Прометей ВКонтакте. Как попасть?
«Прометей» отметил наше сообщество Targetgirl, и мы стали частью Пантеона авторов.
Я еще не писала об алгоритме «Прометей», хотя каждый уважающий себя автор, связанный с тематикой SMM, уже тысячу раз рассказал о секретах получения заветного огонька – даже не имея опыта его получения!
«Прометей» – это алгоритм, созданный для поиска и поддержки интересных авторов и сообществ. Искусственный интеллект постоянно находит создателей уникального контента и следит за их достижениями.
Зачем каждому SMM-специалисту нужно стремиться получить эту метку?
Метка выдается всего на семь дней, в это время ваши посты получают тысячный охват среди пользователей ВК совершенно бесплатно.
В мобильных приложениях сервис Рекомендаций покажет записи сообщества людям, которые еще не знакомы с ним, но, возможно, заинтересованы в нём.

Сообщество попадет в список приложения «Пантеон авторов».

Так за одну неделю вы можете увеличить охват сообщества в десятки тысяч раз абсолютно бесплатно!
Метка выдается всего на неделю, получить «огонек» можно неограниченное количество раз.
Почему же до сих пор я воздерживалась от рассказов об этом алгоритме?
Думаю, прежде чем говорить о методах его работы и способах получения «огня», сначала нужно стать обладателем этой метки.
Что могу посоветовать тому, кто стремится получить огонек?
Первая категория — творчество:
⁃ Например, вы пишите музыку
⁃ Или стихи
⁃ А может быть фотографируете или рисуете
Получить заветную метку не составит труда. Притом совершенно неважно, сколько в вашем сообществе человек: 10 или 5000. Главное – это уникальность контента. «Прометей» в первую очередь поощряет авторов, которые создают
творческие некоммерческие проекты. И это довольно честно – я говорю как человек, который долгое время увлекался фотографией. Зарабатывать на творчестве довольно трудно, поэтому вкладывать в продвижение затратно и неудобно. Как говорится, «художник должен быть голодным». ВКонтакте с авторами делают хорошее дело, помогая пробиться начинающим талантам.
Зарабатывать на творчестве довольно трудно, поэтому вкладывать в продвижение затратно и неудобно. Как говорится, «художник должен быть голодным». ВКонтакте с авторами делают хорошее дело, помогая пробиться начинающим талантам.
Творите на постоянной основе, старайтесь выкладывать посты каждый день, и получение заветной метки не заставит себя долго ждать.
Вторая категория, которой тоже очень легко получить огонёк от «Прометея» – это путешественники.
Travel-блогинг с каждым днем набирает обороты и приобретает все большую популярность среди людей. Если вы часто путешествуете и постоянно ведете свой блог, выкладываете интересные заметки о культуре и жизни разных стран, снимаете видеоотчеты и красивые фотокарточки, то вам не составит труда получить метку.
Третья категория: это всевозможные коммерческие проекты.
Да, нам с вами придется попотеть, чтобы заинтересовать «Прометея».
 Мы и есть рекламодатели, которые готовы платить за рекламу и продвижение наших сообществ. Довольно справедливо, однако даже у нас с вами есть шанс заполучить огонек.
Мы и есть рекламодатели, которые готовы платить за рекламу и продвижение наших сообществ. Довольно справедливо, однако даже у нас с вами есть шанс заполучить огонек.
Создавайте уникальный контент – это принцип, от которого не отойти. Забудьте о рерайтинге, ищите себе SMMщиков, которые умеют писать (что самое главное) и способны разобраться в вашей теме (т.е. если ваша компания продает психологические тренинги, сммщик обязан разбираться в психологии).
Помимо уникальных текстов вам понадобятся и уникальные картинки высокого качества: фотографии, иллюстрации. Наймите фотографа или найдите себе иллюстратора, который сможет обеспечить вас уникальными изображениями по ТЗ.
Мы рисуем комиксы и иллюстрации к каждому посту
Создавайте контент, который будет вовлекать пользователей в дискуссии. Это могут быть неоднозначные посты на спорные тематики. Главное не переборщите, в интернете очень легко наткнуться на негативных троллей 🙂 Умейте вежливо отстаивать свою точку зрения в комментариях.
Боритесь с негативом, ни в коем случаи не игнорируйте его.
Как, например, тутЗагружайте видео-контент, он лучше ранжируется, нежели обычные фотографии. Загружайте Gif-анимации, это позволит получать наибольший органический охват.
Думайте о своей аудитории. Интересуйтесь, что они хотели бы знать. Не игнорируйте их сообщения. Изучайте свою аудиторию и создавайте по-настоящему полезный и интересный контент для неё.
Проводите интересные трансляции от сообщества.
Подключите приложения сообществ (Инструкция как подключить приложение персонализированного приветствия)
С их помощью можно создавать чаты, продавать билеты на концерт своей группы или принимать пожертвования от подписчиков.Используйте хэштеги, но не злоупотребляйте ими. Если тегов будет больше десяти, запись не отобразится в поиске.
 Боритесь с негативом, ни в коем случаи не игнорируйте его.
Боритесь с негативом, ни в коем случаи не игнорируйте его.
В заключение скажу, что SMM уже давно не копеечное удовольствие и не постинг мимишных картинок с котиками.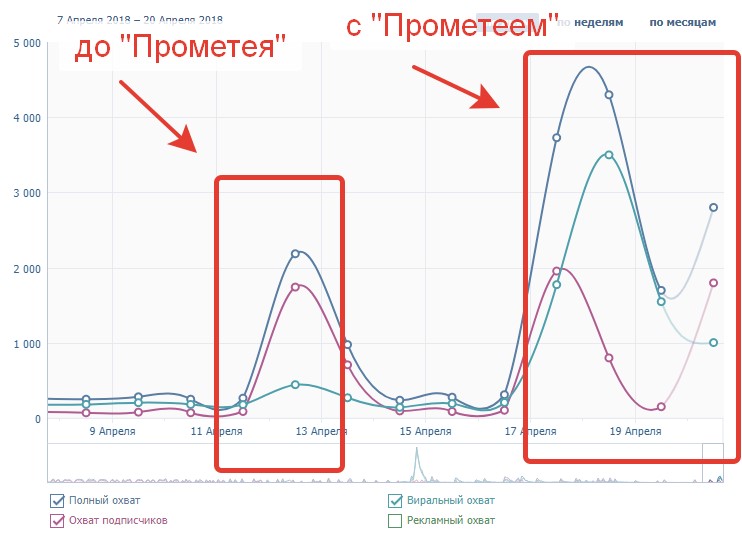 Это огромная работа, порой неблагодарная, но при должном подходе приносящая много радости и лидов 🙂
Это огромная работа, порой неблагодарная, но при должном подходе приносящая много радости и лидов 🙂
Не стремитесь к хайпу. Авторы «ВКонтакте» — о том, как получить метку «Прометея»
По последним данным исследования Brand Analytics, «ВКонтакте» уверенно держит лидерство среди соцсетей в России, причем как по числу публичных сообщений, так и по числу активных авторов.
Пресс-служба «ВКонтакте» утверждает, что ежемесячно «ВКонтакте» посещают 97 миллионов людей, а развивают бизнес более 400 тысяч компаний и предпринимателей.
Соцсеть регулярно обновляет возможности для продвижения бренда или личности, предлагает новые форматы и способы заработка.
Одним из таких усовершенствований стало появление около года назад «умной» ленты рекомендаций и алгоритма «Прометей».
Что такое «Прометей»?
Вы наверняка не раз видели яркий красный значок огня у личных страниц, сообществ или даже у отдельных постов. Вокруг него витает множество легенд и вопросов.
Вокруг него витает множество легенд и вопросов.
Как утверждают создатели, такие метки «раздает» искусственный интеллект за уникальный и интересный контент, помогая талантливым авторам привлечь новых подписчиков и таким образом монетизироваться.
«Прометей» выдается на семь дней, но получать его можно неограниченное количество раз. Если ваше сообщество за последние две недели получало такую метку, то его можно будет найти в «Пантеоне авторов» на странице «ВКонтакте с авторами».
Мы решили разобраться, действительно ли это так, и попросили представителей различных сообществ, которые в 2018 году получали метку «Прометея», рассказать, как им удалось выделиться среди тонны контента в соцсети и какой эффект они получили благодаря нейросети.
Истории «бывалых»: что дает «Прометей»?
«Живописность русских коммуналок»
Направление: фотография
Количество подписчиков: 63 тысячи
Контент этого сообщества состоит из различных эпизодов коммунальной жизни. «Неброские и, на первый взгляд, ничем не примечательные фото пристанищ простого русского человека» стали регулярно появляться на просторах «ВКонтакте» в конце 2014 года. На другие соцсети авторы на данный момент не транслируют контент.
«Неброские и, на первый взгляд, ничем не примечательные фото пристанищ простого русского человека» стали регулярно появляться на просторах «ВКонтакте» в конце 2014 года. На другие соцсети авторы на данный момент не транслируют контент.
Впервые группа получила значок «Прометея» в конце октября 2017 года, и с тех пор алгоритм выбирал их не менее шести раз.
