Голосовое приветствие за 5 минут
Как много названий для одной функции — функции воспроизведения заранее подготовленной аудио информации посредством каналов связи. Именно создать текст голосового приветствия, озвучить его онлайн и получить аудио файл призван данный сервис — Аудиоконструктор.рф.
Создать голосовое приветствие, прослушать, убедиться, что оно вам подходит, получить ссылку на подготовленный проект — все это можно бесплатно. Вы можете показать получившееся голосовое приветствие вашим знакомым, коллегам, руководителю отдела или директору. По необходимости, можете совершенно бесплатно в любой момент внести коррективы. И оплатить в самом конце для получения результата в виде готового к использованию аудиофайла голосового приветствия.
Суть сервиса по конструированию аудио файлов приветствий, IVR-меню и пр. гениально проста: из фраз, складывается индивидуальный текст, который озвучивается онлайн голосом профессионального диктора. Каждая фраза озвучена заранее на качественном студийном оборудовании.
Но это еще не все! Из, определенным образом подготовленных, музыкальных фрагментов складывается оригинальный музыкальный фон, который в свою очередь накладывается на составленное голосовое сообщение.
При этом имеются следующие возможности:
- выбор диктора и интонационных вариантов фраз,
- использование заранее подготовленных шаблонов со всеми настроками,
- регулирование времени начала звучания голоса, пауз между фразами,
- легкое удаление и замена фраз,
- огромное количество вариантов фраз и музыкальных фрагментов,
- гибкая настройка громкости музыкального фона
- и самое главное — генерация и прослушивание получившегося аудио файла голосового приветствия в онлайн режиме.
Испытайте все эти возможности прямо сейчас и убедитесь в этом совершенно бесплатно.
Бесплатное тестирование аудио конструктора — онлайн генератора голосовых приветствий является наглядным и убедительным доказательством его возможностей.
Вы испытываете сервис, составляете свое голосовое приветствие так, как вам требуется, слушаете, как оно звучит и только тогда принимаете решение заказать, т.е., купить.
Вводите адрес своей электронной почты и получаете ссылку на проект озвученного и смонтированного вами голосового приветствия. Оно уже фактически готово и ожидает лишь оплаты. Вы оплачиваете и получаете ссылку на скачивание аудио файла в несжатом формате высокого качества (wave, стерео, 44Гц, 16бит).
инструкция для андроида и айфона
Современные сенсорные телефоны и смартфоны поражают своих владельцев огромным количеством самых разных функций. О существовании многих из них пользователи могут даже не догадываться. Одной из таких функций является автоматический ответ на входящий звонок. Данной функцией обладают практически все флагманские модели известных брендов. Кому будет полезной функция автоматического ответа? Как настроить автоответ на телефоне? Как отключить автоответ на андроиде, а включить на айфоне? Эти и другие вопросы, связанные с автоматическим принятием вызова, мы и рассмотрим в данной статье.
Зачем нужен автоматический ответ на входящий звонок?
Автоответ – это функция смартфона, которая позволяет принимать входящие звонки автоматически через определенное время. Таким образом, чтобы ответить на звонок пользователю гаджета не нужно нажимать кнопку приема вызова или осуществлять какие-либо другие манипуляции. Через заданное время гаджет автоматически ответит сам. Такая функция будет полезна в следующих случаях:
- При непрерывном рабочем процессе. Для людей, чья профессия связана с неотрывным рабочим процессом, который не позволяет или делает неудобным отвлечение на принятие вызова, автоответ будет очень актуальным. Человеку не нужно останавливать рабочий процесс, чтобы принять вызов. Смартфон сделает это сам. Для максимальной оптимизации процесса автоматического ответа, владельцу гаджета рекомендуется использовать гарнитуру.
- При невозможности вручную отвечать на звонок. Не только на работе, но и в повседневной жизни, пользователю часто неудобно отвечать на звонок – за рулем автомобиля или во время езды на велосипеде; в случае, когда нужно снимать перчатки или доставать телефон из сумки на морозе; мыть руки для принятия вызова или осуществлять любые другие неудобные действия.

- Для людей с ограниченными возможностями. Одной из основных групп пользователей, для которых была разработана данная функция, являются люди с ограниченными возможностями. В некоторых случаях, данная функция является единственным возможным способ ответить на звонок.
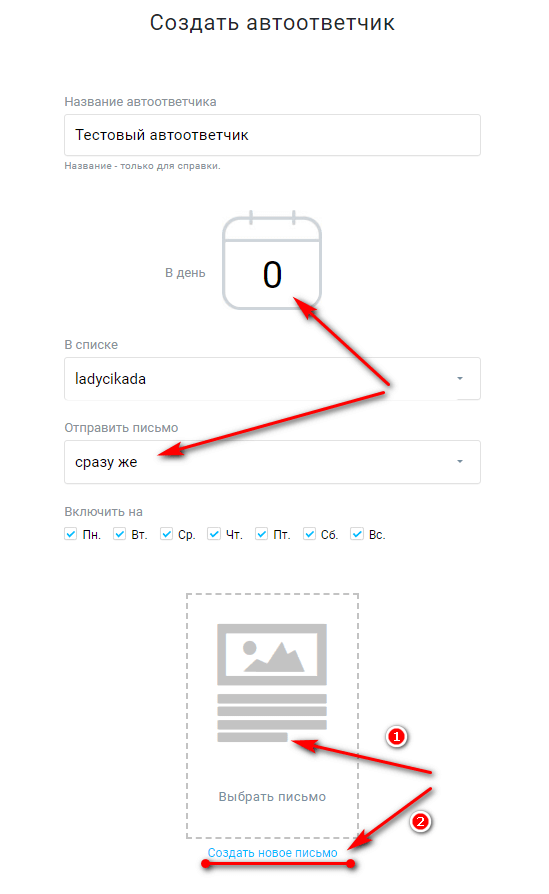
Такая функция может быть как полезной, так и наоборот – приносить пользователю лишь дискомфорт и создавать неловкие ситуации. Например, автоматический ответ на входящий звонок может осуществляться даже тогда, когда владелец смартфона не слышал звонка. В этом случае, гаджет продолжает лежать на своем месте (в кармане, сумке, соседней комнате), а другой абонент уже соединен и слышит только шум в трубке. Именно поэтому далее в статье мы рассмотрим, как настроить автоответ на телефоне и как его выключить в случае необходимости. А как работает современный смартфон во время принятия вызова, можно узнать в статье по ссылке.
Как включить/отключить автоответ на андроиде
Включить автоответ на андроиде не составит труда даже пользователю, который совсем не дружит с гаджетами. Для того чтобы активировать упомянутую функцию нужно пройти следующий путь в меню смартфона:
Настройки → Приложения → Вызов → Все вызовы → Режим ответа
В последнем подменю появляется функция поставить галочку напротив функции «Автоматически за … секунд». Таким же способом можно отключить автоответ.
В некоторых случаях вызовы продолжают приниматься автоматически, даже если упомянутая функция отключена. Иногда автоответ на андроиде может осуществляться через активацию другой опции «Движения и жесты». Ее можно отключить, пройдя следующий путь в настройках:
Настройки →Устройство →Движения и жесты
Последняя функция отвечает за управление смартфоном без касаний, именно они могут иногда автоматически принимать вызовы. Чтобы избежать этого, стоит деактивировать и эту функцию.
Как включить/отключить автоответ на айфоне
Все айфоны с iOS 11 поддерживают функцию автоответа. Настроить ее можно, пройдя следующий путь:
Настройки → Основные → Универсальный доступ → Источник звука → Автоответ на вызовы
При активации функции появляется возможность выбрать время, через которое осуществляется автоответ на айфоне. Интервал времени может варьировать в диапазоне от 3 до 60 секунд.
Чтобы отключить автоответ нужно пройти тот же путь и снять галочку напротив подменю «Автоответ на звонки». Для тех, кому не подходит функция автоответа, но не хочется пропускать важные звонки, подойдет автоответчик. Так как включить автоответчик на айфоне также просто, как и автоответ – с этой задачей сможет справиться каждый пользователь.
Магазин мобильных телефонов GSM-ka предлагает большой выбор смартфонов, в которых Вы легко сможете настроить автоответ. Заходите в каталог смартфонов нашего магазина и выбирайте современные гаджеты с удивительным функционалом, чтобы сделать Вашу жизнь ещё комфортнее!
Автоответчик: тексты примеры для выбора
Оказывая услуги по записи голосовых приветствия для АТС уже на протяжении более 5-ти лет, мы накопили большой опыт в подготовке текстов для этих сообщений. Вы установили в офисе IP АТС (локальную или виртуальную) и вам потребовалось голосовое приветствие.
Вы установили в офисе IP АТС (локальную или виртуальную) и вам потребовалось голосовое приветствие.Где заказать профессиональную запись голоса для автоответчика?
Заказать приветствиеВарианты голосовых приветствий
Голосовое приветствие — визитка
Как правило такое приветствие повествует звонящему клиенту о том, куда он дозвонился и, возможно о специализации компании. Текст автоответчика не перегружен навигацией и звучит не более 10-ти секунд.
IVR для клиники:
Здравствуйте! Вы позвонили в клинику «Неболейка». Для записи на приём к специалисту наберите 1, для звонка в лабораторию — наберите 2 или дождитесь ответа специалиста регистратуры. Уведомляем, что в целях контроля качества оказываемых услуг, все разговоры записываются.IVR для доставки:
Вас приветствует компания «Доставка на колёсах». Мы доставим ваш груз в любую точку мира.Оставайтесь на линии, специалист обязательно ответит вам.
IVR для сервис-центра:
Здравствуйте. Вы позвонили в сервис-центр «Отвёрткин».
Вы позвонили в сервис-центр «Отвёрткин».Чтобы оставить заявку на ремонт, нажмите 1, узнать статус ремонта, нажмите 2 или дождитесь ответа оператора.
Голосовое меню (автосекретарь) — навигация
Такие приветствия отличаются от визитки в первую очередь сообщением о добавочных номерах — для звонка в тот или иной отдел компании. Также голосовое меню может быть многоуровневым, где после нажатия одной цифры, проигрывается голосовое сообщение для дальнейших действий. Как правило такие меню используются банками, мобильными операторами и другими колл-центрами крупных компаний.
Пример:
Пункт 1. Вас приветствует интернет-провайдер «Мегапровод». Для того, чтобы узнать состояние лицевого счета, нажмите 1, для связи с отделом продаж, нажмите 2 или дождитесь ответа менеджера.
Пункт 2 (при нажатии 1). Чтобы получить информацию о состоянии лицевого счета в автоматическом режиме, нажмите 2 или дождитесь ответа специалиста. Подготовьте номер вашего лицевого счета.
Пункт 3 (при нажатии 2). Спасибо за обращение в нашу компанию. Вы будете соеденены с первым освободившимся оператором.
Заказать приветствие
Текст автоответчика при смене номера телефона
Бывает так, что по тем или иным причинам компания меняет номер (номера) своего телефона. Чаще всего это может быть связано или с необходимостью компании или с какими-то требованиями пройвадера услуг, предоставляющего услуги городского телефонного номера. И для «мягкого» перехода на новый номер, во избежании потери клиентов, можно на старых номерах временно установить голосовое уведомление о смене номера.
Пример текста:
Вы позвонили в магазин «Офисная мебель». Сообщаем, что у нас изменились номера телефонов. Вы можете перезвонить на наш новый многоканальный номер 8 777 555 22 33
Как составить грамотное голосовое приветствие и что произносить?
Лучшее голосовое приветствие Это короткое приветстсвие. Мы рекомендуем устанавливать длительность автоответчика в 12-17 секунд.
- куда дозвонился абонент;
- как связаться с нужным отделом;
- приглашение ввести известный внутренний номер сотрудника.
клиента о компании
на 30%
зависит от качества IVRМы уже выполнили заказы для компаний в сфере
Транспорт и логистика (грузоперевозки, такси, курьерские компании)
Финансовые организации (банки, страховые компании, микрокредитные организации)
Торговые компании (мебельные магазины, бытовая техника, строительные организации и др.)
Услуги (юридические конторы, сервисные центры, разработка сайтов и др.)
Кафе и ресторы (в том числе услуги по доставке еды)
Туризм (билетные кассы, туристские агентства)
Примеры текстов для информатора
Очень часто наши клиенты просят нас помочь с написанием грамотного сообщения и мы с радостью им помогаем. Ниже хотим поделиться некоторыми примерами текстов для того, чтобы вы и сами могли понимать что можно придумать.
