageMaker?
SageMaker Training Compiler ускоряет учебные задания за счет преобразования моделей DL из их высокоуровневого языкового представления в оптимизированные для оборудования инструкции, которые обучаются быстрее, чем задания с собственными фреймворками. В частности, SageMaker Training Compiler использует оптимизацию на уровне графа (объединение операторов, планирование памяти и алгебраическое упрощение), оптимизацию на уровне потока данных (преобразование макета, устранение общих подвыражений) и внутреннюю оптимизацию (сокрытие задержки памяти, ориентированное на цикл optimizations) для создания оптимизированной задачи обучения модели, которая более эффективно использует аппаратные ресурсы и, как следствие, быстрее обучается.
Q: Как я могу использовать обучающий компилятор SageMaker?
Amazon SageMaker Training Compiler встроен в SageMaker Python SDK и SageMaker Hugging Face Deep Learning Containers. Вам не нужно менять рабочие процессы, чтобы воспользоваться преимуществами ускорения. Вы можете выполнять задания по обучению так же, как и раньше, используя любой из интерфейсов SageMaker: экземпляры Amazon SageMaker Notebook, SageMaker Studio, AWS SDK для Python (Boto3) и интерфейс командной строки AWS.Вы можете включить обучающий компилятор SageMaker, добавив класс TrainingCompilerConfig в качестве параметра при создании объекта оценки платформы. На практике это означает добавление пары строк кода к существующему сценарию учебного задания для одного экземпляра графического процессора. Самая последняя подробная документация, образцы записных книжек и примеры доступны в документации.
Вам не нужно менять рабочие процессы, чтобы воспользоваться преимуществами ускорения. Вы можете выполнять задания по обучению так же, как и раньше, используя любой из интерфейсов SageMaker: экземпляры Amazon SageMaker Notebook, SageMaker Studio, AWS SDK для Python (Boto3) и интерфейс командной строки AWS.Вы можете включить обучающий компилятор SageMaker, добавив класс TrainingCompilerConfig в качестве параметра при создании объекта оценки платформы. На практике это означает добавление пары строк кода к существующему сценарию учебного задания для одного экземпляра графического процессора. Самая последняя подробная документация, образцы записных книжек и примеры доступны в документации.
Q: Какова стоимость обучающего компилятора SageMaker?
Training Compiler - это функция обучения SageMaker, которая бесплатно предоставляется исключительно клиентам SageMaker.Заказчики могут фактически снизить свои расходы с помощью Training Compiler, поскольку время обучения сокращается на
.
Вопрос: Что такое управляемое спотовое обучение?
Управляемое спотовое обучениес помощью Amazon SageMaker позволяет обучать модели машинного обучения с помощью спотовых инстансов Amazon EC2, снижая при этом затраты на обучение моделей до 90%.
Q: Как использовать управляемое спотовое обучение?
Вы включаете опцию «Управляемое спотовое обучение» при отправке заданий на обучение, а также указываете, как долго вы хотите ждать спотовой мощности.Затем Amazon SageMaker будет использовать спотовые инстансы Amazon EC2 для выполнения ваших заданий и управления спотовой емкостью. У вас есть полная информация о статусе вашего учебного задания, как во время его выполнения, так и во время ожидания загрузки.
В. Когда следует использовать управляемое спотовое обучение?
Управляемое спотовое обучение идеально подходит, когда у вас есть гибкость при проведении тренировок и когда вы хотите минимизировать затраты на обучение. С помощью управляемого спотового обучения вы можете снизить затраты на обучение моделей машинного обучения до 90%.
С помощью управляемого спотового обучения вы можете снизить затраты на обучение моделей машинного обучения до 90%.
Q: Как работает управляемое спотовое обучение?
ВManaged Spot Training используются спотовые инстансы Amazon EC2 для обучения, и эти инстансы можно предварительно освободить, когда AWS потребуются ресурсы. В результате задания управляемого спотового обучения могут выполняться небольшими приращениями по мере того, как становятся доступными ресурсы. В случае прерывания учебные задания не нужно начинать с нуля, так как Amazon SageMaker может возобновить учебные задания, используя контрольную точку последней модели.Встроенные фреймворки и встроенные алгоритмы компьютерного зрения с SageMaker позволяют использовать периодические контрольные точки, и вы можете включить контрольные точки с помощью пользовательских моделей.