Дарья, представитель сообщества «Живописность русских коммуналок»:
«Наша аудитория – это люди, ностальгирующие по былым временам. Большая часть из них – молодежь от восемнадцати до двадцати четырех лет. Но есть и люди 45+, которые не понаслышке застали времена коммунальных квартир.
Объединяет их общее понимание эстетики и некая русская боль. Кто-то так жил раньше и теперь пытается мысленно вернуться из благоустроенной квартиры в коммуналку, кто-то так живет сейчас и хочет найти в этом хоть что-то прекрасное, а кто-то не жил и не живет – ему нравится наблюдать.
Просто, когда страна переживает не лучшие времена, люди всегда пытаются успокоиться и найти хорошее даже в плохом.
На создание такой группы меня сподвиг незнакомый мужчина, который выглянул из окна коммунальной пятиэтажки и заорал: «Е*** я жить в этом дерьме!».
По большей части нам предлагают новости сами участники, поэтому схожие материалы в интернете вы вряд ли найдете. Думаю, что именно за оригинальный контент мы и были отмечены огоньком «Прометея».
Эффект от метки был более чем ощутимый. Самый большой объем просмотров нашей группы приходится как раз на время нашей «дружбы» с «Прометеем»: просмотры на стене (по разделу статистика) переваливают за полтора миллиона, хотя обычно записи смотрит порядка 50 тысяч человек.
«Прометей» помог набрать значительную часть нашей аудитории – благодаря метке она увеличилась в полтора-два раза.
Наша группа не является коммерческой, интересные проекты мы публикуем бесплатно, чтобы рассказать о них миру. Пару раз у нас покупали рекламу агентства по обучению дизайна, но это в большей степени связано с тематикой и количеством участников группы, а на количество в определенной мере повлиял именно значок.
Пару раз у нас покупали рекламу агентства по обучению дизайна, но это в большей степени связано с тематикой и количеством участников группы, а на количество в определенной мере повлиял именно значок.
В качестве совета могу сказать, что в интернете очень много хлама, поэтому не нужно плодить сотни одинаковых проектов, лучше сфокусируйтесь на чем-нибудь одном и креативьте с подачей, будьте оригинальными».
«Ahriman aka Дмитрий Грозов»
Направление: художник
Количество подписчиков: 43 тысячи
Дмитрий Грозов или Ahriman размещает в паблике свое творчество: иллюстрации, анимацию, аниме-арты на разные фильмы, портреты на заказ. Само сообщество он создал еще в 2012 году, но активно начал его вести только год назад.
Сейчас все спонтанные идеи и проекты автор первым делом выкладывает в паблик, собирая мнения и отзывы. Проект неоднократно был отмечен огнем «Прометея».
Дмитрий Грозов, основатель сообщества «Ahriman aka Дмитрий Грозов»:
«В своем творчестве я совмещаю столько разных вещей, что у меня просто нет какой-то четкой аудитории. Если честно, я даже не понимаю, как у меня иногда выходит угодить всем подписчикам сразу.
Но уже можно точно сказать, что мои работы начали узнавать стилистически, даже без всяких подписей. Сейчас все русскоязычные заказчики выходят на меня именно через «ВКонтакте»: либо напрямую из паблика, либо из новостной ленты.
Да, конечно, это далеко не единственный ресурс для меня по продвижению и поиску клиентов. Я также использую и англоязычные соцсети, и различные сайты для художников.
У каждого из них своя специфика, своя аудитория. Контент, который я там публикую, редко отличается, а вот реакция и спрос различны.
С «Прометеем» количество просмотров во «ВКонтакте» повышалось в несколько раз.
 Как следствие, увеличивалось количество подписчиков и потенциальных заказчиков.
Как следствие, увеличивалось количество подписчиков и потенциальных заказчиков.Я считаю, что заполучить заветный огонек и аудиторию не так сложно. Гораздо сложнее – их удержать в долгосрочной перспективе при нынешней конкуренции в сети.
Так что я бы не советовал стремиться к хайпу или угождать кому-то. Это все очень быстро проходит и надоедает, а настоящая аудитория тянется только к искренности в творчестве и к тому, что вы в него вкладываете».
Running «GoRun»
Направление: сообщество бегунов
Количество подписчиков: 44 тысячи
Своей ключевой целью сообщество преследует объединение людей, ведущих активный образ жизни.
В паблике участники делятся своими тренировками, дают советы, общаются на разные темы, помогая мотивировать друг друга, периодически проходят беговые соревнования, челленджи и флешмобы.
Группа создана в ноябре 2015 года. Как отмечают авторы, идея пришла из потребности заниматься любимым видом спорта и общаться с единомышленниками. Впервые «Прометей» отметил сообщество в конце 2017 года, всего было около пяти отметок.
Анатолий Атабаев, представитель сообщества Running «GoRun»:
«Благодаря «Прометею» мы получаем в среднем около 16 тысяч новых подписчиков и рекламодателей. Если говорить про охват, то, как правило, средний охват постов составляет от восьми до двенадцати тысяч просмотров, а на неделе с огнем увеличивается в 30-50 раз.
Кроме «ВКонтакте», мы ведем профиль в Instagram. Там аудитория предпочитает яркие, удачные фотографии, и текстовая составляющая отходит на второй план.
Если сравнивать, то наш контент «ВКонтакте» более сбалансирован, подписчики проявляют активность к живым, настоящим постам, оценивают эффективность тренировок.
Но я бы не стал недооценивать влияние визуальной составляющей и здесь – помимо уникальных текстов, в борьбе за «Прометея» вам понадобятся уникальные иллюстрации и видео. Избегайте копирования чужих записей».
Избегайте копирования чужих записей».
David Novikov
Направление: личная страница, музыкант
Количество подписчиков: 11 тысяч
Давид Новиков или «мц горемыка» использует личную страницу «ВКонтакте» для продвижения своего музыкального творчества, регулярно выпуская аудио- и видеозаписи песен. За 2018 год он получил «Прометея» дважды.
Давид Новиков, владелец страницы David Novikov:
«Я просто смотрю на свои жизненные обстоятельства, настроение и пишу об этом песни. Моя аудитория — это подростки и молодежь, причем в основном мужского пола. Я использую YouTube, Instagram для продвижения, но «ВКонтакте» помогает сильнее благодаря возможности репостов, рекомендаций и добавления видеозаписей.
«Прометей» оба раза принес ощутимый эффект: на одном из постов охват видео был более шести миллионов просмотров.
 И прибавилось около шести тысяч подписчиков.
И прибавилось около шести тысяч подписчиков.Видеоконтент сейчас в тренде. Я рекомендую загружать напрямую все записи «ВКонтакте», тогда шансы, что «умный» алгоритм вас заметит, будут выше».
ÖMANKÖ
Направление: стиль/мода
Количество подписчиков: 181 тысяча
Проект представляет собой онлайн-медиа с новостями из мира культуры, моды и дизайна. В январе сообществу исполнилось четыре года.
Впервые искусственный интеллект отметил их текстовые материалы – обзоры недель моды, переводы и статьи о значимых людях в индустрии. А позже «Прометей» выделил видеопроект с ИКЕА.
Артем Ермилов, представитель сообщества ÖMANKÖ:
«Тенденция развития онлайн-СМИ идет в сторону отказа от специализированных новостных сайтов, пользователю сейчас легче и удобнее читать новости прямо в ленте соцсетей.
Наша история началась именно «ВКонтакте», и мы уверены, что и дальше будет с ней связана. Несмотря на то, что мы ведем страницу также в Instagram и Telegram, во «ВК» уходит большая часть интересного контента. Специфика других площадок подразумевает их сокращенный вариант.
Как показывает практика, прогрессивная молодежь действительно предпочитает искать в соцсетях новые продукты и товары. Но у нас есть свое видение разных процессов и подход к подаче наших мыслей — предполагаем, что именно это цепляет людей.
Благодаря отметке «Прометея», конечно же, вырос охват публикаций – примерно втрое. Каких-то других результатов мы не ощутили. Думаю, каждый автор или паблик уникален по-своему, и у него есть своя аудитория, искусственный интеллект просто помогает ее найти».
Виктория Валикова
Направление: личная страница, врач
Количество подписчиков: четыре тысячи
Виктория Валикова на своей личной странице публикует посты в формате «живого журнала» (кстати, «ЖЖ» она тоже до сих пор ведет), рассказывает про тропические болезни, пациентов, а недавно материалы дополнились и зарисовками строительства клиники для бедных.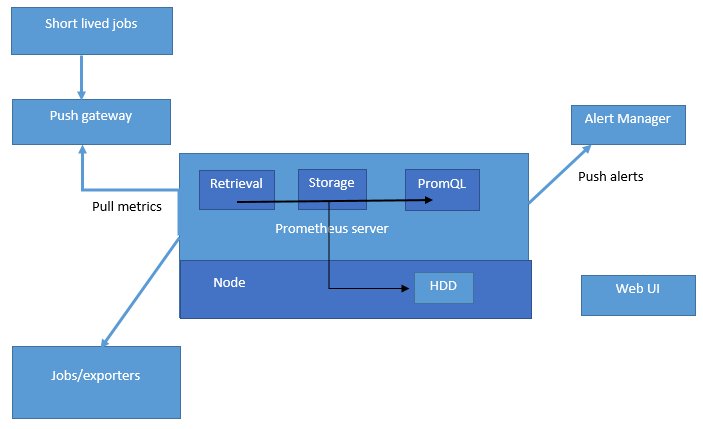
У нее много статей про Латинскую Америку, традиции, иногда публикуются случаи из путешествий. Страница несколько раз была отмечена «Прометеем».