Пример #1
Вас приветствует компания «Торговые системы».
Для связи с отделом продаж наберите цифру 1, для соединения с сервисным центром наберите 2, с бухгалтерией — 3.
Для отправки факса наберите 4.
Если вы знаете внутренний номер сотрудника, наберите его в тоновом режиме, или дождитесь ответа оператора.
Пример #2
Вас приветствует Такси «Империал».
Дождитесь ответа оператора или положите трубку — мы вам перезвоним.
Пример #3
Здравствуйте!
Вы позвонили в траспортно-логистическую компанию «Malimm Trans».
Для связи с оператором наберите цифру 1
Для звонка в отдел логистики нажмите 2
Чтобы соединиться с бухгалтерией, наберите 3
Если вы знаете внутренний номер сотрудника, наберите его в тоновом режиме или дождитесь ответа менеджера.
Уведомляем, что в целях контроля оказания услуг, все разговоры будут записаны.
Пример #4
Вас приветствует курьерская служба «Быстрые ноги».
Чтобы подать заявку на вызов курьера нажмите 1,
Для связи с отделом продаж нажмите 2,
для справочной информации нажмите 3,
либо дождитесь ответа оператора.
Пример #5
Вас приветствует компания «World Tourism».
Для связи с консультантами на левом берегу нажмите цифру 1,
для звонка консультантам на правом берегу — нажмите 2
или дождитесь ответа менеджера.
Пример #6
Вас приветствует магазин «4-на-4».
Дождитесь ответа менеджера, Вам обязательно ответят.
Обратите внимание на режим работы нашего магазина:
С понедельника по пятницу: с 9:00 до 17:00
Перерыв на обед — с 13:00 до 14:00
Суббота — с 9:00 до 13:00
Примеры роликов
Это некоторые примеры, с которыми вы можете ознакомиться. Также, вы можете пройти в раздел услуг нашего сайта «Запись IVR», где сможете прослушать некоторые выполненные нами работы и при необходимости произвести заказ для своей компании в режиме онлайн.
Автоответчик — Help Mail.ru. Почта
Популярные запросы
- Как удалить аккаунт
- Как связаться со службой поддержки
- Не помню пароль
- Пришло письмо от Mail.ru. Это правда вы?
- Не приходят письма
- Как изменить пароль
- Как восстановить удалённый аккаунт
- Не могу убрать рекламу
 mail.ru/mail/questions/old&suggest_c=456ecb85fd1f»>Почему я не могу перейти в старый интерфейс
mail.ru/mail/questions/old&suggest_c=456ecb85fd1f»>Почему я не могу перейти в старый интерфейсКак настроить автоответ в Майл. ру
 ру
руМногие используют почту как обычный сервис для получения рассылок с различных сайтов. Но есть и те, для кого почта – это средство для общения с другими пользователями в рамках работы или иной сферы. В таких случаях не всегда есть возможность ответить на сообщение, особенно когда на работе отпуск и не хочется проверять почту.
Для таких случаев была разработана специальная опция, позволяющая автоматически отправлять сообщения на входящие письмо. Как правильно настроить автоответ в майл ру, поговорим в сегодняшней статье.
Как включить автоответчик
Активация автоответчика осуществляется непосредственно через настройки почтового сервиса майл ру. Подробнее как это все работает, рассмотрим в последующих разделах.
На компьютере
Опция автоответчика в майл ру включает в себя следующие возможности:
- Установка начала отправки сообщений. Если вам необходимо начать отправку только в определенный день, то это можно запросто сделать. Кроме того, доступна возможность установить дату окончания функционирования автоответчика.
- Сообщение. Устанавливайте уникальные письма, которые будут отправляться на каждое входящие сообщение.
- Временной интервал. Можно активировать автоответчик только в определенное время. Например, с 10 утра до 18 вечера.
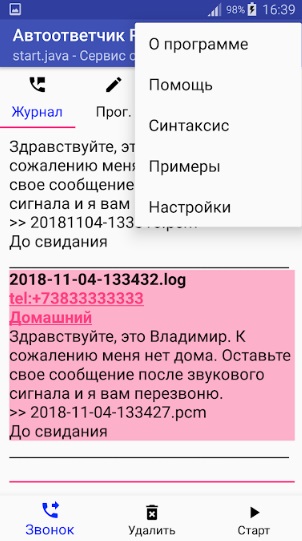 Кроме того, доступна возможность установить дату окончания функционирования автоответчика.
Кроме того, доступна возможность установить дату окончания функционирования автоответчика.Настраиваем автоответ в майл ру:
- Запускаем браузер и открываем в нем почту от mail. Затем в нижнем левом углу кликаем по кнопке в виде шестеренки.
- Следующим шагом переходим в раздел «Все настройки».
- Далее переходим в раздел «Общие» и нажимаем в правой части экрана на кнопку «Выключен» в подразделе «Автоответчик». Таким образом будет активирован автоответ в почтовом ящике.
- Теперь нам нужно его немного настроить: установим время отправки с определенной даты. Например, сделаем, чтобы автоответ работал с 6 по 10 сентября 2020 года. Окончательную дату устанавливать не обязательно – в таком случае автоответ будет работать постоянно, пока его не отключат.
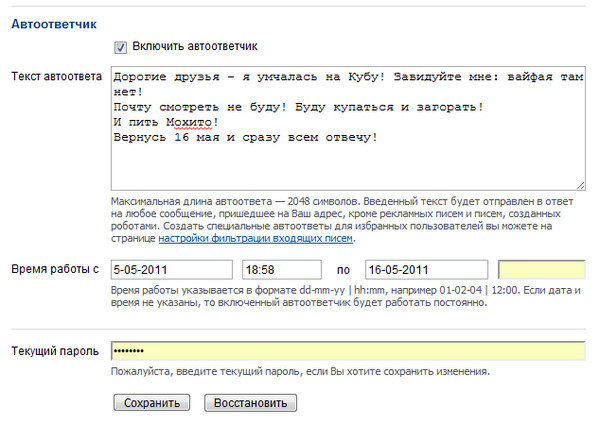 Окончательную дату устанавливать не обязательно – в таком случае автоответ будет работать постоянно, пока его не отключат.
Окончательную дату устанавливать не обязательно – в таком случае автоответ будет работать постоянно, пока его не отключат.- Также добавим сообщение, которое будет отправлять в случае срабатывания автоответчика. Например: «Добрый день! Меня сейчас нет на месте, отвечу в свободное время».
- Здесь же мы можем отметить пункт «Добавить временной интервал для отправки». Таким образом можно установить в какое время дня будет работать автоответчик. Если данная опция не активна, то автоответ будет срабатывать круглосуточно.
- В завершении нажимаем на кнопку «Сохранить».
Вот таким несложными действия можно подключить автоответчик к себе на почту. После активации данной опции все входящие письма будут сопровождаться автоматическим ответом в указанное время. Отключить это можно также через раздел «Общие» в настройках почты, где мы включали автоответчик.
Стоит заметить, что при подключении сторонней почты, например, Gmail, настраивать автоответчик нужно именно в этом сервисе. В противном случае работать он попросту не будет.
На телефоне
К сожалению, мобильное и браузерное приложение на телефоне не предоставляют пользователям возможность установить автоответ. Сделать это можно исключительно через десктопную версию почты майл ру.
На этом наша статья подходит к концу, надеемся, что она была для вас полезной. Автоматическая отправка письма может быть полезна во многих случаях: когда нет времени отвечать на письмо в загруженный день, во время отпуска и других днях.
Также вы можете использовать автоответчик в тех случаях, когда приходит слишком много писем и нет времени на них отвечать. Теперь вы знаете как можно настроить автоответ в почте майл ру. Удачи в изучении!
Как в студии «Прозвучи» без проблем записать автоответчик на телефон
Как часто, дозвонившись куда-либо, приходится слышать приятный мужской или женский голос, который Вас приветствует, вежливо просит подождать, пока свободный сотрудник сможет ответить на звонок.
А бывает такое, что послушав музыку минуту-другую-третью, Вы в бешенстве бросаете трубку? Или начинаете разговаривать с автоинформатором, отпуская едкие колкости, потому что-то, что он сообщает, Вам сейчас совсем не нужно, а нужно – поскорее услышать живого человека?
Как сделать, чтобы подобные казусы не происходили? Как записать автоответчик на телефон, чтобы каждый дозвонившийся был услышан, понят и принят? А если не дозвонился, то не поменял своего мнения об адресате в худшую сторону? Попробуем разобраться.
Виды автоответчиков
Прежде всего, уточним, каким именно может быть автоответчик и чем один отличается от другого:
- Голосовое приветствие – с Вами поздоровались, назвали имя компании и попросили подождать. Возможно, во время ожидания будет звучать приятная музыка, записанная под автоответчик.
- Автосекретарь – используется, когда в учреждении есть внутренняя АТС, а для соединения с каким-то отделом или сотрудником надо донабрать добавочный номер. Часто бывает, что добавочный номер состоит из 2 или 3 цифр.
- Голосовое меню или IVR меню – предварительно записанные голосовые сообщения, которые помогают перенаправить позвонившего к нужному сотруднику или предоставить ему для прослушивания именно его интересующую информацию. Такую запись автоответчика можно часто услышать, позвонив по телефоне оператору сотовой связи, в крупную компанию, оказывающую широкий спектр услуг.
 Часто бывает, что добавочный номер состоит из 2 или 3 цифр.
Часто бывает, что добавочный номер состоит из 2 или 3 цифр.Примеры записей автоответчиков на телефон от «Прозвучи»
В продакшн-студии «Прозвучи.РУ» вы можете записать любой вид автоответчика для телефона. Первый и второй вариант мы готовы сделать для Вас за один день, в особо экстренных ситуациях – за 2-3 часа (подробности лучше уточнить у наших специалистов).
Для записи большого голосового меню на автоответчик телефона потребуется времени больше – до трёх дней. За время работы нами записано больше 2 тысяч автоответчиков, примеры можете послушать прямо сейчас.
«Кудо Веар»
Заказать автоответчикЕвгений Белов
«Тао Спа»
Заказать автоответчикТамара Петрова
«Упаковочные решения»
Заказать автоответчикАндрей Морозов
«Зоопассаж»
Заказать автоответчикКак настроить Mac как автоответчик и факс | Small Business
Настройка компьютера Mac вашей компании для работы в качестве автоответчика и факсимильного аппарата избавляет от необходимости покупать специальные устройства, предназначенные для этих функций. Хотя Apple больше не включает телефонные модемы в свои компьютеры Mac, ваша компания, тем не менее, может принимать телефонные звонки, а также отправлять и получать факсы с помощью внешнего USB-факс-модема. CoMa X — стороннее приложение с функцией автоответчика.Если ваша компания использует Skype для телефонных звонков, воспользуйтесь преимуществами встроенного автоответчика этого приложения.
Хотя Apple больше не включает телефонные модемы в свои компьютеры Mac, ваша компания, тем не менее, может принимать телефонные звонки, а также отправлять и получать факсы с помощью внешнего USB-факс-модема. CoMa X — стороннее приложение с функцией автоответчика.Если ваша компания использует Skype для телефонных звонков, воспользуйтесь преимуществами встроенного автоответчика этого приложения.
Автоответчик — CoMa X
Подключите USB-конец внешнего факс-модема к USB-порту на Mac вашей компании. Подключите телефонный кабель модема к любой доступной телефонной розетке на рабочем месте.
Загрузите и установите программное обеспечение CoMa X на свой Mac.
Запустите приложение CoMa X, нажмите кнопку «Настройки» и перейдите на вкладку «Голос».
Нажмите кнопку «Запись системных сообщений».
Щелкните раскрывающееся меню «Системные сообщения» и выберите «Приветственные сообщения / факсы».
Нажмите кнопку «Создать», чтобы открыть диалоговое окно «Редактировать сообщение».
Нажмите кнопку «Запись» и начните запись своего сообщения. По завершении нажмите кнопку «Стоп».
Нажмите кнопку «Сохранить», перейдите в папку на вашем Mac, где вы хотите сохранить файл сообщения, и нажмите «Сохранить».
Нажмите «ОК», а затем еще раз «ОК», чтобы завершить настройку CoMa X для работы в качестве автоответчика.
Автоответчик — Skype
Откройте новое окно веб-браузера и войдите в свою учетную запись Skype (ссылку см. В разделе Ресурсы).