Q: Нужно ли мне периодически проходить контрольную точку с управляемым спотовым обучением?
Мы рекомендуем периодические контрольные точки как общую лучшую практику для длительных тренировок.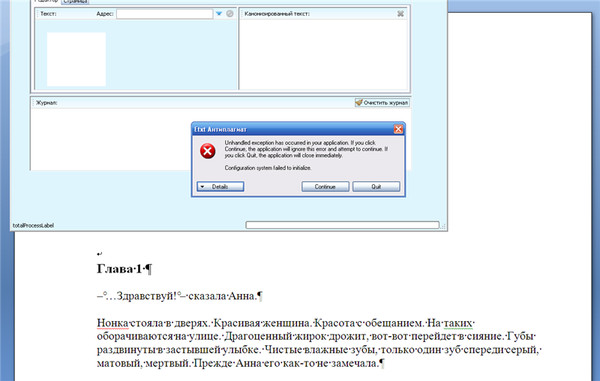 Это предотвратит перезапуск заданий управляемого спотового обучения, если ресурсы будут заполнены заранее. Когда вы включаете контрольные точки, Amazon SageMaker возобновляет ваши задания по управляемому спотовому обучению с последней контрольной точки.
Это предотвратит перезапуск заданий управляемого спотового обучения, если ресурсы будут заполнены заранее. Когда вы включаете контрольные точки, Amazon SageMaker возобновляет ваши задания по управляемому спотовому обучению с последней контрольной точки.
Q: Как вы рассчитываете экономию затрат с помощью заданий управляемого спотового обучения?
После завершения задания управляемого спотового обучения вы можете увидеть экономию в консоли управления AWS, а также рассчитать экономию затрат как процентную разницу между продолжительностью, в течение которой выполнялось задание по обучению, и продолжительностью, за которую вам был выставлен счет.
Независимо от того, сколько раз ваши задания по управляемому спотовому обучению прерывались, с вас взимается только один раз за время, в течение которого были загружены данные.
В. Какие инстансы можно использовать с управляемым спотовым обучением?
Managed Spot Training можно использовать со всеми инстансами, поддерживаемыми в Amazon SageMaker.
Вопрос: Какие регионы AWS поддерживаются управляемым спотовым обучением?
Managed Spot Training поддерживается во всех регионах AWS, где в настоящее время доступен Amazon SageMaker.
Q: Существуют ли ограничения на размер набора данных, который я могу использовать для обучения?
Не существует фиксированных ограничений на размер набора данных, который можно использовать для обучения моделей с помощью Amazon SageMaker.
Вопрос: Какие алгоритмы использует Amazon SageMaker для создания моделей?
Amazon SageMaker включает встроенные алгоритмы для линейной регрессии, логистической регрессии, кластеризации k-средних, анализа главных компонентов, факторизационных машин, нейронного тематического моделирования, латентного распределения дирихле, деревьев с градиентным усилением, sequence2sequence, прогнозирования временных рядов, word2vec и классификации изображений. . SageMaker также предоставляет оптимизированные контейнеры Apache MXNet, Tensorflow, Chainer, PyTorch, Gluon, Keras, Horovod, Scikit-learn и Deep Graph Library. Кроме того, Amazon SageMaker поддерживает пользовательские алгоритмы обучения, предоставляемые с помощью образа Docker в соответствии с задокументированной спецификацией.
Кроме того, Amazon SageMaker поддерживает пользовательские алгоритмы обучения, предоставляемые с помощью образа Docker в соответствии с задокументированной спецификацией.
Q: Что такое автоматическая настройка модели?
Большинство алгоритмов машинного обучения предоставляют множество параметров, которые контролируют работу базового алгоритма. Эти параметры обычно называют гиперпараметрами, и их значения влияют на качество обученных моделей. Автоматическая настройка модели - это процесс поиска набора гиперпараметров для алгоритма, который может дать оптимальную модель.