Виктория Валикова, владелец страницы:
«Я врач, поэтому тексты у меня немного циничные, но, думаю, людям это нравится. И вообще, я пишу про людей и для людей. Параллельно стараюсь много читать, чтобы улучшать качество статей.
Я не особо придаю значение возможностям, которые приносит с собой огонек «Прометея». Я просто рассказываю о своей работе вне зависимости от того, есть ли он или нет. Но с ним аудитории прибавилось, это однозначно.
В среднем мои посты набирают около двух тысяч просмотров и от десяти до двадцати комментариев. С «Прометеем» цифра вырастает примерно в десять раз. Это здорово, потому что чем больше людей знают обо мне и о деятельности, которую я веду, тем больше помогают, в том числе материально.
Я использую все возможные социальные сети, но запрещаю себе копировать контент — стараюсь адаптировать его под аудиторию.
Для меня искусственный интеллект — дикий лес, поэтому даже предположить не могу, как это работает с «Прометеем». Я думаю, нужно делать качественный контент для людей, писать достойно, интересно и грамотно. У меня, кстати, с последним проблема, поэтому приходится все перепроверять сто раз.
Быть собой и стараться сделать максимально интересный текст — это очень нелегко, но интересно».
«Совесть»
Направление: финансовые организации
Количество подписчиков: 73 тысячи
Одно из немногих коммерческих бизнес-сообществ, отмеченных «Прометеем».
Карта рассрочки «Совесть» появилась в конце 2016 года и стала «первооткрывателем» в новой категории финансовых продуктов. Проект сразу делал ставку на продвижении в digital-каналах и соцсетях. Однако в стилистике и формате контента проект использует прямо противоположную традиционным финансовым организациям модель.
Павел Давидовский, директор по продукту и маркетингу карты рассрочки «Совесть»:
«Продвижение в социальных сетях – must have для любых компаний. Но в большом потоке контента становится все сложнее выделиться и одновременно совместить интересы подписчиков и собственные коммерческие задачи.
Контент – это царь. Чем дальше, тем выше будет его значение.
Часто бизнес-аккаунты публикуют просто стоковые фотографии с прямой рекламой товара. Мы же ищем нестандартные подходы, постоянно экспериментируем с форматами, которые «любит» умная лента «ВКонтакте», используем видео и инфографику.
Кроме того, сейчас порядка 70% подписчиков – это наши клиенты. Они уделяют внимание каждому посту, для них это значимая информация. Поэтому мы получаем больше реакций на каждый пост, чем похожие по размеру бизнес-сообщества. Люди открывают длинные тексты, рассматривают фотографии и пишут комментарии.
Главная ошибка брендов – отдать соцсети на аутсорсинг. Агентство выполнит KPI, не отступит от брендбука, использует Tone of voice, но без погружения во внутреннюю атмосферу компании шаблонный SMM приведет к шаблонным результатам».
А что говорит и как помогает «ВКонтакте»?
Дарья Рузанова, руководитель VK Talents
За год работы «Прометей» нашел и отметил десятки тысяч талантливых авторов и интересных сообществ.
Сейчас все авторы, отмеченные огнем, получают приглашение в закрытое сообщество — VK Talents.
В этом сообществе мы рассказываем об интересных и полезных мероприятиях, приглашаем участвовать авторов на фестивалях, выставках, даем ранний доступ к некоторым фичам, вместе тестируем новые возможности площадки. Помимо этого — отвечаем на вопросы, общаемся и обмениваемся опытом.
Но программа VK Talents рассчитана не только на тех, кого уже заметил алгоритм. Поддержку может получить любой интересный и талантливый автор.
Поддержку может получить любой интересный и талантливый автор.
В открытом сообществе «ВКонтакте с авторами» мы точно так же приглашаем их участвовать в интересных конкурсах, фестивалях и других мероприятиях, которые могут помочь на старте их карьеры. Там же делимся полезными статьями для создателей контента, рассказываем о том, как пользоваться старыми и новыми инструментами и отвечаем на вопросы.
Только в 2018 году музыканты, художники и другие авторы «ВКонтакте» поучаствовали в таких мероприятиях, как Faces&Laces, «Пикник Афиши», «Культурный Форум» в Санкт-Петербурге, Epizode (Вьетнам), и, конечно же, VK Fest.
В этом году нас ждет много приятных изменений и важных нововведений в работе алгоритма и программы VK Talents.
Вместо заключения
Главные инсайты о том, как получить метку «Прометея».
- Создавайте оригинальный контент. Копирование, рерайт и репосты не приветствуются – искусственный интеллект следит за тобой, как Большой Брат, а карает, как Немезида. Это относится и к фотографиям!
- Не забывайте про оформление. И здесь речь идет не только о качественных иллюстрациях и видео (загруженных обязательно во «ВКонтакте», а не ссылкой на YouTube), но и о визуальном разграничении текста – параграфы, заголовки и подзаголовки, пунктуация и орфография, само собой.
- Повышайте уровень вовлеченности. Стимулируйте вашу аудиторию делиться мнением, поднимайте спорные темы и отвечайте на комментарии. Неважно мало или много у вас подписчиков (и уж не дай Бог накручивать лайки!), только виральность, только хардкор.
- Тестируйте новые форматы и инструменты площадки. Проводите интересные трансляции от сообщества, используйте обновленные формы опросов, используйте приложение «Рассылки», не бойтесь экспериментов.
- Продавать можно и нужно, если есть, что продавать. Но весь вопрос в том, КАК это делать (открыли Америку, да?). У соцсети есть определенные правила размещения рекламных публикаций, ограничения коммерческих слов в заголовках и хештэгах, а также свод законов по проведению конкурсов и акций.
- Не стремитесь к хайпу. Никто не читает на завтрак «весь интернет», в тренде – быть собой, делиться искренними эмоциями и быть полезным в инфошуме. Наконец-то, свобода творчества.
 Это относится и к фотографиям!
Это относится и к фотографиям! У соцсети есть определенные правила размещения рекламных публикаций, ограничения коммерческих слов в заголовках и хештэгах, а также свод законов по проведению конкурсов и акций.
У соцсети есть определенные правила размещения рекламных публикаций, ограничения коммерческих слов в заголовках и хештэгах, а также свод законов по проведению конкурсов и акций.Материалы по теме:
Будущее за авторами: почему рекомендательные ньюсфиды ценят уникальный контент
Исследование: «ВКонтакте» и YouTube обошли Instagram по популярности у пользователей до 18 лет
Ошибки, которые вы допускаете при подготовке контента для сайта: как их избежать
«Некоторые вещи просто нельзя забыть»: почему работа контент-модераторов это ад
Как вести коммерческий инстаграм: работа с контентом
Фото на обложке: архив автора
Что дает блогеру отметка «Прометея» во ВКонтакте
С конца прошлого года у пользователей ВКонтакте начал появляться значок огня на личной странице или в сообществе. В соцсети заработал новый алгоритм поиска талантов «Прометей». Мы опросили блогеров, которые успели оценить на себе действие алгоритма, и выяснили, чем он полезен авторам.
В соцсети заработал новый алгоритм поиска талантов «Прометей». Мы опросили блогеров, которые успели оценить на себе действие алгоритма, и выяснили, чем он полезен авторам.
Что такое «Прометей»
«Прометей» — механика поиска талантов, которая появилась во ВКонтакте в сентябре 2017 года. Искусственный интеллект находит создателей интересного контента. Выделяет их на 7 дней значком огня, который появляется рядом с именем или названием сообщества. Алгоритм помогает получить больше внимания и новых подписчиков. По данным на начало февраля, «Прометей» отметил значком более 4000 авторов.
Как «Прометей» привлекает внимание к авторам? Страницы, которые выбрал искусственный интеллект, получают повышенный охват в разделе «Рекомендации». Раздел посещает каждый третий пользователь соцсети. Авторы с «огоньком» оказываются в центре внимания и получают новых подписчиков.
Кого выбирает «Прометей»? Чтобы алгоритм заметил автора, ему необязательно иметь популярную страницу. Среди отмеченных знаком огня есть сообщества с сотней подписчиков и многотысячные гиганты. Считается, что «Прометей» выделяет творческие сообщества: писателей, иллюстраторов, фотографов. На самом деле, если пользователь делает увлекательный контент, скажем, о жизни в коммуналке, то алгоритм тоже поможет ему найти больше подписчиков.
Среди отмеченных знаком огня есть сообщества с сотней подписчиков и многотысячные гиганты. Считается, что «Прометей» выделяет творческие сообщества: писателей, иллюстраторов, фотографов. На самом деле, если пользователь делает увлекательный контент, скажем, о жизни в коммуналке, то алгоритм тоже поможет ему найти больше подписчиков.