Щелкните «Голосовые сообщения» в разделе «Управление функциями», а затем щелкните «Активировать мои голосовые сообщения сейчас».
Запустите автономное приложение Skype на Mac и войдите в свою учетную запись.
Нажмите «Skype» в главном меню, а затем нажмите «Настройки».
Щелкните вкладку «Вызовы» и щелкните «Настройка голосовых сообщений», чтобы отобразить диалоговое окно «Настройка голосовых сообщений».
Нажмите кнопку «Запись», чтобы записать приветствие на автоответчике. По завершении нажмите кнопку «Стоп».
По завершении нажмите кнопку «Стоп».
Нажмите кнопку «Воспроизвести», чтобы прослушать свое приветствие. Нажмите «Готово», чтобы сохранить приветствие и вернуться на вкладку «Настройки вызовов».
Щелкните переключатель «Отправить в голосовые сообщения», чтобы включить автоответчик Skype на Mac. Пока этот переключатель установлен, входящие вызовы будут отправляться на ваш автоответчик, когда вы не отвечаете.
Факс
Подключите конец USB внешнего факс-модема к порту USB на Mac вашей компании. Подключите телефонный кабель модема к любой доступной телефонной розетке на рабочем месте.
Щелкните меню «Apple» на вашем Mac.
Щелкните «Системные настройки», затем щелкните «Печать и факс».
Щелкните кнопку «+» и щелкните вкладку «Факс».
Щелкните внешний факс-модем в списке доступных факс-совместимых устройств, а затем щелкните «Добавить».»
Введите номер факса вашей компании в поле» Номер факса «.
Нажмите» Параметры приема «, а затем установите флажок» Принимать факсы на этот компьютер «.
Выберите, сколько звонков ваш Mac должен ждать, прежде чем факсимильный аппарат должен ответить на входящий звонок.
Щелкните меню «Сохранить в» и выберите место на вашем компьютере для сохранения входящих факсов.
Если вы хотите, чтобы факсы автоматически печатались на локальном принтере, установите флажок «Печатать в» и затем щелкните имя принтера, на который вы хотите отправлять факсы.
Если вы хотите автоматически отправлять входящие факсы получателю по электронной почте, установите флажок «Отправить по электронной почте» и введите адрес электронной почты, на который вы хотите отправлять факсы, в соответствующем поле.
Нажмите кнопку «ОК», чтобы завершить настройку Mac в качестве факсимильного аппарата.
Ссылки
Ресурсы
Биография писателя
Эндрю Теннисон пишет о культуре, технологиях, здоровье и множестве других тем с 2003 года. Он публиковался в The Gazette, DTR и ZCom.Он имеет степень бакалавра искусств в области истории и степень магистра изящных искусств в области письма.
Обнаружение автоответчика — Twilio
MachineDetectionTimeout
Время в секундах, в течение которого Twilio должна попытаться выполнить обнаружение автоответчика, прежде чем истечет таймаут и вернет AnsardedBy как неизвестно .
Увеличение этого значения даст двигателю больше времени для принятия решения. Это может быть полезно, когда DetectMessageEnd предоставляется в параметре MachineDetection и ожидается долгое приветствие автоответчика, которое может превышать 30 секунд.
Уменьшение этого значения сократит время, необходимое механизму для принятия решения. Это может быть особенно полезно, когда опция Enable предоставляется в параметре MachineDetection и вы хотите ограничить время для начального обнаружения.
MachineDetectionSpeechThreshold
Число миллисекунд, которое используется в качестве меры для измерения продолжительности речевого действия. Продолжительность ниже этого значения будет интерпретироваться как человек, а более продолжительная — как машина.
Продолжительность ниже этого значения будет интерпретироваться как человек, а более продолжительная — как машина.
Увеличение этого значения уменьшит вероятность того, что False Machine (обнаруженная машина, фактически человек) для длинного человеческого приветствия (например, делового приветствия), увеличит время, необходимое для обнаружения машины.
Уменьшение этого значения снизит шансы False Human (обнаруженный человек, фактически машина) для коротких приветствий голосовой почты. (Обратите внимание, что значение этого параметра может потребоваться уменьшить более чем на 1000 мс, чтобы обнаруживать очень короткие приветствия голосовой почты.Уменьшение этого значения может привести к увеличению числа обнаружений False Machine . Настройка MachineDetectionSpeechEndThreshold , вероятно, является лучшим подходом для коротких голосовых сообщений.) Уменьшение MachineDetectionSpeechThreshold также сократит время, необходимое для обнаружения машины.
MachineDetectionSpeechEndThreshold
Количество миллисекунд тишины после речевой активности, по истечении которой речевая активность считается завершенной.
Увеличение этого значения обычно будет использоваться для лучшего решения сценариев коротких приветствий голосовой почты. Для коротких сообщений голосовой почты обычно идет звук от 1000 до 2000 мс, за которым следует тишина от 1200 до 2400 мс, а затем дополнительный звук перед звуковым сигналом. Увеличение MachineDetectionSpeechEndThreshold до ~ 2500 мс будет обрабатывать 1200–2400 мс тишины как паузу в приветствии, но не как конец приветствия, и приведет к обнаружению машины. К недостаткам такого изменения можно отнести:
- Увеличение задержки обнаружения человека на величину увеличения этого параметра (например,г. изменение 1200 мс -> 2500 мс увеличивает задержку обнаружения человека на 1300 мс)
- В случаях, когда у человека есть два высказывания, разделенных периодом молчания (например, «Привет», затем 2000 мс секунд молчания и еще одно «Привет»), это может быть интерпретировано как машина
Уменьшение этого значения приведет к более быстрому обнаружению человека. Следствием этого является то, что это может привести к увеличению числа обнаружений False Human (обнаруженный человек, фактически машина), поскольку пауза в тишине в приветствии голосовой почты (не обязательно только в коротких сценариях голосовой почты) может неправильно интерпретироваться как конец речи.
Следствием этого является то, что это может привести к увеличению числа обнаружений False Human (обнаруженный человек, фактически машина), поскольку пауза в тишине в приветствии голосовой почты (не обязательно только в коротких сценариях голосовой почты) может неправильно интерпретироваться как конец речи.
MachineDetectionSilenceTimeout
Количество миллисекунд начального молчания, после которого будет возвращен результат unknown AnsruptedBy
Увеличение этого значения приведет к ожиданию более длительного периода начального молчания перед возвратом «неизвестного» результата AMD.
Уменьшение этого значения приведет к ожиданию более короткого периода начального молчания перед возвратом «неизвестного» результата AMD.
Автоответчик | Лаборатория кибер-прослушивания ESL Рэндалла
| Уровень: | Тема: | Спикеры: | Длина: |
| легкий | голосовая почта | человек | 00:34 |
Упражнения перед прослушиванием
Сегодня существует множество типов голосовой почты на выбор, включая мобильную, спутниковую и стационарную. Однако независимо от того, какой услугой вы пользуетесь, важно научиться оставлять и понимать телефонные сообщения.Какие вопросы или просьбы вы можете услышать в телефонном сообщении (например, «Пожалуйста, позвоните мне завтра»).
Однако независимо от того, какой услугой вы пользуетесь, важно научиться оставлять и понимать телефонные сообщения.Какие вопросы или просьбы вы можете услышать в телефонном сообщении (например, «Пожалуйста, позвоните мне завтра»).
Идиомы
« позвони кому-нибудь » = позвони кому-нибудь
« Эй, позвони мне, если хочешь встретиться ».
« позвоните кому-нибудь » = зайдите и посетите
« Я позвоню вам завтра около полудня ».
Упражнения на аудирование
A. Прослушайте телефонное сообщение и ответьте на вопросы.
Билл собирается ______ завтра.
Привет, Билл. Это Хэнк. Я просто звоню, чтобы сообщить, что завтра вечером я немного опоздаю на игру.
Продолжить >>
Хэнк должен работать допоздна, потому что ему нужно _____.
посетить встречу
закрыть офис
написать отчет
Мне нужно поработать несколько дополнительных часов, чтобы закончить отчет.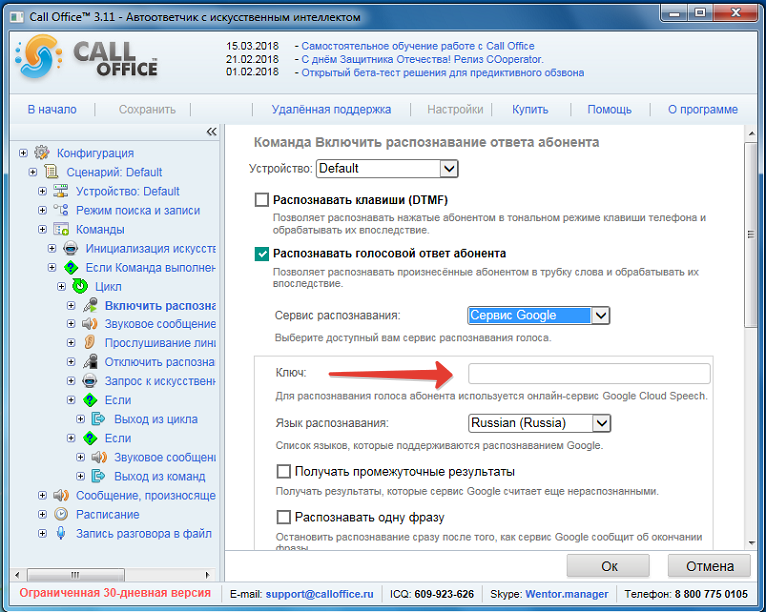
Продолжить >>
Хэнк собирается навестить Лизу, потому что _____.
она больна в постели
он должен что-то вернуть
он собирается отвезти ее в дом Билла
О, тогда я собираюсь заехать к Лизе домой примерно на час, так как она недавно заболела.
Продолжить >>
Хэнк получит закуски в _____.
его дом
магазин
его работа
Я заеду к себе домой, чтобы купить еды для игры.
Продолжить >>
Хэнк, вероятно, завершит свою работу к ____.
8:00 вечера.
7:00 вечера.
9:00 вечера.
Я должен закончить где-то между семью и восемью.
Продолжить >>
Личное: АвтоответчикОтлично.
Поделитесь своими результатами:
Facebook Твиттер Личное: АвтоответчикХорошо.
Поделитесь своими результатами:
Facebook Твиттер Личное: Автоответчик Попробуйте еще раз.
Поделитесь своими результатами:
Facebook ТвиттерПоделитесь этой викториной, чтобы увидеть свои результаты.
FacebookПОПРОБУЙТЕ СНОВА!
Практика словарного запаса
Выполните контрольные вопросы по словарю со словами из беседы, чтобы больше попрактиковаться:
Упражнения после прослушивания
A.Попрактикуйтесь в таких ситуациях оставлять сообщение другу. Используйте дополнительные слова, чтобы добавить информацию к сообщению:
- Вы заболели и сегодня не можете пойти в школу. (домашнее задание)
- Вы хотите, чтобы ваш друг забрал вас после школы. (17:30)
- Сегодня тебе надо подготовиться к экзамену и поиграть в теннис. (перенос)
Онлайн-расследования
Каким образом Интернет и технологии помогли нам оставаться на связи с другими людьми, в частности, с помощью мобильных телефонов и служб автоответчика в режиме онлайн. Просмотрите две телефонные компании, которые предлагают такие продукты или услуги, как голосовая почта и переадресация звонков, призванные помочь людям лучше общаться друг с другом. Затем определите преимущества таких продуктов с точки зрения стоимости, эффективности и удобства.
Просмотрите две телефонные компании, которые предлагают такие продукты или услуги, как голосовая почта и переадресация звонков, призванные помочь людям лучше общаться друг с другом. Затем определите преимущества таких продуктов с точки зрения стоимости, эффективности и удобства.
200+ Вопросы и ответы на собеседование по машинному обучению на 2021 год
Собеседование по машинному обучению требует тщательного собеседования, на котором кандидаты оцениваются по различным аспектам, таким как технические навыки и навыки программирования, знание методов и ясность основных концепций.Если вы хотите устроиться на вакансию в сфере машинного обучения, важно знать, какие вопросы на собеседовании обычно задают рекрутеры и менеджеры по найму.