Q: Какие модели можно настроить с помощью автоматической настройки модели?
Вы можете запустить автоматическую настройку модели в Amazon SageMaker поверх любого алгоритма, если это возможно с научной точки зрения, включая встроенные алгоритмы SageMaker, глубокие нейронные сети или произвольные алгоритмы, которые вы передаете в SageMaker в виде образов Docker.
Вопрос: Могу ли я использовать автоматическую настройку модели вне Amazon SageMaker?
Не сейчас.Наилучшая производительность и удобство настройки модели - в Amazon SageMaker.
Q: Каков основной алгоритм настройки?
В настоящее время наш алгоритм настройки гиперпараметров представляет собой индивидуализированную реализацию байесовской оптимизации. Он направлен на оптимизацию целевой метрики, указанной заказчиком, на протяжении всего процесса настройки. В частности, он проверяет объектную метрику выполненных учебных заданий и использует полученные знания для вывода комбинации гиперпараметров для следующего учебного задания.
Q: Вы порекомендуете конкретные гиперпараметры для настройки?
Нет. То, как определенные гиперпараметры влияют на производительность модели, зависит от различных факторов, и трудно однозначно сказать, что один гиперпараметр важнее других и, следовательно, требует настройки.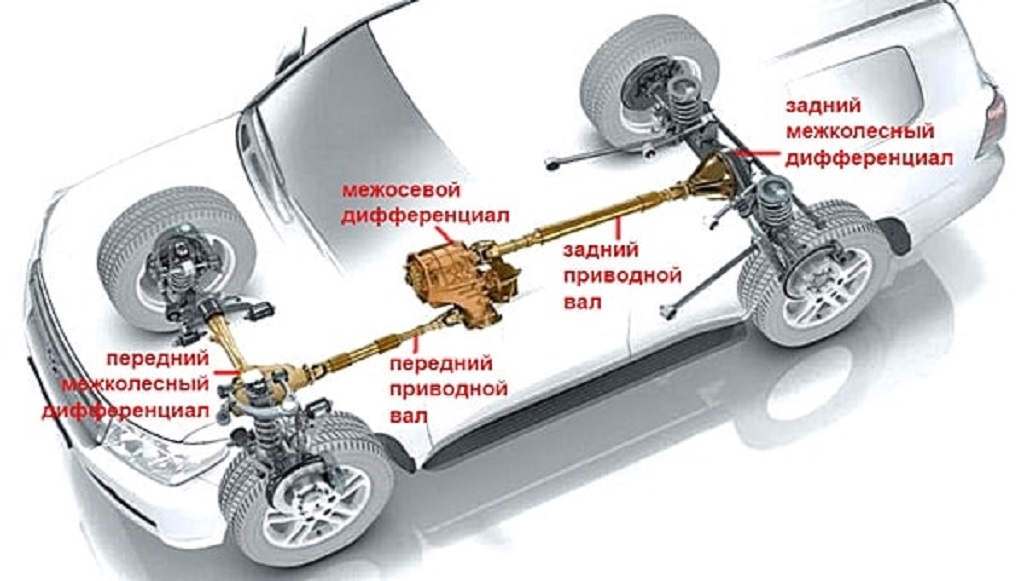 Для встроенных в Amazon SageMaker алгоритмов мы выясняем, настраивается ли гиперпараметр.
Для встроенных в Amazon SageMaker алгоритмов мы выясняем, настраивается ли гиперпараметр.
Вопрос: Сколько времени занимает настройка гиперпараметров?
Продолжительность задания по настройке гиперпараметров зависит от множества факторов, включая размер данных, базовый алгоритм и значения гиперпараметров.Кроме того, клиенты могут выбрать количество одновременных учебных заданий и общее количество учебных заданий. Все эти варианты влияют на то, как долго может длиться работа по настройке гиперпараметров.
Q: Могу ли я оптимизировать несколько объективов одновременно, как модель, чтобы она была быстрой и точной?