Как получить огонь «Прометея»? Социальная сеть поддерживает активных пользователей, которые делают интересный авторский контент. Пишите, снимайте видео, рисуйте или фотографируйте что вам нравится. Будьте собой, но не забывайте об оформлении страницы – оно должно соответствовать правилам сайта. И немного терпения – талантов много, а алгоритм один.
Какой эффект дает «огонек»
Многие авторы, чьи страницы отмечает «Прометей», замечают эффект от действия алгоритма почти сразу. Помимо визуального символа в личные сообщения приходит пояснение от «Прометея» и резко возрастает охват аудитории у постов.
Богдан Дьяконов, создатель и администратор группы «Развитие жизни на Земле (The Evolution Of Life)», 18 тыс. Когда я в первый раз получил огонек, количество людей в группе было примерно 1600. После этого я еще два раза получал огонек, второй раз почти сразу. И в итоге уже почти 17 000 — увеличение больше чем в десять раз. Появилось много заинтересованных людей, стали задавать вопросы. А я просто продвигаю то, что мне самому нравится. Благодаря «Прометею» мои труды хоть как-то вознаграждены. | |
Никита Савянин, администратор сообщества Canceled, 6 тыс. подписчиков, группа не обновляется с 22 января
| |
Артем Ремизов, киноблогер, 1,3 тыс.
В комментарии начали приходить люди, которые даже не подписаны на меня. Иногда писали по делу, иногда нет. Естественно, что среди них были те, кого можно назвать моей целевой аудиторией. Они до сих пор проявляют активность на моей странице. В результате увеличил количество подписчиков и комментариев под постами. | |
Алексей Бесфамильный, автор сообщества «Дома», 52 тыс. подписчиков
| |
Влада Аксенова, автор паблика «Нормальная», 940 подписчиков
| |
Олег Курочкин, автор паблика «Понимай_Кино», 5 тыс. подписчиков
| |
Дарья, создатель группы «Живописность русских коммуналок», 45 тыс. подписчиков
|
 подписчиков
подписчиков
 Только теперь зрителей стало больше, это круто. Результаты можно посмотреть в статистике:
Только теперь зрителей стало больше, это круто. Результаты можно посмотреть в статистике:Как использовать отметку «Прометея»
С увеличением охвата важно не прекращать обновления и продолжать радовать читателей интересными постами — так, как вы умеете это делать.
Артем Ремизов
| |
Алексей Бесфамильный
| |
Влада Аксенова
| |
Олег Курочкин
| |
Дарья
|
 Да, от славы я не откажусь, конечно, но как-то подстраивать свой контент под «Прометея» я не стал.
Да, от славы я не откажусь, конечно, но как-то подстраивать свой контент под «Прометея» я не стал. Чтобы усилить эффект — не просто увеличить охват, но и показать максимальному числу потенциальных подписчиков то, какие именно материалы размещаются в нашем паблике.
Чтобы усилить эффект — не просто увеличить охват, но и показать максимальному числу потенциальных подписчиков то, какие именно материалы размещаются в нашем паблике.В чем польза для блогера
Опрошенные Hello Blogger авторы и создатели сообществ отмечают, что «Прометей» позволил ВКонтакте предложить аудитории «свежую кровь» — новых, молодых авторов, которых люди не знают. Раньше эти люди не могли достучаться до читателей из-за главенства в ленте постов крупнейших пабликов.
Богдан Дьяконов
| |
Алексей Бесфамильный
| |
Артем Ремизов
| |
Влада Аксенова
| |
Олег Курочкин
| |
Дарья
|


Изображение на обложке из статьи ВК
Прокачайте страницу в ВК
Автор: Ольга ДуброПоделиться
Поделиться
Твитнуть
Плюсануть
Запинить
Класснуть
Отправить
Вотсапнуть
Вам может понравиться
[email protected]
+7 (812) 409-38-28
ул. Большая Посадская, 1/10
Санкт-Петербург
Алгоритм Прометей Вконтакте | CODEARMY
Алгоритм представлен в 2017 году, он разработан для поиска и поддержки интересных авторов. Согласно официальным разъяснениям социальной сети, система постоянно находит создателей уникального контента и следит за их достижениями. Талантливые пользователи и интересные сообщества получают специальную метку в виде пламени и повышенные охваты. В мобильных приложениях сервис «Рекомендации» показывает записи такого автора людям, еще не знакомым с его творчеством, но которых оно может заинтересовать.
Согласно официальным разъяснениям социальной сети, система постоянно находит создателей уникального контента и следит за их достижениями. Талантливые пользователи и интересные сообщества получают специальную метку в виде пламени и повышенные охваты. В мобильных приложениях сервис «Рекомендации» показывает записи такого автора людям, еще не знакомым с его творчеством, но которых оно может заинтересовать.
Иконка огонька выдается сообществу на семь дней, столько же длится поддержка охватами. Получить метку можно неограниченное количество раз для каждого сообщества.
В социальной сети действует защита первоисточника. Прометей распознаёт оригинальный контент и выводит в разделе «Рекомендации» именно первоисточник. Для того чтобы алгоритм определил Ваш контент как уникальный, он должен быть загружен напрямую во Вконтакте. Если Вы впервые выложили материалы в другой социальной сети или на стороннем сайте и кто-то другой успел загрузить его в ВК первым, Прометей не сможет определить Вас как автора. Служба поддержки советует авторам сначала загружать материалы в ВК, а уже потом распространять их по сети.
Служба поддержки советует авторам сначала загружать материалы в ВК, а уже потом распространять их по сети.
Что это значит для авторов? И как получить огонь Прометея? Мы собрали для вас рекомендации самой социальной сети и наблюдения администраторов сообществ.
Первое
Сократите до минимума количество репостов. Прометей оценивает только оригинальные записи. Поэтому если Ваша страница по большей части публикует репосты из других сообществ и профилей, она вряд ли попадёт в поле зрения алгоритма, а также получит меньший охват в умной ленте.
Второе
Внимательно следите за предложенным для публикации контентом. Если эти материалы интересные и уникальные — это не помешает получению Прометея. Если же среди предложенных к публикации постов большинство контента уже было размещено в социальной сети или является не представляющим ценности копипастом из внешних источников, Прометея получить вряд ли удастся.
Третье
Добавляйте к фотопостам авторское описание с уникальной и интересной информацией об опубликованном фото или группе фотографий.
Четвёртое
Минимизируйте количество ссылок на внешние сайты в постах. Если вам необходимо собрать несколько ссылок в одном посте или сделать подборку материалов из внешних источников, Вконтакте рекомендует оформлять их при помощи редактора статей.
Пятое
Видео, загруженное в ВК не напрямую, а через загрузку с другого сайта не будет распознано как уникальное и отмечено Прометеем.
Шестое
Регулярность. Прометей отмечает сообщества и страницы, которые часто публикуют интересные записи. Вконтакте не даёт точного ответа на вопрос что такое регулярность, указывая лишь оптимальное количество — до 5 постов в день, а так же отмечая, что алгоритм может найти сообщества, которые публикуют записи несколько раз в неделю.
Седьмое
Оформление контента играет важную роль. Разбивайте текст на абзацы, в статьях используйте большие фотографии не менее 700 пикселей в ширину, загружайте видео в разрешении не менее 720 пикселей, заполняйте все контактные данные сообщества.
Восьмое
Избегайте контента для взрослых, обнажённых тел. Если вы поставили возрастное ограничение у группы самостоятельно — снимите его.
Девятое
Реакция аудитории. Это один из важнейших показателей интереса к контенту. Останавливаются ли на ваших постах читатели или просто пролистывают в ленте? Открывают ли лонгриды, смотрят ли видео? Если да, то как долго? Дочитывают ли они материал до конца или закрывают его бегло пролистав? Отмечают ли читатели ваш труд лайками и комментариями?
И, рекомендация напоследок: развивайте сообщество комплексно, если у вас есть внешние источники трафика, например e-mail рассылка или блог поставьте в них ссылки на сообщество, побуждайте людей смотреть и взаимодействовать с контентом в группе. Не занимайтесь рерайтом, подключите приложения для удобства посетителей сообщества, используйте тематические хэштеги для постов, но не злоупотребляйте ими.
Посмотреть список сообществ получивших отметку можно в приложении «Пантеон авторов».
Эта статья доступна в видеоформате:
5 принципов получения огня «Прометея» на отдельную запись во ВКонтакте
Неделю назад команда ВКонтакте провела закрытую встречу с авторами, отмеченными огнем «Прометея». Эта отметка дает пабликам дополнительные охваты аудитории за счет продвижения записей через раздел «Рекомендации». На мероприятии разработчики рассказали о нововведениях, которые соцсеть запустит для привлечения талантов. Первое заработало в минувшую пятницу — «Прометей» стал отмечать не только сообщества, но и отдельные интересные записи. Hello Blogger рассказывает, как устроена новая функция.
- Чтобы получить отметку «Прометея», запись должна быть интересной, уникальной и соответствовать тематике страницы. Понятие интереса субъективно, поэтому разработчики рекомендуют авторам ориентироваться на свои вкусы — писать о том, что интересно самому. Уникальный — не скопированный ниоткуда. Соответствие тематике тоже надо понимать буквально: если паблик о рецептах, то «огонек» может получить запись с рецептом, а запись с обзором смартфона — не может.