Это попытка помочь вам взломать интервью с машинным обучением в крупных продуктовых компаниях и стартапах. Обычно собеседования по машинному обучению в крупных компаниях требуют глубоких знаний структур данных и алгоритмов. В следующей серии статей мы начнем с основ концепций и будем использовать их для решения основных вопросов интервью.Собеседования по машинному обучению состоят из множества раундов, которые начинаются с отборочного теста. Это включает в себя решение вопросов либо на доске, либо решение их на онлайн-платформах, таких как HackerRank, LeetCode и т. Д.
Вопросы собеседования по машинному обучению
# Объясните термины AI, ML и Deep Learning?
# В чем разница между ошибками типа I и типа II?
# Назовите разницу между причинно-следственной связью и корреляцией?
# Как соотнести стандартное отклонение и дисперсию?
# Большой разброс данных — это хорошо или плохо?
# Что такое временные ряды?
# Что такое преобразование Бокса-Кокса?
# Что такое преобразование Фурье?
# Что такое маргинализация? Объясните процесс.
# Объясните фразу «Проклятие размерности».
Здесь мы составили список из 100 наиболее часто задаваемых вопросов на собеседовании по машинному обучению, с которыми вы можете столкнуться во время собеседования.
100 самых популярных вопросов по машинному обучению с ответами на собеседование
1. Объясните термины «искусственный интеллект» (AI), машинное обучение (ML и глубокое обучение?)
Искусственный интеллект (AI) — это область производства интеллектуальных машин .ML относится к системам, которые могут ассимилироваться на основе опыта (данные обучения) и состояния глубокого обучения (DL) с системами, которые учатся на опыте с большими наборами данных. ML можно рассматривать как подмножество AI. Глубокое обучение (DL) — это машинное обучение, но оно полезно для больших наборов данных. На рисунке ниже примерно показана взаимосвязь между AI, ML и DL:
Таким образом, DL — это подмножество ML, и оба они были подмножествами AI.
Дополнительная информация: ASR (автоматическое распознавание речи) и NLP (обработка естественного языка) относятся к AI и накладываются на ML и DL, поскольку ML часто используется для задач NLP и ASR.
2. Каковы различные типы обучения / моделей обучения в ML?
Алгоритмы машинного обучения можно в первую очередь классифицировать в зависимости от наличия / отсутствия целевых переменных.
A. Обучение с учителем : [Цель присутствует]
Машина обучается с использованием помеченных данных. Модель обучается на существующем наборе данных, прежде чем она начнет принимать решения с новыми данными.
Целевая переменная является непрерывной : Линейная регрессия, полиномиальная регрессия, квадратичная регрессия.
Целевая переменная — категориальная : Логистическая регрессия, Наивный Байес, KNN, SVM, Дерево решений, Повышение градиента, Повышение ADA, Бэггинг, Случайный лес и т. Д.
B. Обучение без учителя: [Цель отсутствует]
Обучение без учителя: [Цель отсутствует]
Машина обучена на непомеченных данных и без какого-либо надлежащего руководства. Он автоматически определяет закономерности и взаимосвязи в данных путем создания кластеров. Модель учится на основе наблюдений и выводимых структур данных.
Анализ главных компонентов, факторный анализ, разложение по сингулярным значениям и т. Д.
C. Обучение с подкреплением:
Модель учится методом проб и ошибок. Этот вид обучения включает в себя агента, который будет взаимодействовать с окружающей средой, чтобы создавать действия, а затем обнаруживать ошибки или вознаграждения за это действие.
Вы можете записаться на эти курсы машинного обучения в Great Learning Academy и получить сертификаты бесплатно.
Основы машинного обучения
Машинное обучение с Python
Статистика для машинного обучения
Расширенная статистика для машинного обучения
3. В чем разница между глубоким обучением и машинным обучением?
Машинное обучение включает в себя алгоритмы, которые учатся на шаблонах данных и затем применяют их для принятия решений. С другой стороны, глубокое обучение способно учиться путем обработки данных само по себе и очень похоже на человеческий мозг, где он что-то идентифицирует, анализирует и принимает решение.
Основные различия заключаются в следующем:
- Способ представления данных в системе.
- Алгоритмы машинного обучения всегда требуют структурированных данных, а сети глубокого обучения полагаются на слои искусственных нейронных сетей.

4. В чем главное отличие машинного обучения с учителем от машинного обучения без учителя?
Методика контролируемого обучения требует маркированных данных для обучения модели. Например, для решения задачи классификации (задачи обучения с учителем) вам необходимо иметь данные меток для обучения модели и классификации данных по группам с метками.Для обучения без учителя не требуется помеченный набор данных. Это основное ключевое различие между обучением с учителем и обучением без учителя.
5. Как выбрать важные переменные при работе с набором данных?
Существуют различные способы выбора важных переменных из набора данных, которые включают следующее:
- Идентифицировать и отбросить коррелированные переменные перед окончательной обработкой важных переменных
- Переменные можно выбрать на основе значений p из линейной регрессии
- Прямой, обратный и пошаговый выбор
- Лассо-регрессия
- Диаграмма случайных лесов и графиков переменных
- Основные функции могут быть выбраны на основе получения информации для доступного набора функций.

6. На сегодняшний день существует множество алгоритмов машинного обучения. Если дан набор данных, как можно определить, какой алгоритм для этого использовать?
Используемый алгоритм машинного обучения полностью зависит от типа данных в данном наборе данных. Если данные линейны, мы используем линейную регрессию. Если данные показывают нелинейность, тогда лучше подойдет алгоритм упаковки. Если данные должны быть проанализированы / интерпретированы для некоторых бизнес-целей, мы можем использовать деревья решений или SVM.Если набор данных состоит из изображений, видео, аудио, тогда нейронные сети будут полезны для точного получения решения.
Итак, не существует определенной метрики, чтобы решить, какой алгоритм использовать для данной ситуации или набора данных. Нам необходимо изучить данные с помощью EDA (исследовательский анализ данных) и понять цель использования набора данных, чтобы найти наиболее подходящий алгоритм. Итак, важно детально изучить все алгоритмы.
7.Чем ковариация и корреляция отличаются друг от друга?
Ковариация измеряет, как две переменные связаны друг с другом и как одна будет изменяться в зависимости от изменений другой переменной. Если значение положительное, это означает, что существует прямая связь между переменными, и одна из них будет увеличиваться или уменьшаться с увеличением или уменьшением базовой переменной соответственно, при условии, что все другие условия остаются постоянными.
Корреляция количественно определяет взаимосвязь между двумя случайными величинами и имеет только три конкретных значения, т.е.е., 1, 0 и -1.
1 обозначает положительную связь, -1 обозначает отрицательную связь, а 0 обозначает, что две переменные независимы друг от друга.
8. Назовите разницу между причинно-следственной связью и корреляцией?
Причинность применяется к ситуациям, когда одно действие, скажем X, вызывает результат, скажем Y, тогда как Корреляция просто связывает одно действие (X) с другим действием (Y), но X не обязательно вызывает Y.
9. Мы почти постоянно смотрим на программное обеспечение для машинного обучения.Как применить машинное обучение к оборудованию?
Мы должны построить алгоритмы машинного обучения в System Verilog, который является языком разработки оборудования, а затем запрограммировать его на FPGA, чтобы применить машинное обучение к оборудованию.
10. Объясните, что такое быстрое кодирование и кодирование меток. Как они влияют на размерность данного набора данных?
 Объясните, что такое быстрое кодирование и кодирование меток. Как они влияют на размерность данного набора данных?
Объясните, что такое быстрое кодирование и кодирование меток. Как они влияют на размерность данного набора данных? Быстрое кодирование — это представление категориальных переменных в виде двоичных векторов. Кодирование меток — это преобразование меток / слов в числовую форму.Использование однократного кодирования увеличивает размерность набора данных. Кодировка метки не влияет на размерность набора данных. Быстрое кодирование создает новую переменную для каждого уровня в переменной, тогда как при кодировании метки уровни переменной кодируются как 1 и 0.
Вопросы на собеседовании по глубокому обучению
Глубокое обучение является частью машинного обучения который работает с нейронными сетями. Он включает в себя иерархическую структуру сетей, которые устанавливают процесс, помогающий машинам изучать человеческую логику, стоящую за любым действием.Мы составили список часто задаваемых вопросов для глубокого собеседования, чтобы помочь вам подготовиться.
Что такое переоборудование?
Переобучение — это тип ошибки моделирования, который приводит к неспособности эффективно предсказать будущие наблюдения или уместить дополнительные данные в существующую модель. Это происходит, когда функция слишком близко соответствует ограниченному набору точек данных и обычно заканчивается большим количеством параметров. подробнее…
Что такое многослойный персептрон и машина Больцмана?
Машина Больцмана представляет собой упрощенную версию многослойного персептрона.Это двухуровневая модель с видимым входным слоем и скрытым слоем, которая принимает стохастические решения для . Подробнее…
11. Когда регуляризация вступает в игру в машинном обучении?
Иногда, когда модель начинает не соответствовать или переобучаться, требуется регуляризация. Это регрессия, которая отклоняет или упорядочивает оценки коэффициентов к нулю. Это снижает гибкость и препятствует изучению модели, чтобы избежать риска переобучения. Сложность модели снижается, и она становится лучше при прогнозировании.
Сложность модели снижается, и она становится лучше при прогнозировании.
12. Что такое смещение, дисперсия и что вы подразумеваете под компромиссом смещения и дисперсии?
Оба являются ошибками в алгоритмах машинного обучения. Когда алгоритм имеет ограниченную гибкость для вывода правильного наблюдения из набора данных, это приводит к смещению. С другой стороны, дисперсия возникает, когда модель чрезвычайно чувствительна к небольшим колебаниям.
Если при построении модели добавить больше функций, это добавит больше сложности, и мы потеряем смещение, но получим некоторую дисперсию.Чтобы поддерживать оптимальное количество ошибок, мы выбираем компромисс между смещением и дисперсией в зависимости от потребностей бизнеса.
Источник: Понимание компромисса смещения и отклонения: Скотт Фортманн — Роу. Смещение означает ошибку из-за ошибочных или чрезмерно упрощенных предположений в алгоритме обучения. Это предположение может привести к тому, что модель не соответствует данным, что затруднит ее высокую точность прогнозов и затруднит обобщение ваших знаний от обучающей выборки до тестовой.
Дисперсия также является ошибкой из-за слишком большой сложности алгоритма обучения. Это может быть причиной того, что алгоритм очень чувствителен к высокой степени вариации обучающих данных, что может привести к тому, что ваша модель переоценивает данные. Слишком много шума из обучающих данных для вашей модели, чтобы быть очень полезным для ваших тестовых данных.
Декомпозиция смещения-дисперсии по существу разлагает ошибку обучения любого алгоритма путем добавления смещения, дисперсии и небольшого количества неснижаемой ошибки из-за шума в базовом наборе данных.По сути, если вы сделаете модель более сложной и добавите больше переменных, вы потеряете смещение, но получите некоторую дисперсию — чтобы получить оптимально уменьшенное количество ошибок, вам придется искать компромисс между смещением и дисперсией. Вы не хотите, чтобы ваша модель имела высокую систематическую ошибку или большую дисперсию.
13. Как можно связать стандартное отклонение и дисперсию?
Стандартное отклонение относится к отклонению ваших данных от среднего. Дисперсия — это средняя степень, в которой каждая точка отличается от среднего значения i.е. среднее значение всех точек данных. Мы можем связать стандартное отклонение и дисперсию, потому что это квадратный корень из дисперсии.
Дисперсия — это средняя степень, в которой каждая точка отличается от среднего значения i.е. среднее значение всех точек данных. Мы можем связать стандартное отклонение и дисперсию, потому что это квадратный корень из дисперсии.
14. Вам предоставляется набор данных, в котором отсутствуют значения, которые разбросаны по 1 стандартному отклонению от среднего. Какая часть данных останется нетронутой?
Принято, что данные распределены по среднему значению, то есть данные распределены по среднему значению. Итак, можно предположить, что это нормальное распределение. При нормальном распределении около 68% данных находится в пределах 1 стандартного отклонения от средних значений, таких как среднее значение, мода или медиана.Это означает, что пропущенные значения не влияют на около 32% данных.
15. Большой разброс данных — это хорошо или плохо?
Более высокая дисперсия напрямую означает, что разброс данных большой, и функция имеет множество данных. Обычно большая вариативность функции рассматривается как не очень хорошее качество.
Обычно большая вариативность функции рассматривается как не очень хорошее качество.
16. Если ваш набор данных страдает высокой дисперсией, как бы вы с этим справились?