Не сейчас. Прямо сейчас вам нужно указать единую объективную метрику, чтобы оптимизировать или изменить код вашего алгоритма, чтобы выдать новую метрику, которая представляет собой средневзвешенное значение между двумя или более полезными метриками, и оптимизировать процесс настройки в соответствии с этой объективной метрикой.
Q: Сколько стоит автоматическая настройка модели?
Сама настройка гиперпараметров бесплатна. С вас будет взиматься плата за учебные задания, запускаемые заданием настройки гиперпараметров, на основе цен на обучение модели.
Вопрос: Как мне выбрать использование автопилота Amazon SageMaker или автоматической настройки модели?
Amazon SageMaker Autopilot автоматизирует все в типичном рабочем процессе машинного обучения, включая предварительную обработку функций, выбор алгоритма и настройку гиперпараметров, уделяя особое внимание сценариям использования классификации и регрессии.С другой стороны, автоматическая настройка модели предназначена для настройки любой модели, независимо от того, основана ли она на встроенных алгоритмах, фреймворках глубокого обучения или пользовательских контейнерах. В обмен на гибкость вы должны вручную выбрать конкретный алгоритм, определить гиперпараметры для настройки и соответствующие диапазоны поиска.
Вопрос: Что такое обучение с подкреплением?
Обучение с подкреплением - это метод машинного обучения, который позволяет агенту учиться в интерактивной среде методом проб и ошибок, используя обратную связь по своим действиям и опыту.
Вопрос: Могу ли я обучать модели обучения с подкреплением в Amazon SageMaker?
Да, вы можете обучать модели обучения с подкреплением в Amazon SageMaker в дополнение к контролируемым и неконтролируемым моделям обучения.
Вопрос: Чем обучение с подкреплением отличается от обучения с учителем?
Хотя как контролируемое обучение, так и обучение с подкреплением используют сопоставление между вводом и выводом, в отличие от контролируемого обучения, когда обратная связь, предоставляемая агенту, представляет собой правильный набор действий для выполнения задачи, обучение с подкреплением использует отложенную обратную связь, где сигналы вознаграждения оптимизированы для обеспечения длительного срок цели через последовательность действий.
Вопрос: Когда следует использовать обучение с подкреплением?
В то время как цель методов обучения с учителем - найти правильный ответ на основе закономерностей в данных обучения, цель методов обучения без учителя - найти сходства и различия между точками данных. Напротив, цель методов обучения с подкреплением (RL) - научиться достигать желаемого результата, даже если неясно, как этого добиться. В результате RL больше подходит для включения интеллектуальных приложений, в которых агент может принимать автономные решения, например, в робототехнике, автономных транспортных средствах, HVAC, промышленном управлении и т. Д.
Вопрос: Какие среды я могу использовать для обучения моделей обучения с подкреплением?
Amazon SageMaker RL поддерживает ряд различных сред для обучения моделей обучения с подкреплением. Вы можете использовать сервисы AWS, такие как AWS RoboMaker, среды с открытым исходным кодом или пользовательские среды, разработанные с использованием интерфейсов Open AI Gym, или коммерческие среды моделирования, такие как MATLAB и SimuLink.
Вопрос: Нужно ли мне писать собственные алгоритмы агента RL для обучения моделей обучения с подкреплением?
Нет, Amazon SageMaker RL включает наборы инструментов RL, такие как Coach и Ray RLLib, которые предлагают реализации алгоритмов агентов RL, таких как DQN, PPO, A3C и многие другие.
Вопрос: Могу ли я принести свои собственные библиотеки RL и реализацию алгоритма и запустить их в Amazon SageMaker RL?
Да, вы можете использовать свои собственные библиотеки RL и реализации алгоритмов в контейнерах Docker и запускать их в Amazon SageMaker RL.
Вопрос: Могу ли я выполнять распределенное развертывание с помощью Amazon SageMaker RL?
Да. Вы даже можете выбрать гетерогенный кластер, в котором обучение может выполняться на экземпляре графического процессора, а моделирование может выполняться на нескольких экземплярах процессора.