- Получению «огня» поможет трафик из внешних источников, репосты в соцсети и регулярность публикаций в паблике. Ставьте ссылки на новые записи в ВК на других платформах. Пишите то, что читателя захотят сохранить в свою ленту, сделав репост. Делайте публикации постоянно, хотя бы два-три раза в неделю.
- Алгоритм выдает отметку на сутки. «Прометей» для пабликов дает повышенное охваты на семь дней, а отдельный пост будет продвигаться только 24 часа.
- «Прометей» автоматически снимет отметку, если публикацию отредактировали. Менять содержание поста после получения «Прометея» нельзя, иначе продвижение прекратиться. Это сделано, чтобы не допустить в «Рекомендациях» рекламу, кликбейт и спам.
- Если продолжать в том же духе, алгоритм подарит «огонек» всему паблику. Выпускайте новые записи, которые будут «лайкать», репостить и комментировать — получите «Прометей» на семь дней, для всех новых записей.
 Уникальный — не скопированный ниоткуда. Соответствие тематике тоже надо понимать буквально: если паблик о рецептах, то «огонек» может получить запись с рецептом, а запись с обзором смартфона — не может.
Уникальный — не скопированный ниоткуда. Соответствие тематике тоже надо понимать буквально: если паблик о рецептах, то «огонек» может получить запись с рецептом, а запись с обзором смартфона — не может.Изображение на обложке из поста разработчиков ВКонтакте
Автор: Илья Новиковновая статистика и платформа для связи с рекламодателями. Читайте на Cossa.ru
8 июня 2018 года ВКонтакте провела VK Talents Event — закрытую встречу с авторами, отмеченных огнём Прометея. На мероприятии соцсеть анонсировала новинки для создателей контента.
VK Talents
Осенью этого года ВКонтакте планирует запустить VK Talents — программу поддержки талантливых авторов в области музыки, дизайна, живописи, поэзии, прозы, науки, моды и других направлениях. В рамках проекта соцсеть предоставит его участникам приоритетный доступ к новым инструментам ВКонтакте, ежемесячные гранты на продвижение сообществ, интеграцию в крупнейшие музыкальные фестивали и другие городские события._cap2769.jpg)
Новая статистика
Обновлённый раздел статистики наглядно покажет авторам, как улучшить наполнение страницы или сообщества. В первую очередь ВКонтакте продемонстрирует уникальность, виральность и качество контента, а также вовлечённость и лояльность аудитории.
На первом этапе, который стартует в ближайшие дни, новая статистика будет доступна только авторам и сообществам, которые получали огонь Прометея.
Публикации с огнём
В скором времени алгоритм Прометей начнёт выделять огнём отдельные записи. Они получат продвижение в разделе рекомендаций и будут чаще показываться пользователям в течение суток. Среди факторов, которые влияют на получение огня: уникальность, интересность, оригинальность, устоявшаяся тематика, рост трафика с других площадок, регулярность постинга и количество репостов записи.
Платформа для связи рекламодателей с «огненными» авторами
ВКонтакте будет связывать начинающих создателей контента с крупными компаниями и рекламными агентствами. Специальные инструменты позволят рекламодателям найти релевантных авторов, разослать им задания и проработать с ними конкретные креативы. Дополнительно продвинуть такой контент до нужных аудиторных показателей можно будет с помощью таргетированных промопостов. Таким образом, начинающие авторы получат возможность монетизировать творчество и начать сотрудничать с известными брендами, а компании смогут ещё эффективнее продвигать товары и услуги.
Специальные инструменты позволят рекламодателям найти релевантных авторов, разослать им задания и проработать с ними конкретные креативы. Дополнительно продвинуть такой контент до нужных аудиторных показателей можно будет с помощью таргетированных промопостов. Таким образом, начинающие авторы получат возможность монетизировать творчество и начать сотрудничать с известными брендами, а компании смогут ещё эффективнее продвигать товары и услуги.
Выключение комментариев к отдельным записям
Кроме того, ВКонтакте разрешила отключать комментарии к отдельным записям сообщества или личной страницы пользователя. Новая функция доступна как в вебе, так и на мобильных приложениях.
Пользователь также может выключить комментарии у любого ранее опубликованного поста, если по какой-то причине он больше не хочет развивать обсуждение.
Ранее ВКонтакте представила масштабное обновление системы медиапродуктов на VK Media Day 2018. На мероприятии соцсеть анонсировала запуск платформы подкастов и алгоритма защиты уникального контента Немезида, обновление раздела «Рекомендации» и другие новинки.
На мероприятии соцсеть анонсировала запуск платформы подкастов и алгоритма защиты уникального контента Немезида, обновление раздела «Рекомендации» и другие новинки.
Хотите подсказать новость или поделиться экспертным мнением? Пишите: [email protected]
Инновационные цифровые решения для фарммаркетинга:
- Как сегментировать пациентов и что делать дальше;
- Как повысить лояльность пациентов, проходящих терапию;
- Как отстроиться от конкурентов с помощью диджитал-инструментов;
- Как запустить интерактивное обучение медработников;
- Как увеличить количество заявок на диагностику;
- Как повысить осведомлённость пользователей о заболевании.
Узнать в спецпроекте Cossa & Twice →
Реклама
Поделиться
Поделиться
уникальная информация от команды ВК Вконтакте как отключить огонь прометея
Быстрая навигация:
Алгоритм «Прометей» поможет популяризовать интересных пользователей и их групп в ВК
Система разработана специально для поощрения хороших и интересных авторов, их контент теперь будет помечаться красненькой иконкой огонька на неделю. Если на следующей неделе контент будет удовлетворять требования «Прометея», огонёк останется и алгоритм будет показывать интересное сообщество или автора, другим пользователям, на основе их предпочтений в ленте новостей.
Если на следующей неделе контент будет удовлетворять требования «Прометея», огонёк останется и алгоритм будет показывать интересное сообщество или автора, другим пользователям, на основе их предпочтений в ленте новостей.
Такой подход разработчиков, направлен на стимулирование авторов, делать интересный контент.
Огонёк Вконтакте увеличит заработок
Метка огонька даёт значительный прирост посещаемости сообщества или странички, следовательно и рост дохода обеспечен. Выигрывают все, автор получает желаемую аудиторию подписчиков. Сам Вконтакте процент от рекламы и что самое важное, пользователи будут обеспечены качественным контентом.
Переработанная функция «Сначала интересные».
По сути «огонёк вконтакте», это следующий шаг эволюции после функции « «, к всё более совершенному подбору персонифицированному информации для нас с вами. Ведь если смотреть ленту без какого либо отбора, получится простая доска объявлений с примесью различного бреда. Почему то у меня сразу же вспоминается Твиттер.
Я еще не писала об алгоритме «Прометей», хотя каждый уважающий себя автор, связанный с тематикой SMM, уже тысячу раз рассказал о секретах получения заветного огонька – даже не имея опыта его получения!
«Прометей» – это алгоритм, созданный для поиска и поддержки интересных авторов и сообществ. Искусственный интеллект постоянно находит создателей уникального контента и следит за их достижениями.
Зачем каждому SMM-специалисту нужно стремиться получить эту метку?
Метка выдается всего на семь дней, в это время ваши посты получают тысячный охват среди пользователей ВК совершенно бесплатно.
Сообщество попадет в список приложения «Пантеон авторов».
Так за одну неделю вы можете увеличить охват сообщества в десятки тысяч раз абсолютно бесплатно!
Метка выдается всего на неделю, получить «огонек» можно неограниченное количество раз.
Почему же до сих пор я воздерживалась от рассказов об этом алгоритме?
Думаю, прежде чем говорить о методах его работы и способах получения «огня», сначала нужно стать обладателем этой метки.
Что могу посоветовать тому, кто стремится получить огонек?
Получить заветную метку не составит труда. Притом совершенно неважно, сколько в вашем сообществе человек: 10 или 5000. Главное – это уникальность контента. «Прометей» в первую очередь поощряет авторов, которые создают творческие некоммерческие проекты. И это довольно честно – я говорю как человек, который долгое время увлекался фотографией. Зарабатывать на творчестве довольно трудно, поэтому вкладывать в продвижение затратно и неудобно. Как говорится, «художник должен быть голодным». ВКонтакте с авторами делают хорошее дело, помогая пробиться начинающим талантам.
Творите на постоянной основе, старайтесь выкладывать посты каждый день, и получение заветной метки не заставит себя долго ждать.
Вторая категория, которой тоже очень легко получить огонёк от «Прометея» – это путешественники.
Travel-блогинг с каждым днем набирает обороты и приобретает все большую популярность среди людей. Если вы часто путешествуете и постоянно ведете свой блог, выкладываете интересные заметки о культуре и жизни разных стран, снимаете видеоотчеты и красивые фотокарточки, то вам не составит труда получить метку.
Создавайте уникальный контент – это принцип, от которого не отойти. Забудьте о рерайтинге, ищите себе SMMщиков, которые умеют писать (что самое главное) и способны разобраться в вашей теме (т.е. если ваша компания продает психологические тренинги, сммщик обязан разбираться в психологии).