Для наборов данных с высокой дисперсией мы могли бы использовать алгоритм упаковки.Алгоритм пакетирования разбивает данные на подгруппы с выборкой, копируемой из случайных данных. После разделения данных случайные данные используются для создания правил с использованием алгоритма обучения. Затем мы используем метод опроса, чтобы объединить все предсказанные результаты модели.
17. Вам предоставлен набор данных об обнаружении мошенничества с коммунальными услугами. Вы построили модель классификатора и достигли показателя производительности 98,5%. Это хорошая модель? Если да, обоснуйте. Если нет, что вы можете с этим поделать?
Недостаточно сбалансирован набор данных об обнаружении мошенничества с коммунальными услугами i.е. несбалансированный. В таком наборе данных показатель точности не может быть мерой производительности, поскольку он может только правильно предсказать метку класса большинства, но в этом случае наша цель — предсказать метку меньшинства. Но часто меньшинства рассматриваются как шум и игнорируются. Таким образом, существует высокая вероятность ошибочной классификации ярлыка меньшинства по сравнению с ярлыком большинства. Для оценки производительности модели в случае несбалансированных наборов данных мы должны использовать Чувствительность (истинно положительный показатель) или специфичность (истинно отрицательный показатель), чтобы определить эффективность классификационной модели по меткам классов.Если метка класса меньшинства работает не так хорошо, мы могли бы сделать следующее:
Но часто меньшинства рассматриваются как шум и игнорируются. Таким образом, существует высокая вероятность ошибочной классификации ярлыка меньшинства по сравнению с ярлыком большинства. Для оценки производительности модели в случае несбалансированных наборов данных мы должны использовать Чувствительность (истинно положительный показатель) или специфичность (истинно отрицательный показатель), чтобы определить эффективность классификационной модели по меткам классов.Если метка класса меньшинства работает не так хорошо, мы могли бы сделать следующее:
- Мы можем использовать недостаточную или избыточную выборку, чтобы сбалансировать данные.
- Мы можем изменить пороговое значение предсказания.
- Мы можем присвоить меткам веса так, чтобы метки класса меньшинства получали больший вес.
- Мы смогли обнаружить аномалии.
18. Объясните, как обрабатывать отсутствующие или поврежденные значения в данном наборе данных.
Простой способ справиться с отсутствующими или поврежденными значениями — отбросить соответствующие строки или столбцы. Если необходимо удалить слишком много строк или столбцов, мы рассматриваем возможность замены отсутствующих или поврежденных значений каким-либо новым значением.
Если необходимо удалить слишком много строк или столбцов, мы рассматриваем возможность замены отсутствующих или поврежденных значений каким-либо новым значением.
Определение отсутствующих значений и удаление строк или столбцов может быть выполнено с помощью функций IsNull () и dropna () в Pandas. Кроме того, функция Fillna () в Pandas заменяет неправильные значения значением заполнителя.
19. Что такое временной ряд?
 Что такое временной ряд?
Что такое временной ряд? Временной ряд — это последовательность точек числовых данных в последовательном порядке.Он отслеживает движение выбранных точек данных за определенный период времени и записывает точки данных через регулярные промежутки времени. Временные ряды не требуют ввода минимального или максимального времени. Аналитики часто используют временные ряды для изучения данных в соответствии со своими конкретными требованиями.
 youtube.com/embed/FPM6it4v8MY?start=261&feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/FPM6it4v8MY?start=261&feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
Читайте также: Анализ и прогнозирование временных рядов
20. Что такое преобразование Бокса-Кокса?
Преобразование Бокса-Кокса — это степенное преобразование, которое преобразует ненормальные зависимые переменные в нормальные переменные, поскольку нормальность является наиболее распространенным предположением, сделанным при использовании многих статистических методов.У него есть параметр лямбда, который, если установлен в 0, означает, что это преобразование эквивалентно преобразованию журнала. Он используется для стабилизации дисперсии, а также для нормализации распределения.
21. В чем разница между стохастическим градиентным спуском (SGD) и градиентным спуском (GD)?
Градиентный спуск и Стохастический градиентный спуск — это алгоритмы, которые находят набор параметров, которые минимизируют функцию потерь.
Разница в том, что в Gradient Descend все обучающие выборки оцениваются для каждого набора параметров.В то время как в стохастическом градиентном спуске оценивается только одна обучающая выборка для указанного набора параметров.
22. В чем заключается проблема взрывного градиента при использовании метода обратного распространения?
Когда большие градиенты ошибок накапливаются и приводят к большим изменениям весов нейронной сети во время обучения, это называется проблемой взрывного градиента. Значения весов могут становиться настолько большими, что выходят за пределы и приводят к значениям NaN. Это делает модель нестабильной, и обучение модели останавливается, как и проблема исчезающего градиента.
23. Можете ли вы упомянуть некоторые преимущества и недостатки деревьев решений?
Преимущества деревьев решений заключаются в том, что их легче интерпретировать, они непараметрически и, следовательно, устойчивы к выбросам, а также имеют относительно небольшое количество параметров для настройки.
С другой стороны, недостатком является то, что они склонны к переобучению.
24. Объясните различия между машинами Random Forest и Gradient Boosting.
Случайные леса — это значительное количество деревьев решений, объединенных в группу с использованием средних или большинства правил в конце. Машины для повышения градиента также объединяют деревья решений, но в начале процесса, в отличие от случайных лесов. Случайный лес создает каждое дерево независимо от других, в то время как градиентное усиление создает одно дерево за раз. Повышение градиента дает лучшие результаты, чем случайные леса, если параметры тщательно настроены, но это не лучший вариант, если набор данных содержит много выбросов / аномалий / шума, поскольку это может привести к переобучению модели.Случайные леса хорошо подходят для обнаружения мультиклассовых объектов. Повышение градиента хорошо работает, когда есть данные, которые не сбалансированы, например, при оценке рисков в реальном времени.
Машины для повышения градиента также объединяют деревья решений, но в начале процесса, в отличие от случайных лесов. Случайный лес создает каждое дерево независимо от других, в то время как градиентное усиление создает одно дерево за раз. Повышение градиента дает лучшие результаты, чем случайные леса, если параметры тщательно настроены, но это не лучший вариант, если набор данных содержит много выбросов / аномалий / шума, поскольку это может привести к переобучению модели.Случайные леса хорошо подходят для обнаружения мультиклассовых объектов. Повышение градиента хорошо работает, когда есть данные, которые не сбалансированы, например, при оценке рисков в реальном времени.
25. Что такое матрица неточностей и зачем она вам нужна?
Матрица неточностей (также называемая матрицей ошибок) — это таблица, которая часто используется для иллюстрации производительности модели классификации, то есть классификатора на наборе тестовых данных, истинные значения которых хорошо известны.
Это позволяет нам визуализировать работу алгоритма / модели.Это позволяет нам легко идентифицировать путаницу между разными классами. Он используется в качестве показателя производительности модели / алгоритма.
Матрица неточностей известна как сводка прогнозов модели классификации. Количество правильных и неправильных прогнозов суммировалось со значениями подсчета и разбивалось по каждой метке класса. Он дает нам информацию об ошибках, допущенных с помощью классификатора, а также о типах ошибок, допущенных классификатором.
26. Что такое преобразование Фурье?
Преобразование Фурье — это математический метод, преобразующий любую функцию времени в функцию частоты.Преобразование Фурье тесно связано с рядами Фурье. Он принимает любой шаблон на основе времени для ввода и рассчитывает общее смещение цикла, скорость вращения и силу для всех возможных циклов. Преобразование Фурье лучше всего применять к сигналам, поскольку оно имеет функции времени и пространства. После применения преобразования Фурье к форме волны она разлагается на синусоиду.
27. Что вы подразумеваете под ассоциативным анализом правил (ARM)?
Анализ ассоциативных правил — это один из методов обнаружения закономерностей в данных, таких как объекты (измерения), которые встречаются вместе, и объекты (измерения), которые коррелируют.Он в основном используется в рыночном анализе, чтобы определить, насколько часто набор элементов встречается в транзакции. Правила ассоциации должны одновременно удовлетворять минимальную поддержку и минимальное доверие. Генерация правила ассоциации обычно состоит из двух разных этапов:
- «Минимальный порог поддержки задается для получения всех часто встречающихся наборов элементов в базе данных».
- «Этим частым наборам элементов дано минимальное доверительное ограничение для формирования правил ассоциации».
Поддержка — это мера того, как часто «набор элементов» появляется в наборе данных, а уверенность — это мера того, как часто определенное правило оказывается верным.
28. Что такое маргинализация? Объясните процесс.
Маргинализация — это суммирование вероятности случайной величины X с учетом совместного распределения вероятностей X с другими переменными. Это применение закона полной вероятности.
P (X = x) = ∑ Y P (X = x, Y)
Учитывая совместную вероятность P (X = x, Y), мы можем использовать маргинализацию, чтобы найти P (X = x). Таким образом, необходимо найти распределение одной случайной величины путем исчерпания случаев по другим случайным величинам.
29. Объясните фразу «Проклятие размерности».
Проклятие размерности относится к ситуации, когда ваши данные имеют слишком много функций.
Эта фраза используется для выражения сложности использования грубой силы или поиска по сетке для оптимизации функции со слишком большим количеством входных данных.
Он также может относиться к нескольким другим вопросам, например:
- Если у нас больше функций, чем наблюдений, у нас есть риск переобучения модели.
- Когда у нас слишком много объектов, наблюдения становится труднее кластеризовать.Слишком много измерений приводит к тому, что каждое наблюдение в наборе данных кажется равноудаленным от всех остальных, и никакие значимые кластеры не могут быть сформированы.
В таких случаях на помощь приходят методы уменьшения размерности, такие как PCA.
30. Что такое анализ основных компонентов?
Идея состоит в том, чтобы уменьшить размерность набора данных за счет уменьшения количества переменных, которые коррелируют друг с другом. Хотя вариацию нужно сохранить по максимуму.
Переменные преобразуются в новый набор переменных, которые известны как основные компоненты. Эти ПК являются собственными векторами ковариационной матрицы и поэтому ортогональны.
Вопросы для собеседования по НЛП
НЛП или обработка естественного языка помогает машинам анализировать естественные языки с целью их изучения. Он извлекает информацию из данных, применяя алгоритмы машинного обучения. Помимо изучения основ НЛП, важно подготовиться специально к интервью.
Объясните анализ зависимостей в NLP?
Анализ зависимостей, также известный как синтаксический анализ в NLP, — это процесс присвоения синтаксической структуры предложению и определения его синтаксического анализа зависимостей. Этот процесс имеет решающее значение для понимания корреляции между «головными» словами в синтаксисе. подробнее…
Какую из следующих архитектур можно обучить быстрее и требуется меньше обучающих данных
a. Моделирование языка на основе LSTM
b.Архитектура трансформатора
Подробнее…
31. Почему ротация компонентов так важна в анализе основных компонентов (PCA)?
Вращение в PCA очень важно, поскольку оно максимизирует разделение в пределах дисперсии, полученной всеми компонентами, из-за чего интерпретация компонентов станет проще. Если компоненты не повернуты, нам нужны расширенные компоненты для описания дисперсии компонентов.
32.Что такое выбросы? Назовите три метода борьбы с выбросами.
Точка данных, значительно удаленная от других аналогичных точек данных, называется выбросом. Они могут возникать из-за экспериментальных ошибок или вариабельности измерений. Они проблематичны и могут ввести в заблуждение процесс обучения, что в конечном итоге приводит к увеличению времени обучения, неточным моделям и плохим результатам.
Три метода обработки выбросов:
Одномерный метод — поиск точек данных, имеющих экстремальные значения для одной переменной
Многомерный метод — поиск необычных комбинаций для всех переменных
Ошибка Минковского — уменьшает Вклад потенциальных отклоняющихся в процесс обучения
Также прочтите - Преимущества продолжения карьеры в области машинного обучения
33.В чем разница между регуляризацией и нормализацией?
Нормализация регулирует данные; регуляризация регулирует функцию прогнозирования. Если ваши данные находятся в очень разных масштабах (особенно от низкого до высокого), вы можете нормализовать данные. Измените каждый столбец, чтобы получить совместимую базовую статистику. Это может быть полезно, чтобы не потерять точность. Одна из целей обучения модели — идентифицировать сигнал и игнорировать шум, если модели дается полная свобода действий, чтобы минимизировать ошибку, существует вероятность переобучения.Регуляризация накладывает некоторый контроль на это, предоставляя более простые функции подгонки по сравнению со сложными.
34. Объясните разницу между нормализацией и стандартизацией.
Нормализация и стандартизация — два очень популярных метода, используемых для масштабирования функций. Нормализация относится к изменению масштаба значений для соответствия диапазону [0,1]. Стандартизация относится к повторному масштабированию данных для получения среднего значения 0 и стандартного отклонения 1 (отклонение единицы). Нормализация полезна, когда все параметры должны иметь идентичный положительный масштаб, однако выбросы из набора данных теряются.Следовательно, для большинства приложений рекомендуется стандартизация.
35. Перечислите наиболее популярные кривые распределения вместе со сценариями, в которых вы будете использовать их в алгоритме.
Наиболее популярные кривые распределения: распределение Бернулли, равномерное распределение, биномиальное распределение, нормальное распределение, распределение Пуассона и экспоненциальное распределение.
Каждая из этих кривых распределения используется в различных сценариях.
Распределение Бернулли можно использовать для проверки того, выиграет ли команда чемпионат или нет, новорожденный ребенок мужского или женского пола, вы сдаете экзамен или нет и т. Д.
Равномерное распределение — это распределение вероятностей с постоянной вероятностью. Один из примеров — бросание одного кубика, потому что оно имеет фиксированное количество результатов.
Биномиальное распределение — это вероятность только с двумя возможными исходами, приставка «би» означает два или два. Примером этого может быть подбрасывание монеты. В результате будет решка или решка.
Нормальное распределение описывает, как распределяются значения переменной.Обычно это симметричное распределение, при котором большая часть наблюдений группируется вокруг центрального пика. Значения дальше от среднего сужаются одинаково в обоих направлениях. Примером может служить рост учеников в классе.
Распределение Пуассона помогает предсказать вероятность возникновения определенных событий, если вы знаете, как часто это событие происходило. Он может использоваться бизнесменами для прогнозирования количества клиентов в определенные дни и позволяет им корректировать предложение в соответствии со спросом.
Экспоненциальное распределение касается количества времени до наступления определенного события. Например, сколько времени хватит на автомобильный аккумулятор в месяцах.
36. Как проверить нормальность набора данных или объекта?
Визуально можно проверить с помощью графиков. Существует список проверок на нормальность, они следующие:
- Тест Шапиро-Уилка W
- Тест Андерсона-Дарлинга
- Тест Мартинеса-Иглевича
- Тест Колмогорова-Смирнова
- Тест Д’Агостино 1 37.Что такое линейная регрессия?
- Линейная зависимость
- Многомерная нормальность
- Нет или небольшая мультиколлинеарность
- Нет автокорреляции
- Гомоскедастичность
- K-свертка
- Стратифицированная k-свертка
- Оставить одну
- Загрузочная загрузка
- Случайный поиск cv
- Поиск по сетке cv 9044 . Можно ли проверить вероятность повышения точности модели без методов перекрестной проверки? Если да, объясните, пожалуйста.
- Нелинейные преобразования не могут удалить перекрытие между двумя классами, но они могут увеличить перекрытие.
- Часто неясно, какие базовые функции лучше всего подходят для данной задачи.Таким образом, изучение основных функций может быть полезно вместо использования фиксированных базисных функций.
- Если мы хотим использовать только фиксированные, мы можем использовать много из них и позволить модели определить наилучшее соответствие, но это приведет к переобучению модели, что сделает ее нестабильной.
- Мы предполагаем, что Y линейно зависит от X при применении линейной регрессии.
- Мы предполагаем, что существует гиперплоскость, разделяющая отрицательный и положительный примеры.
- Он может учиться на каждом этапе онлайн или офлайн.
- Он также может учиться на неполной последовательности.
- Может работать в непрерывных средах.
- Он имеет меньшую дисперсию по сравнению с методом MC и более эффективен, чем метод MC.
- Это необъективная оценка.
- Более чувствителен к инициализации.
- Избегает сложных выборов
- Якоря на первой части информации, которую он видит
- Под влиянием социальных факторов и
- Легко стимулируется визуальными эффектами
Линейная функция может быть определена как математическая функция на двухмерной плоскости как Y = Mx + C, где Y — зависимая переменная, X — независимая переменная, C — точка пересечения, M — наклон, и то же самое может быть выражено как Y является функцией X или Y = F (x).
При любом заданном значении X можно вычислить значение Y, используя уравнение Line. Это отношение между Y и X со степенью полинома, равной 1, называется линейной регрессией.
В прогнозном моделировании LR представляется как Y = Bo + B1x1 + B2x2
Значение B1 и B2 определяет силу корреляции между функциями и зависимой переменной.
Пример: Стоимость акции в $ = Перехват + (+/- B1) * (Начальная стоимость акций) + (+/- B2) * (Наивысшая стоимость акций в предыдущий день)
38. Различия между регрессией и классификацией .
Регрессия и классификация относятся к одной категории машинного обучения с учителем. Основное различие между ними состоит в том, что выходная переменная в регрессии является числовой (или непрерывной), а для классификации — категориальной (или дискретной).
Пример: Прогнозирование определенной температуры места — это задача регрессии, тогда как прогнозирование того, будет ли день солнечным, облачным или будет дождь, является случаем классификации.
39. Что такое целевой дисбаланс? Как это исправить? Сценарий, в котором вы выполнили целевой дисбаланс данных. Какие показатели и алгоритмы вы считаете подходящими для ввода этих данных?
Если у вас есть категориальные переменные в качестве целевых, когда вы объединяете их вместе или выполняете частотный подсчет для них, если есть определенные категории, которых больше по сравнению с другими на очень значительное число.Это известно как целевой дисбаланс.
Пример: Целевой столбец — 0,0,0,1,0,2,0,0,1,1 [0s: 60%, 1: 30%, 2: 10%] 0 — большинство. Чтобы исправить это, мы можем выполнить повышающую или понижающую дискретизацию. Прежде чем исправлять эту проблему, предположим, что используемые показатели производительности были метриками заблуждения. После устранения этой проблемы мы можем перенести метрическую систему на AUC: ROC. Поскольку мы добавляли / удаляли данные [повышающая или понижающая дискретизация], мы можем использовать более строгий алгоритм, такой как SVM, повышение градиента или усиление ADA.
40. Перечислите все допущения для данных, которые должны быть выполнены, прежде чем начинать линейную регрессию.
Перед началом линейной регрессии необходимо выполнить следующие допущения:
Место, где находится наивысшее значение RSquared, — это место, где линия останавливается.RSquared представляет собой величину отклонения, зафиксированного линией виртуальной линейной регрессии, относительно общей дисперсии, зафиксированной набором данных.
42. Почему логистическая регрессия — это метод классификации, а не регрессия? Назовите функцию, от которой она получена?
Поскольку целевой столбец является категориальным, он использует линейную регрессию для создания нечетной функции, которая обернута функцией журнала для использования регрессии в качестве классификатора. Следовательно, это метод классификации, а не регрессия.Он выводится из функции стоимости.
43. В чем может быть проблема, если бета-значение для определенной переменной слишком сильно различается в каждом подмножестве, когда регрессия выполняется на разных подмножествах данного набора данных?
Вариации значений бета в каждом подмножестве подразумевают, что набор данных неоднороден. Чтобы преодолеть эту проблему, мы можем использовать другую модель для каждого из кластеризованных подмножеств набора данных или использовать непараметрическую модель, такую как деревья решений.
44.Что означает термин «коэффициент инфляции дисперсии»?
Коэффициент инфляции вариации (VIF) — это отношение дисперсии модели к дисперсии модели только с одной независимой переменной. VIF дает оценку объема мультиколлинеарности в наборе многих регрессионных переменных.
VIF = Дисперсия модели Дисперсия модели с одной независимой переменной
45. Какой алгоритм машинного обучения известен как ленивый ученик и почему он так называется?
KNN — это алгоритм машинного обучения, известный как ленивый ученик.K-NN — ленивый ученик, потому что он не изучает какие-либо машинные значения или переменные из обучающих данных, а динамически вычисляет расстояние каждый раз, когда он хочет классифицировать, поэтому вместо этого запоминает обучающий набор данных.
Вопросы для собеседования по Python
Вот список из 101 самых популярных вопросов на собеседовании с ответами, которые помогут вам подготовиться. Первый набор вопросов и ответов предназначен для новичков, а второй предназначен для опытных пользователей.
Что такое функции в Python?
Функции в Python относятся к блокам, которые имеют организованные и многократно используемые коды для выполнения отдельных и связанных событий.Функции важны для создания лучшей модульности для приложений, которые многократно используют высокую степень кодирования. Python имеет ряд встроенных функций. подробнее…
Что такое фреймы данных?
Фрейм данных pandas — это изменяемая структура данных в pandas. Pandas поддерживает разнородные данные, расположенные по двум осям (строки и столбцы).
Чтение файлов в пандах: — Подробнее…
46. Можно ли использовать KNN для обработки изображений?
Да, KNN можно использовать для обработки изображений.Это можно сделать, преобразовав трехмерное изображение в одномерный вектор и используя его в качестве входных данных для KNN.
47. Чем отличаются алгоритмы K-средних от алгоритмов KNN?
KNN — это обучение с учителем, тогда как K-Means — это обучение без учителя. С помощью KNN мы прогнозируем метку неидентифицированного элемента на основе его ближайшего соседа и дополнительно расширяем этот подход для решения проблем на основе классификации / регрессии.
K-средних — это обучение без учителя, при котором у нас нет никаких меток, другими словами, нет целевых переменных, и поэтому мы пытаемся кластеризовать данные на основе их координат и пытаемся установить природу кластера на основе элементы, отфильтрованные для этого кластера.
48. Как алгоритм SVM справляется с самообучением?
SVM имеет скорость обучения и скорость расширения, которые заботятся об этом. Скорость обучения компенсирует или наказывает гиперплоскости за все неправильные движения, а скорость расширения связана с поиском максимальной области разделения между классами.
49. Что такое ядра в SVM? Перечислите популярные ядра, используемые в SVM, а также сценарий их приложений.
Функция ядра — принимать данные в качестве входных и преобразовывать их в требуемую форму.Несколько популярных ядер, используемых в SVM: RBF, Linear, Sigmoid, Polynomial, Hyperbolic, Laplace и т. Д.
50. Что такое трюк с ядром в алгоритме SVM?
Уловка с ядром — это математическая функция, которая при применении к точкам данных может найти область классификации между двумя разными классами. На основе выбора функции, будь то линейная или радиальная, которая полностью зависит от распределения данных, можно построить классификатор.
51.Что такое ансамблевые модели? Объясните, как ансамблевые методы обеспечивают лучшее обучение по сравнению с традиционными классификационными алгоритмами машинного обучения?
Ансамбль — это группа моделей, которые используются вместе для прогнозирования как в классе классификации, так и в классе регрессии. Ансамблевое обучение помогает улучшить результаты машинного обучения, поскольку объединяет несколько моделей. Таким образом обеспечивается лучшая прогнозирующая способность по сравнению с одной моделью.
Они превосходят отдельные модели, поскольку уменьшают дисперсию, усредняют систематические ошибки и имеют меньшие шансы переобучения.
52. Что такое переоборудование и неполное оснащение? Почему алгоритм дерева решений часто страдает проблемой переобучения?
Переобучение — это статистическая модель или алгоритм машинного обучения, который улавливает шум данных. Недообучение — это модель или алгоритм машинного обучения, который недостаточно хорошо соответствует данным и возникает, если модель или алгоритм показывают низкую дисперсию, но высокую систематическую ошибку.
В деревьях решений переобучение происходит, когда дерево спроектировано так, чтобы идеально соответствовать всем выборкам в наборе обучающих данных.Это приводит к появлению ветвей со строгими правилами или разреженными данными и влияет на точность при прогнозировании выборок, не входящих в обучающий набор.
Также читайте: Переоснащение и недостаточное оснащение в машинном обучении
53. Что такое ошибка OOB и как она возникает?
Для каждой выборки начальной загрузки есть одна треть данных, которые не использовались при создании дерева, т. Е. Были вне выборки. Эти данные называются данными вне сумки. Чтобы получить объективную оценку точности модели по данным испытаний, используется ошибка вне пакета.Данные об отсутствии пакета передаются для каждого дерева, проходящего через это дерево, и выходные данные объединяются для выдачи ошибки отсутствия пакета. Эта процентная ошибка весьма эффективна при оценке ошибки в тестовом наборе и не требует дальнейшей перекрестной проверки.