Помимо уникальных текстов вам понадобятся и уникальные картинки высокого качества: фотографии, иллюстрации. Наймите фотографа или найдите себе иллюстратора, который сможет обеспечить вас уникальными изображениями по ТЗ.
Мы рисуем комиксы и иллюстрации к каждому посту
Создавайте контент, который будет вовлекать пользователей в дискуссии. Это могут быть неоднозначные посты на спорные тематики. Главное не переборщите, в интернете очень легко наткнуться на негативных троллей:) Умейте вежливо отстаивать свою точку зрения в комментариях. Боритесь с негативом, ни в коем случаи не игнорируйте его.
Как, например,
Прометей ВКонтакте доступен для отдельных авторов и целых сообществ. Но получить его может только та страница, на которой уже отмечается высокая активность. Как её создать, если речь идёт о совсем новом начинании или статистика пока не так хороша, как хотелось бы? Конечно же, поможет накрутка лайков, комментариев, репостов ВК!
Прометей ВК — альтернативный способ раскрутки сообщества от администрации соц.сети. Самое интересное в том, что бесплатную аудиторию ВК не получить, не используя для «оживления» сообщества или страницы .
На просторах Всемирной паутины существует множество советов о том, как получить столь желанный многими юзерами огонь Прометея вконтакте. «Прометей» придуман для поиска и раскрутки активных сообществ и талантливых личностей. Это алгоритм, который позволяет отыскивать уникальные аккаунты и отслеживать их развитие.
Зачем необходима эта метка?
- Заветный огонёк присваивается пользователю на 7 дней. Это беспрецедентная возможность получить огромный охват юзеров социальной сети вк. Это тот случай, когда обычный пост может войти в число самых популярных публикаций. И все это абсолютно бесплатно;
- Юзеры, использующие мобильное приложение ВКонтакте, будут ознакомлены с данным сообществом в разделе «Рекомендации»;
- Сообщество попадет в заветный список приложения «Пантеон авторов».
После получения огня Прометея вы сможете увеличить охват сообщества во множество раз, не заплатив за это ни копейки. Пользоваться огнем можно в течение недели, но неограниченное количество раз. И вот здесь возникает логичный вопрос: «Как получить метку?».
Кто чаще получает «Прометея» ВКонтакте?
- Творческие личности
Если вы занимаетесь популярным или необычным творчеством, у вас есть все шансы получить огонь ВКонтакте. Владельцу сообщества даже не нужно переживать о количестве подписчиков. То есть, паблик может быть абсолютно не раскрученным. Самый важный момент заключается в уникальности размещенного контента. Вам есть что показать людям? Алгоритм не пройдет стороной. Искусственный интеллект поощряет различные некоммерческие идеи.
Прометей – это настоящая палочка-выручалочка для тех, кто не представляет своей жизни без любимого творчества, но не имеет возможности заниматься пиаром. Даже если такое занятие приносит дополнительный заработок, его не всегда целесообразно тратить на продвижение. Социальная сеть ВКонтакте идет навстречу творческим личностям. ВК помогает пробиться молодым и неизвестным талантам абсолютно бесплатно.
Чтобы увеличить шансы на получение огня, необходимо регулярно обновлять контент. И, конечно же, вкладывать душу в то, чем вы занимаетесь.
- Путешественники
Нельзя обойти стороной столь популярную деятельность, как Travel-блогинг. Заядлому путешественнику не составит труда получить огонёк. Если вы любите это дело и умеете красиво преподносить людям «плоды» своих усилий, «Прометей» практически у вас в кармане. Качество контента должно быть на уровне. Фотографии – только лучшие. Видео – с интересным монтажом. Записи – содержательные и познавательные.
- Коммерческие проекты
Чтобы заинтересовать избирательный алгоритм, придется приложить немало усилий. Но это вполне возможно! Вы имеете право попробовать, поскольку являетесь кормильцем социальной сети. ВК существует за счет рекламодателей, готовых платить за те или иные услуги. Но почему бы не претендовать на бесплатную рекламу?
SMM – это сложная и многоэтапная деятельность. Ведение сообщества перестало быть копеечной забавой, ограничивающейся постингом милых картинок. Сейчас все значительно сложнее. Это кропотливый труд, порой неблагодарный. Но если заниматься этим с умом, результаты не заставят себя долго ждать.
Евгения Крюкова
Мы задали представителям команды «ВКонтакте» животрепещущие вопросы о «Прометее», умной ленте и их планах на будущее. Отвечают Сергей Паранько, директор по медийной экосистеме, и Андрей Законов , директор по росту и исследованиям социальной сети. Спешите ознакомиться с уникальной информацией из первоисточника.
1. Как ваши алгоритмы понимают, что пост интересен конкретному пользователю? Можете перечислить факторы, которые больше всего влияют на охват записи? Качество контента, отклик аудитории – это понятно. А что-нибудь из менее очевидного?
Мы анализируем активность пользователя в ленте и поднимаем выше те посты, с которыми он с большей вероятностью станет взаимодействовать: поставит «Нравится», напишет комментарий, «залипнет», откроет фотографию, прочтет статью, посмотрит видеоролик. Эти действия очень разные, мы предсказываем их по отдельности. Далее все это учитывается общим алгоритмом, который на основе всех факторов и осуществляет ранжирование.
2. На вашем выступлении на « МЕН2 » вы говорили, что на охват поста влияют даже такие мелочи, как погода и настроение пользователя. Как лента это понимает?
За любой записью стоит огромное количество признаков ранжирования. Каждый компонент — это определенная величина, которая описывает сам пост, его автора, время суток на момент просмотра рекомендаций, скорость интернет-соединения читателя и множество других критериев.
Если пользователь зашел в ленту новостей или раздел рекомендаций, находясь в глухом лесу и с плохим интернет-соединением, мы не станем показывать ему громоздкое видео в начале ленты. А еще алгоритм учитывает день недели и время суток. Так в утренней ленте рекомендаций будет больше новостей и информационного контента, а вечером — медийного и развлекательного.
3. У вас есть документ, в котором перечислены все факторы, которые учитывает алгоритм? Или он уже настолько обучился, что даже вы не знаете, по каким параметрам он дает охват той или иной записи?
Мы знаем список факторов, но все уникально для каждой пары «пользователь-запись». Поэтому, просто посмотрев на пост, невозможно сказать, насколько он хорош, это же субъективно. Мне пост про локальные новости Москвы в Петербурге абсолютно нерелевантен, а вам может быть не интересна моя лента новостей про машинное обучение и социальные сети.
4. Можно ли искусственно увеличить охват записи, закупая лайки и шеры на сервисах накрутки?
Не стоит. В долгосрочной перспективе это точно приведет к снижению охвата. Кроме того, что лайки и шейры не играют центральную роль в ранжировании поста, такие накрутки с высокой вероятностью будут обнаружены нами.
Впрочем, трафик на пост из референсов других социальных сетей правда может улучшить органический охват записи и за это не бывает пенальти.
5. Есть ли оптимальная длина текста для максимального охвата в умной ленте? Например, в анонсе к статье – не более 500 символов. А в лонгриде, созданном в редакторе, не более 10 000?
Оптимальной длины в отрыве от фокуса внимания читателя нет. Все основывается на вовлечении, если у вас информационное послание, старайтесь писать емко, в инфостиле. Если пытаетесь вовлечь человека кликнуть на сниппет — тот же принцип, емко и вовлекающие. Только не сваливайтесь в кликбейт, это отрицательно отразится на охватах.
Если вы рассказываете историю, увлекайте человека. Все крупные формы, условно более 1 000 знаков лучше верстать в редакторе статей, разбивая текст мультимедиа-вставками.
6. Умная лента дает предпочтение качественным видео (по сравнению с некачественными). А что такое «качественное видео» для «ВКонтакте»? Какими характеристиками оно обладает?
Видеозаписи 720–1080 р.
7. Пытается ли ВК выявлять fake news? Важна ли правдивость и достоверность данных, или только интерес аудитории к записи?
«ВКонтакте» нет премодерации контента — как и на других площадках, пользователи могут свободно публиковать и обсуждать интересующие их темы. При этом любой человек может сообщить о неправомерном, оскорбительном или недостоверном по его мнению контенте с помощью кнопки «Пожаловаться». Мы рассматриваем все жалобы без исключений. У «ВКонтакте» одна из самых больших служб модерации и мы реагируем максимально оперативно.
8. Как вы относитесь к конкурсам на самых активных подписчиков и к конкурсам за подписку + репост? Правилами ВК они разрешены, но влияет ли это как-то на охват записей (позитивно или негативно)? Вы рекомендуете использовать конкурсы для продвижения в ВК?
Это легальный способ продвижения, но нужно держать в уме, что таким образом вы привлекаете себе в подписчики нерелевантную аудиторию. Это может иметь негативный побочный эффект — подписчики, которые не вовлекаются в основной контент вашей группы, могут плохо влиять на охваты и виральность ваших постов.