54. Почему усиление более стабильный алгоритм по сравнению с другими алгоритмами ансамбля?
Boosting фокусируется на ошибках, обнаруженных в предыдущих итерациях, до тех пор, пока они не станут устаревшими. А в мешках нет корректирующей петли.Вот почему повышение — более стабильный алгоритм по сравнению с другими алгоритмами ансамбля.
55. Как вы обрабатываете выбросы в данных?
Выброс — это наблюдение в наборе данных, которое находится далеко от других наблюдений в наборе данных. Мы можем обнаруживать выбросы с помощью инструментов и функций, таких как прямоугольная диаграмма, диаграмма рассеяния, Z-оценка, оценка IQR и т. Д., А затем обрабатывать их на основе полученной визуализации. Для обработки выбросов мы можем ограничить некоторый порог, использовать преобразования, чтобы уменьшить асимметрию данных и удалить выбросы, если они являются аномалиями или ошибками.
56. Перечислите популярные методы перекрестной проверки.
Существует шесть основных методов перекрестной проверки. Они выглядят следующим образом:
Да, можно проверить вероятность повышения точности модели без методов перекрестной проверки. Мы можем сделать это, запустив модель машинного обучения, скажем, для числа итераций n , записав точность. Постройте график всей точности и удалите 5% значений низкой вероятности. Измерьте отсечку левого [нижнего] и правого [верхнего] угла. С оставшейся достоверностью 95% мы можем сказать, что модель может быть как низкой, так и высокой [как указано в пределах точек отсечения].
58.Назовите популярный алгоритм уменьшения размерности.
Популярными алгоритмами уменьшения размерности являются анализ главных компонентов и факторный анализ.
«Анализ главных компонентов» создает одну или несколько индексных переменных из большего набора измеряемых переменных. Факторный анализ — это модель измерения скрытой переменной. Эта скрытая переменная не может быть измерена с помощью одной переменной и рассматривается через взаимосвязь, которую она вызывает в наборе из и переменных.
59.Как мы можем использовать набор данных без целевой переменной в алгоритмах контролируемого обучения?
Введите набор данных в алгоритм кластеризации, сгенерируйте оптимальные кластеры, пометьте номера кластеров как новую целевую переменную. Теперь в наборе данных присутствуют независимые и целевые переменные. Это гарантирует, что набор данных готов для использования в алгоритмах контролируемого обучения.
60. Перечислите все типы популярных рекомендательных систем? Назовите и объясните две персонализированные системы рекомендаций, а также простоту их применения.
Рекомендация на основе популярности, рекомендация на основе содержимого, фильтр совместной работы на основе пользователя и рекомендация на основе элементов — популярные типы систем рекомендаций.
Системы персонализированных рекомендаций — это рекомендации на основе содержимого, совместный фильтр на основе пользователей и рекомендации на основе элементов. Пользовательский фильтр для совместной работы и рекомендации по элементам стали более персонализированными. Легкость в обслуживании: матрицу сходства можно легко поддерживать с помощью рекомендаций на основе элементов.
61. Как мы справляемся с проблемами разреженности в рекомендательных системах? Как измерить его эффективность? Объясни.
Разложение по сингулярным числам может использоваться для создания матрицы прогнозирования. RMSE — это мера, которая помогает нам понять, насколько близка матрица прогноза к исходной матрице.
62. Назовите и определите методы, используемые для поиска сходств в системе рекомендаций.
Корреляция Пирсона и косинусная корреляция — это методы, используемые для поиска сходства в рекомендательных системах.
63. Укажите ограничения фиксированной базовой функции.
Линейная разделимость в пространстве признаков не означает линейной разделимости в пространстве ввода. Итак, входы нелинейно преобразуются с использованием векторов базовых функций с увеличенной размерностью. Ограничения фиксированных базисных функций:
64. Определите и объясните концепцию индуктивного смещения на некоторых примерах.
Индуктивное смещение — это набор предположений, которые люди используют для прогнозирования выходных данных с учетом входных данных, которые алгоритм обучения еще не обнаружил.Когда мы пытаемся узнать Y из X, а пространство гипотез для Y бесконечно, нам нужно уменьшить объем за счет наших убеждений / предположений о пространстве гипотез, что также называется индуктивным смещением. Посредством этих предположений мы ограничиваем пространство гипотез, а также получаем возможность постепенно проверять и улучшать данные с помощью гиперпараметров. Примеры:
65. Объясните термин «обучение на основе экземпляров».
Обучение на основе экземпляров — это набор процедур для регрессии и классификации, которые производят прогноз метки класса на основе сходства с его ближайшими соседями в наборе обучающих данных. Эти алгоритмы просто собирают все данные и получают ответ при необходимости или запросе. Проще говоря, это набор процедур для решения новых проблем, основанный на решениях уже решенных в прошлом проблем, которые похожи на текущую проблему.
66. Имея в виду критерии разделения обучения и теста, хорошо ли выполнять масштабирование до разделения или после разделения?
В идеале масштабирование должно выполняться после тренировки и тестового разделения. Если данные плотно упакованы, то масштабирование поста или предварительного разделения не должно иметь большого значения.
67. Определите точность, отзывчивость и оценку F1?
Метрика, используемая для доступа к производительности модели классификации, — это метрика смешения. Метрику замешательства можно дополнительно интерпретировать с помощью следующих терминов: —
Истинные положительные значения (TP) — это правильно спрогнозированные положительные значения.Это означает, что значение фактического класса — да, а значение предсказанного класса — также да.
Истинные отрицательные значения (TN) — это правильно спрогнозированные отрицательные значения. Это означает, что значение фактического класса — нет, и значение предсказанного класса также нет.
Ложные срабатывания и ложные отрицания , эти значения возникают, когда ваш фактический класс противоречит предсказанному классу.
Теперь,
Напомним, , также известное как Чувствительность, — это отношение истинно положительной скорости (TP) ко всем наблюдениям в реальном классе — да
Отзыв = TP / (TP + FN)
Precision is коэффициент положительной предсказательной ценности, который измеряет количество точных положительных результатов, предсказанных моделью, а именно количество положительных результатов, которые она утверждает.
Точность = TP / (TP + FP)
Точность — это наиболее интуитивно понятная мера производительности, которая представляет собой просто отношение правильно спрогнозированных наблюдений к общему количеству наблюдений.
Точность = (TP + TN) / (TP + FP + FN + TN)
Оценка F1 — это средневзвешенное значение точности и отзыва. Таким образом, эта оценка учитывает как ложные срабатывания, так и ложные отрицательные результаты. Интуитивно это не так просто понять, как точность, но F1 обычно более полезен, чем точность, особенно если у вас неравномерное распределение классов.Точность работает лучше всего, если ложные срабатывания и ложные отрицания имеют одинаковую стоимость. Если стоимость ложных срабатываний и ложноотрицательных результатов сильно различается, лучше смотреть как на точность, так и на отзыв.
68. Постройте оценку валидации и оценки обучения с размером набора данных на оси x, а другой график со сложностью модели на оси x.
Для высокого смещения в моделях производительность модели на наборе данных проверки аналогична производительности на наборе данных обучения.Для высокой дисперсии моделей производительность модели на проверочном наборе хуже, чем производительность на обучающем наборе.
69. Что такое теорема Байеса? Укажите хотя бы один вариант использования в контексте машинного обучения?
Теорема Байеса описывает вероятность события, основанную на предварительном знании условий, которые могут быть связаны с событием. Например, если рак связан с возрастом, то, используя теорему Байеса, возраст человека можно использовать для более точной оценки вероятности того, что он болен раком, чем это можно сделать без знания возраста человека.
Цепное правило байесовской вероятности может использоваться для предсказания вероятности следующего слова в предложении.
70. Что такое наивный байесовский метод? Почему это наивно?
Наивные байесовские классификаторы — это серия алгоритмов классификации, основанных на теореме Байеса. Это семейство алгоритмов разделяет общий принцип, согласно которому каждая пара признаков обрабатывается независимо при классификации.
Наивный байесовский метод считается наивным, потому что атрибуты в нем (для класса) не зависят от других в том же классе.Это отсутствие зависимости между двумя атрибутами одного и того же класса создает качество наивности.
Узнайте больше о Наивном Байесе.
71. Объясните, как работает наивный байесовский классификатор.
Наивные байесовские классификаторы — это семейство алгоритмов, выведенных из теоремы вероятности Байеса. Он работает на основе фундаментального предположения, что каждый набор из двух классифицируемых характеристик независим друг от друга, и каждая функция вносит равный и независимый вклад в результат.
72. Что означают термины «априорная вероятность» и «маргинальная вероятность» в контексте наивной теоремы Байеса?
Априорная вероятность — это процент зависимых двоичных переменных в наборе данных. Если вам дан набор данных, и зависимая переменная равна 1 или 0, процент от 1 равен 65%, а процент от 0 равен 35%. Тогда вероятность того, что любой новый вход для этой переменной будет равен 1, составит 65%.
Предельное правдоподобие является знаменателем уравнения Байеса, и оно обеспечивает правильность апостериорной вероятности, делая ее площадь равной 1.
73. Объясните разницу между Лассо и Ридж?
Лассо (L1) и Ридж (L2) — это методы регуляризации, при которых мы штрафуем коэффициенты, чтобы найти оптимальное решение. В ридже штрафная функция определяется суммой квадратов коэффициентов, а для лассо мы штрафуем сумму абсолютных значений коэффициентов. Другой тип метода регуляризации — ElasticNet, это гибридная функция штрафов лассо и гребня.
74.В чем разница между вероятностью и правдоподобием?
Вероятность — это мера вероятности того, что событие произойдет, то есть какова уверенность в том, что конкретное событие произойдет? Где-как функция правдоподобия — это функция параметров в пространстве параметров, которая описывает вероятность получения наблюдаемых данных.
Итак, фундаментальное различие состоит в том, что вероятность привязана к возможным результатам; вероятность придает гипотезам.
75.Зачем вам обрезать дерево?
В контексте науки о данных или AIML сокращение означает процесс сокращения избыточных ветвей дерева решений. Деревья решений склонны к переобучению, обрезка дерева помогает уменьшить размер и сводит к минимуму шансы переобучения. Сокращение включает превращение ветвей дерева решений в листовые узлы и удаление листовых узлов из исходной ветви. Он служит инструментом для достижения компромисса.
76.Точность модели или характеристики модели? Какой из них вы предпочтете и почему?
Это вопрос с подвохом, сначала нужно получить четкое представление, что такое «производительность модели»? Если под производительностью подразумевается скорость, то это зависит от природы приложения, любое приложение, связанное со сценарием реального времени, будет нуждаться в высокой скорости как важной функции. Пример: Лучшие результаты поиска потеряют свою силу, если результаты запроса не появятся быстро.
Если Производительность намекает на то, почему Точность не является самым важным достоинством — Для любого несбалансированного набора данных, большего, чем Точность, это будет оценка F1, чем объясняется экономическое обоснование, а в случае несбалансированных данных будут Точность и Отзыв. быть важнее отдыха.
77. Перечислите преимущества и ограничения метода обучения временной разнице.
Метод обучения временной разнице представляет собой смесь метода Монте-Карло и метода динамического программирования. Некоторые из преимуществ этого метода включают:
Ограничения метода TD:
78. Как бы вы поступили с несбалансированным набором данных?
Методы выборки могут помочь с несбалансированным набором данных. Существует два способа выполнения выборки: недостаточная выборка или избыточная выборка.
В разделе «Недостаточная выборка» мы уменьшаем размер класса большинства, чтобы он соответствовал классу меньшинства, тем самым помогая улучшить производительность w.r.t хранилище и выполнение во время выполнения, но потенциально может отбрасывать полезную информацию.
Для избыточной выборки мы повышаем дискретизацию класса Minority и, таким образом, решаем проблему потери информации, однако мы сталкиваемся с проблемой переобучения.
Есть o
2020 Easy Guide [+ Учебники по обработке]
Изучите основы ЧПУ: общая картина и концепции
Лично я всегда начинаю с общей картины и основных концепций. Они являются основой для более глубокого понимания и дают вам важнейший обзор того, как большие части соединяются в головоломке.После того, как вы освоите основы ЧПУ, вы можете углубиться в детали и изучить ЧПУ небольшими порциями.