9. Статьи, созданные в редакторе, получают больше охват, чем статьи, ведущие на сторонний сайт. Что делать коммерческим сайтам и блогам в таких условиях? Как им привлекать пользователей «ВКонтакте» на свою площадку?
Группа бизнеса в любой социальной сети — это в первую очередь сообщество. Если вы относитесь к ней именно как к медиаактиву, вы преуспеете. Принудительный вывод пользователя на другую площадку, без предоставления альтернативы, в коммуникации может огорчить человека. Как говорят: ты хочешь продать мне свой товар, но ты делаешь это без уважения.
На площадке ВК можно общаться с клиентами/читателями, продавать товары, получать денежные переводы и многое другое. Мы развиваем нашу экосистему и делаем максимально удобной для пользователей. И в этом плане бизнесу также выгодно развивать свою площадку внутри ВК. Редактор статей — еще один инструмент для коммуникации и выстраивания сообщества.
10. Будут ли теперь вики-статьи получать меньший охват, чем статьи, сделанные в редакторе?
Решает не формат, а взаимодействие пользователя с вашим контентом. Интересно рассказанная история с большим количеством взаимодействий от читателей получит охваты вне зависимости от формата подачи. Другое дело, держать внимание аудитории удобнее как раз инструментами, доступными в редакторе статей.
Конкретно о вики-страницах, они не попадают в раздел «Рекомендации» на мобильных устройствах, это в принципе десктоп-инструмент, так что да, охват у них ниже, чем у других форматов подачи.
11. Некоторые пользователи жалуются, что не видят интересные и нужные им посты. Из-за чего это происходит? И нет ли у вас мыслей о том, чтобы пойти по пути «Фейсбука» – сделать так, чтобы в ленте пользователей было больше личного контента, а не коммерческого?
Мы постоянно экспериментируем с разными моделями ранжирования, и главное метрикой является вовлечение пользователей. Всегда можно послать явные сигналы нейронке, скрыв пару постов от неугодных пабликов.
12. Вы говорите, что нельзя закупать ботов вообще. А как тогда набрать первую аудиторию сообществу? Если подписать родственников и друзей, получится, что аудитория все равно нецелевая. А если закупать рекламу, никто не будет подписываться в пустое сообщество. Как найти выход?
Люди приходят к вам за контентом. Потому ваше сообщество не будет пустым, если вы рассказываете там интересные целевой аудитории вещи. Реклама для ЦА идеальный вариант для старта. Так вы получите себе ядро аудитории, которая поможет вам расти органично.
13. Как понять, что на сообщество наложили пенальти? Как его снять?
Смотреть в статистику, это можно заметить по снизившимся охватам. Проанализировать, что вы делали в последние дни, что может быть расценено платформой как нежелательные действия: кликбейт, агрессивный вывод аудитории, неоригинальный контент, слишком частый постинг. Перестать это делать. И само пройдет через два дня:-)
14. Есть ли фильтры исходя из тематики? (Например, понижается «взрослый контент»). Если да, какие тематики имеют понижающие коэффициенты.
Все, что не запрещено законодательством РФ и правилами площадки, — можно. Все, что запрещено, — нельзя.
15. Случай из нашей практики. Мы ежедневно публикуем в блоге уникальные статьи, и их сразу же парсят несколько пабликов «ВКонтакте». Получается, что они анонсируют этот контент первыми, а мы – спустя 5–10 минут. Влияет ли это негативно на охват наших записей?
16. То есть первоисточником считается тот, кто первый расшарит ссылку? Если это так, мы не можем конкурировать с автопарсерами, так как у них это происходит автоматически, а у нас вручную, мы пишем уникальный анонс. Что нам делать в таком случае?
Не расшарил ссылку, а нативно загрузил контент. Эмбеды и ссылки в принципе никак не делают вас первоисточником контента. Что там находится на чужом видеохостинге или сайте, мы не знаем, и этот контент не парсим и не анализируем. Поэтому и важно загружать свои материалы в нативные средства подачи платформы.
17. Как будут индексироваться поисковиками статьи, созданные с помощью редактора? Вики-статьи хорошо попадали в поиск, а что будет теперь?
Статьи отлично индексируются «Яндексом» с самого старта, и «Гуглом» уже тоже.
18. Паблик LIVE ведет сотрудник «ВКонтакте»? Можно ли на него ссылаться, как на официальный источник информации?
На свой страх и риск. Это неофициальное сообщество.
Как работает алгоритм «Прометей»
19. В работе «Прометея» участвуют живые люди? Или решение полностью отдано алгоритму? Как он обучается? Можете рассказать простыми словами?
Алгоритм автоматизирован и самостоятельно ищет новых авторов. Нейронка иногда допускает ошибки. Каждую такую ошибку мы отмечаем, посылая сети сигнал о неверном выборе. На основе этой обратной связи «Прометей» и обучается.
20. Мы уже давно постим качественный контент, который вызывает отклик у нашей аудитории, но так и не получили огонь «Прометея». Как нам повлиять на это? Можете дать конкретные рекомендации? Хочется именно конкретики, а не расплывчатых советов типа «постите тот контент, который нравится вашей аудитории».
В первую очередь алгоритм «Прометей» реагирует на оригинальные материалы поданные в нативных инструментах «ВКонтакте». Нативные форматы подачи контента крайне важны, потому что позволяют алгоритму оценить уникальность контента и его тематику. Первое важно для того, чтобы получить метку, второе — чтобы обеспечить автору отмеченному «огнем» хороший буст охватов. Записи таких авторов попадают в раздел «Рекомендации».
Практически все записи
«Прометей» — это алгоритм искусственного интеллекта социальной сети Вконтакте, который помогает продвинуться создателям уникального и интересного контента.
Делает он это за счет повышения охвата публикаций в разделе «Рекомендации» и отмечая ваше сообщество специальным значком.
Вы также получите полезные советы для дальнейшего развития группы.
Как работает «Прометей»?
«Прометей» выдается на 7 дней, но получать его можно неограниченное количество раз. Если ваше сообщество хотя бы однажды его получило, то его можно будет найти в «Пантеоне авторов» на странице «Вконтакте с авторами».
Одним из главных преимуществ алгоритма является то, что он очень внимательно учитывает действия пользователей. Например, если вы увидели интересный пост в рекомендациях, затем подписались на сообщество, но в дальнейшем перестали следить за его новостями, то это ударит по его популярности.
Прометей также может продвигать вас не по совсем очевидной аудитории и будет следить за тем, как она отреагирует на нетипичный для нее пост. Согласитесь, не всегда имеет смысл показывать в рекомендациях новости только одной отрасли определенному пользователю. Но по большей части алгоритм осуществляет показы по аудитории, интересующейся похожими сообществами.
Таким образом, он абсолютно бесплатно заменяет таргетированную рекламу и рекламу в сообществах.
Как получить метку «Прометея»?
1. Оригинальный контент
Большая часть публикаций должна содержать уникальные текст, изображения и видео, которых нет на других сайтах. Рерайтинг и репосты здесь не приветствуются, изображения должны быть хорошего качества, а видео загружены непосредственно во Вконтакте (а не через ссылку, например с YouTube).
В этом даже есть определенный плюс — видео в ВК автоматически воспроизводится при пролистывании, в отличие от загруженного с YouTube.
Также не ограничивайтесь только фото и видео, создавайте персональные музыкальные подборки и gif-изображения.
Что касается контента со сторонних сайтов, то им тоже можно делиться, но не перебарщивать и желательно добавлять свое мнение.
Внимание! Речь идет не о количестве подписчиков, ведь «Прометей» как раз-таки поощряет еще “не раскрутившихся” авторов. У вас должны быть реальные и не накрученные лайки, репосты и комментарии.
Даже если у вас мало подписчиков, но они очень активны — это большой плюс. Вконтакте уже научился распознавать ботов, поэтому нужно хорошо поднапрячься. Задавайте вопросы, просите совета, поднимайте спорные темы и отвечайте на комментарии.
Прометей оценит виральность вашего контента, т.е. как часто люди им делятся со своими друзьями и сами возвращаются к записи.
3. Удобное оформление
Не забывайте про читабельность ваших постов. Делите текст на абзацы, соблюдайте пунктуацию и проверяйте орфографию.
Помимо этого, нужно соблюдать правила самой социальной сети ВКонтакте. Ознакомьтесь с правилами размещения рекламных публикаций и правилами проведения конкурсов и акций.
Гистограмм и сводки | Прометей
Гистограммы и сводки относятся к более сложным типам показателей. Не только одна гистограмма или сводка создают множество временных рядов, это Также труднее правильно использовать эти типы метрик. Эта секция поможет вам выбрать и настроить соответствующий тип метрики для вашего вариант использования.
Поддержка библиотеки
Прежде всего, проверьте поддержку библиотеки для гистограммы и резюме.
Некоторые библиотеки поддерживают только один из двух типов или поддерживают сводки. только ограниченно (без расчета квантилей).