Этот вид «большого изображения» будет казаться вполне нормальным, если вы планируете зарабатывать на жизнь в мире производства ЧПУ. Но многие любители хотят сразу же купить или построить станок с ЧПУ.
Дело вот в чем — сначала изучите основы ЧПУ, прежде чем пытаться приобрести станок. Понимание этих основ ЧПУ поможет вам понять спецификации и документацию вашего потенциального нового станка.Они помогут вам понять, о чем говорят люди на форумах (отличные обучающие ресурсы!). Это потенциально может сэкономить вам деньги и сэкономить нервы.
Вот общая картина, которая поможет вам освоить базовые концепции ЧПУ быстро .
Big Picture: пошаговое руководство по изготовлению деталей с ЧПУ
Есть 9 шагов, чтобы сделать деталь ЧПУ, описанную ниже. Щелкните заголовок любого, чтобы развернуть и просмотреть сведения о каждом шаге.
1
Результат: создание идеальной CAD-модели детали
Спроектируйте деталь в программе САПР на основе эскизов, фотографий, спецификаций и любых других идей, которые у нас есть для детали. Деталь помечена как «Идеализированная», потому что мы еще не сделали серьезной домашней работы, чтобы оценить, насколько легко будет ее изготовить. Опытные конструкторы смогут избежать многих производственных проблем на этом этапе, в то время как новички обнаружат, что им нужно немного изменить, чтобы упростить изготовление детали.
2
Результат: готовая модель САПР + схема установки, которая представляет собой план изготовления детали
80% затрат на изготовление продукта определяется на этапе проектирования…
На этом этапе мы оценим, насколько легко изготовить нашу деталь, изменим конструкцию по желанию, чтобы упростить производство, и составим план изготовления детали, который мы зафиксируем в нашей схеме установки .
3
Результат: программа детали G-кода + готовая таблица настроек
Использование MeshCAM для создания программы части G-кода…
Вооружившись моделью САПР и нашим планом наладки, мы готовы погрузиться в CAM, диалоговое программирование, ручное кодирование или любой другой метод, который мы хотим использовать для создания программы части G-кода.
4
Результат: Станок с ЧПУ настроен для запуска детали
На установкемы получаем все станки с ЧПУ, готовые к запуску детали. Нам нужно убедиться, что в устройстве смены инструмента есть все необходимые инструменты, загружена нужная программа gcode и в целом машина готова к работе.
5
Результат: программа проверена, часть готова к запуску
Проверка программы — это последний шаг перед фактическим сокращением.Целью проверки является проверка правильности программы и правильной настройки станка с ЧПУ, чтобы не было проблем при первом запуске g-кода. Проверка может быть выполнена либо с помощью воздушной резки (простой, но очень трудоемкий), либо с помощью симулятора ЧПУ (также называемого симулятором G-кода).
Щелкните заголовок раздела, чтобы развернуть его и выбрать лучший вариант.
6
Результат поставки: детали с ЧПУ
После всей подготовки мы наконец-то готовы производить стружку и обрабатывать деталь с ЧПУ.
7
Результат поставки: проверенные детали, готовые к отделке
После завершения обработки с ЧПУ пришло время для контроля качества. Мы проверим детали, чтобы убедиться, что они соответствуют требуемым спецификациям, допускам и качеству поверхности.
8
Результат поставки: Часть готова!
Наш последний шаг — отделка деталей. Это необязательно, так как нашим частям это может не потребоваться. Но существует множество возможных форм отделки — от окраски до анодирования, дробеструйной обработки и многого другого.
4 способа превратить ваш веб-сайт в машину для экономичного среднего преобразования
Покупка — это решение.
Выбор электронной почты — это решение.
Хотите больше конверсий? Вы должны понимать, как человеческий мозг принимает решения.
Подавляющее большинство (более 98%) решений принимается подсознательно самой старой частью человеческого мозга. Вся осознанная мысленная обработка происходит, что люди обычно считают «взвешиванием своих вариантов», на самом деле происходит после того, как решение уже принято — как способ оправдать решение путем добавления логики к выбору.
Это очень важно для маркетологов, потому что старый мозг работает очень быстро и ищет ярлыки, которые помогут ему быстро принимать решения.
Если вы хотите, чтобы ваш веб-сайт эффективно конвертировался, вы должны сначала признать, что вы не можете сделать это с помощью логики и слов, как бы убедительно они ни были написаны.
Но можно влиять эмоциями.
Вот четыре способа создания эффективных веб-страниц, которые поддержат процесс принятия решений и помогут вашим посетителям совершить конверсию.
1. Создайте небольшое количество четких выборов
Существует заблуждение, что свобода выбора — это всегда хорошо.
Если вы предоставите сотни сортов на выбор, люди обязательно найдут то, что им нравится, верно?
На самом деле, предоставление людям слишком большого количества вариантов вызывает когнитивную перегрузку, которая приводит к параличу выбора. Это очень похоже на то, как компьютер может зависнуть или даже дать сбой, если вы откроете слишком много программ одновременно. За исключением того, что, столкнувшись с необходимостью принятия трудного решения, человеческий мозг выбирает более легкий путь: полностью приостановить или отказаться от процесса принятия решения.
Проще говоря, посетители, которым предлагалось множество вариантов выбора, в конечном итоге вообще ничего не выбирали.
К сожалению, многие веб-сайты, особенно в сфере электронной коммерции, виновны в том, что мы в индустрии оптимизации конверсии называем «рвотой по всему посетителю». Например, когда вы ищете художественные кисти на Artdiscount.co.uk, это похоже на то, что вас бросили в дикую природу и вам нужно искать нужную кисть из 239 других кистей:
Fineartstore.com работает лучше. Вместо того, чтобы позволять онлайн-покупателям выбирать все 57 вариантов художественной кисти, их сайт помогает посетителям сузить круг выбора конкретной кисти, которую они хотят, путем классификации кистей в зависимости от их назначения.
Хотя этот пример далек от совершенства, он дает вам представление о том, как вы можете направлять посетителей к тому, что они ищут, облегчая когнитивную нагрузку, давая мозгу ряд небольших простых решений вместо того, чтобы ожидать, что он обработает избыток информации сразу.
Главное — не перегружать посетителей. По возможности удалите похожие варианты. Помогите посетителям принять решение, представив варианты с очевидными различиями.
2. Используйте большой анкер
Люди имеют тенденцию делать предположения о вещах, основываясь на первой части информации, которую им дают.
Это называется привязкой и играет важную роль в наших процессах принятия решений. Как люди, мы автоматически «привязываемся» к первому, что видим, то есть мы оцениваем последующие фрагменты информации на основе того, что им предшествует.
Например, если вы были в супермаркете, пытаясь купить шампунь, и увидели один, который стоит 2 доллара, а другой, который продается за 20 долларов за бутылку того же размера, вы подумаете, что последняя цена колоссальная. Однако, если вы впервые увидели бутылку за 20 долларов, вы можете подумать о покупке той, которая находится в средней ценовой категории, но может с подозрением относиться к качеству шампуня за 2 доллара.
Якоря служат ориентирами при принятии решений. Поэтому вы должны быть очень осторожны с тем, как вы представляете информацию на своем веб-сайте.В этом примере из программного обеспечения для управления проектами Teamwork потенциальному клиенту предоставляется пять вариантов ежемесячной подписки с ценами от 12 до 149 долларов. Хотя посетитель может сначала обратить внимание на выделенный популярный план, вы можете поспорить, что он привязан к плану за 12 долларов, поскольку он предоставляется в качестве первого варианта.
Другой поставщик программного обеспечения для управления проектами, Easy Projects , с другой стороны, четко знает о привязке. На их странице с ценами сначала отображается самый дорогой вариант, затем идет их «самый популярный» профессиональный план, а затем последний бесплатный план для одиночных пользователей.
Якорь имеет огромное влияние на посетителей вашего веб-сайта, поэтому не принимайте это как должное. Презентация должна быть продуманной, с целью побудить посетителей принять решение. Вы можете отображать продукты в порядке убывания цен или добавлять новые высококачественные товары, чтобы перемещать продажи среди аналогов по разумной цене.
3. Определите свое культурное племя
Люди глубоко связаны с племенами.
На наше поведение сильно влияет наша племенная идентичность — разные племена, к которым мы принадлежим случайно (например,ж., национальность) или предпочтения (например, фанат научной фантастики). Мы жаждем общественного признания и ищем одобрения у других, особенно у представителей нашего племени. Следовательно, если вы хотите, чтобы ваши страницы были более убедительными, вам нужно знать не только, кто ваша целевая аудитория, но и к каким «племенам» они присоединяются.
Большинство маркетологов понимают важность социального влияния, но важным нюансом этого убедительного принципа является тот факт, что на людей больше влияют люди, похожие на них, или те, с кем они имеют культурную близость.
Убедитесь, что посетители в Интернете могут подключиться к вам и почувствовать, что вы принадлежите к их племени, позволяя вашему контенту и тексту отражать ценности, важные для вашей компании, позволяя посетителям начать формировать с вами слабую эмоциональную связь.
Многие компании лишают свой контент и копируют всех следов личности. Результаты часто имеют неприятные последствия, поскольку их страницы становятся не только мягкими, но и общими. Например, копия на домашней странице Comindware гласит, что это «инновационный инструмент для совместной работы и управления проектами.”
Но с таким расплывчатым словом «инновационный» и множеством других инструментов, утверждающих то же самое, эта копия явно не вызывает какой-либо эмоциональной связи или чувства общих ценностей с посетителями.
Сравните тон Comindware и копию с Basecamp , и вы увидите разницу:
Вместо использования двусмысленного жаргона, Basecamp показывает забавный мультфильм, который мгновенно передает его ценность посетителям: это программа для людей, которые хотят завершить даже самые безумные проекты в срок.Кроме того, он использует социальное доказательство в своей копии, сообщая нам, что он помог более 285 000 компаний завершить более 2 миллионов проектов.
Кто бы не поверил, что Basecamp работает с таким огромным племенем?
Вывод состоит в том, что вам нужно приложить усилия, чтобы узнать все о своей аудитории, включая ее страхи, мечты и стремления. Помните, что решения принимают люди даже в B2B. И не бойтесь оттолкнуть посторонних своим редакционным тоном: нельзя всем угождать все время.Люди, которые не разделяют ваших ценностей, с гораздо меньшей вероятностью станут вашими постоянными клиентами.
4. Понять силу визуальных эффектов
Люди — это визуальные существа, и наиболее эффективные веб-сайты создаются для того, чтобы сознательно использовать возможности визуальных эффектов, чтобы помочь посетителям более эффективно принимать решение о покупке.
Половина человеческого мозга предназначена для обработки визуальной информации, что является хорошей или плохой новостью для интернет-маркетологов. Визуальные эффекты могут быть отличным ярлыком, чтобы помочь мозгу прийти к быстрому выбору, но они также могут легко отвлечь посетителей от вашего действия по конверсии.
Распространенная ошибка веб-дизайнеров состоит в том, что большая, великолепная графика — это ключ к радости пользователей, часто за счет удобства использования и оптимизации конверсии. Посетите, например, эту домашнюю страницу маркетинговой компании Gumarketing.com, которая отличается великолепной графикой, но также содержит множество ненужных и отвлекающих движений:
Как вы могли догадаться, страница представляет собой гигантский вращающийся баннер или слайдер, и в тот момент, когда вы на него попадаете, происходит множество вещей.Я с самого начала был против ротации баннеров, потому что это движение отвлекает и раздражает посетителей, затрудняя чтение сообщений, но невозможно игнорировать.
Напротив, на этой домашней странице Web Talent Marketing широко используются изображения, позволяя посетителю узнать, чем занимается компания (доход!). Хотя страницу еще можно улучшить, стоит отметить, что нет ни отвлекающих факторов, ни неожиданных движений, которые могут отвлечь посетителей:
Дело здесь в том, что вы никогда не должны использовать движение, если оно напрямую не поддерживает ваш призыв к действию.Точно так же вы должны использовать графику экономно и целенаправленно, чтобы завоевать доверие посетителей.
Что делать?
Поддержка процесса принятия решений посетителями лежит в основе оптимизации коэффициента конверсии.
Помните, что область мозга, отвечающая за принятие решений…
(Хотите больше идей по оптимизации коэффициента конверсии для вашего сайта? Ознакомьтесь с 32 идеями сплит-тестирования!)
Применяя эти принципы на своем веб-сайте, вы избавитесь от тяжелой психологической нагрузки, которую многие сайты требуют от своих посетителей.