Подсчет и сумма наблюдений
Гистограммы и сводки обоих выборочных наблюдений, обычно запрашиваются
продолжительность или размер ответа. Они отслеживают количество наблюдений и сумма наблюдаемых значений, позволяющая вычислить среднее значение наблюдаемых значений. Обратите внимание, что количество наблюдений
(отображается в Prometheus как временной ряд с суффиксом _count )
по своей сути счетчик (как описано выше, он только растет).Сумма
наблюдения (отображаются как временной ряд с суффиксом _sum )
тоже ведет себя как счетчик, пока нет отрицательных
наблюдения. Очевидно, что продолжительность запроса или размер ответа
никогда не отрицательный. В принципе, однако, вы можете использовать сводки и
гистограммы для наблюдения отрицательных значений (например, температуры в
по Цельсию). В этом случае сумма наблюдений может уменьшиться, поэтому вы
не может больше применять к нему rate () . В тех редких случаях, когда нужно
применить rate () и не избежать отрицательных наблюдений, вы можете использовать два
отдельные резюме, одно для положительных и одно для отрицательных наблюдений
(последний с перевернутым знаком), а затем объедините результаты с подходящими
Выражения PromQL.
Для расчета средней длительности запроса за последние 5 минут
из гистограммы или сводки под названием http_request_duration_seconds ,
используйте следующее выражение:
скорость (http_request_duration_seconds_sum [5m])
/
скорость (http_request_duration_seconds_count [5m])
оценка Apdex
Прямое использование гистограмм (но не сводок) заключается в подсчете наблюдения, попадающие в определенные периоды наблюдения значения.
У вас может быть SLO для обслуживания 95% запросов в течение 300 мс.В этом
случае, настройте гистограмму, чтобы иметь сегмент с верхним пределом
0,3 секунды. Затем вы можете напрямую выразить относительное количество
запросы обслуживаются в течение 300 мс и легко предупреждают, если значение упадет ниже
0,95. Следующее выражение вычисляет его по заданию для запросов
служил за последние 5 минут. Продолжительность запросов была собрана с
гистограмма называется http_request_duration_seconds .
сумма (ставка (http_request_duration_seconds_bucket {le = "0.3"} [5m])) по (заданию)
/
сумма (ставка (http_request_duration_seconds_count [5m])) по (задание)
Вы можете приблизиться к известному Apdex забейте аналогичным образом.Настроить ведро с целевой продолжительностью запроса в качестве верхней границы и другое ведро с допустимой продолжительностью запроса (обычно 4 раза длительность целевого запроса) в качестве верхней границы. Пример: цель длительность запроса — 300 мс. Допустимая длительность запроса — 1,2 с. В следующее выражение дает оценку Apdex для каждого задания за последний 5 минут:
(
сумма (ставка (http_request_duration_seconds_bucket {le = "0.3"} [5m])) по (задание)
+
сумма (ставка (http_request_duration_seconds_bucket {le = "1.2 "} [5м])) от (вакансии)
) / 2 / sum (rate (http_request_duration_seconds_count [5m])) по (job)
Обратите внимание, что мы делим сумму обоих сегментов. Причина в том, что гистограмма
ведра
кумулятивная. В le = "0.3" сегмент также содержится в сегменте le = "1.2" ; разделив его на 2
исправляет для этого.
Расчет не совсем соответствует традиционной оценке Apdex, так как включает ошибки в удовлетворительной и допустимой частях расчета.
квантилей
Вы можете использовать как сводки, так и гистограммы для вычисления так называемых φ-квантилей, где 0 ≤ φ ≤ 1.Φ-квантиль — это значение наблюдения, которое находится под номером φ * N среди N наблюдений. Примеры для φ-квантилей: 0,5-квантиль известная как медиана. Квантиль 0,95 — это 95-й процентиль.
Существенное различие между сводками и гистограммами состоит в том, что сводки
вычислять потоковые φ-квантили на стороне клиента и выставлять их напрямую,
в то время как гистограммы показывают подсчеты наблюдений с интервалами и расчет
квантили из сегментов гистограммы происходит на стороне сервера с использованием histogram_quantile () функция.
Эти два подхода имеют ряд различных последствий:
| Гистограмма | Сводка | |
|---|---|---|
| Требуемая конфигурация | Подбирайте ковши, соответствующие ожидаемому диапазону наблюдаемых значений. | Выберите желаемые φ-квантили и скользящее окно. Другие φ-квантили и скользящие окна не могут быть рассчитаны позже. |
| Производительность клиента | Наблюдения очень дешевы, так как им нужно только увеличивать счетчики. | Наблюдения дороги из-за вычисления квантиля потоковой передачи. |
| Производительность сервера | Сервер должен вычислить квантили. Вы можете использовать правила записи, если специальный расчет занимает слишком много времени (например, на большой панели инструментов). | Низкая стоимость на стороне сервера. |
Количество временных рядов (помимо серий _sum и _count ) | Один временной ряд на сконфигурированный сегмент. | Один временной ряд на сконфигурированный квантиль. |
| Квантильная ошибка (подробности см. Ниже) | Ошибка ограничена размером наблюдаемых значений шириной соответствующей корзины. | Ошибка ограничена размером φ настраиваемым значением. |
| Спецификация φ-квантиля и скользящего временного окна | Ad-hoc с выражениями Прометея. | Предварительно настроен клиентом. |
| Агрегация | Ad-hoc с выражениями Прометея. | В целом не агрегатируется. |
Обратите внимание на важность последнего элемента в таблице. Вернемся к
SLO обслуживает 95% запросов в течение 300 мс. На этот раз ты не
хотите отобразить процент запросов, обслуженных в течение 300 мс, но
вместо этого 95-й процентиль, то есть длительность запроса, в течение которой
вы обслужили 95% запросов. Для этого вы можете настроить
сводка с квантилем 0,95 и (например) 5-минутным спадом
времени, или вы настраиваете гистограмму с несколькими сегментами около 300 мс
марка, e.грамм. {le = "0.1"} , {le = "0.2"} , {le = "0.3"} и {le = "0.45"} . Если ваша служба реплицируется с несколькими
экземпляров, вы будете собирать длительность запросов от каждого из
их, а затем вы хотите объединить все в общую 95-ю
процентиль. Однако агрегирование предварительно вычисленных квантилей из
резюме редко имеет смысл. В данном конкретном случае усреднение
квантили дает статистически бессмысленные значения.
в среднем (http_request_duration_seconds {quantile = "0.95 "}) // ПЛОХО!
Используя гистограммы, агрегирование вполне возможно с histogram_quantile () функция.
histogram_quantile (0.95, sum (rate (http_request_duration_seconds_bucket [5m])) by (le)) // ХОРОШО.
Кроме того, если ваш SLO изменится, и теперь вы захотите построить 90-е процентиль, или вы хотите учесть последние 10 минут вместо последних 5 минут вам нужно только скорректировать выражение выше, и вам не нужно перенастраивать клиентов.
Ошибки квантильной оценки
квантилей, независимо от того, вычисляются ли они на стороне клиента или на стороне сервера. по оценкам. Важно понимать ошибки этого оценка.
Продолжая пример гистограммы сверху, представьте свой обычный
длительность запросов почти все очень близка к 220 мс, или в других
словами, если бы вы могли построить «истинную» гистограмму, вы бы увидели очень
резкий всплеск на 220 мс. В метрике гистограммы Прометея, как настроено
выше, почти все наблюдения и, следовательно, 95-й процентиль,
попадет в корзину с надписью {le = "0.3 "} , т. Е. Ковш от
От 200 мс до 300 мс. Реализация гистограммы гарантирует, что истинное
95-й процентиль находится где-то между 200 мс и 300 мс. Чтобы вернуть
одно значение (а не интервал), применяется линейный
интерполяция, которая в данном случае дает 295 мс. Расчетный
квантиль создает впечатление, что вы близки к нарушению
SLO, но на самом деле 95-й процентиль чуть выше 220 мс,
достаточно комфортное расстояние до вашего SLO.
Следующий шаг в нашем мысленном эксперименте: изменение внутренней маршрутизации добавляет фиксированное количество 100 мс ко всем длительностям запроса.Теперь просьба длительность имеет резкий всплеск на уровне 320 мс, и почти все наблюдения будут попадают в ведро от 300 мс до 450 мс. 95-й процентиль рассчитано равным 442,5 мс, хотя правильное значение близко к 320 мс. Хотя вы лишь немного выходите за рамки своего SLO, Расчетный 95-й квантиль выглядит намного хуже.
В сводке не возникло бы проблем с вычислением правильного процентиля. значение в обоих случаях, по крайней мере, если он использует соответствующий алгоритм на клиентская сторона (например, та, что используется Go клиент).К несчастью, вы не можете использовать сводку, если вам нужно агрегировать наблюдения из ряда экземпляров.
К счастью, благодаря правильному выбору границ ковша, даже в этот надуманный пример очень резких всплесков в распределении наблюдаемые значения, гистограмма смогла правильно идентифицировать, если вы находились внутри или за пределами вашего SLO. Кроме того, чем ближе фактическое значение квантиля соответствует нашему SLO (или, другими словами, значению, которое мы собственно больше всего интересует), тем точнее рассчитанное значение становится.
Давайте теперь еще раз модифицируем эксперимент. В новой настройке Распределение продолжительности запросов имеет всплеск в 150 мс, но это не так. такой же острый, как и раньше, и составляет только 90% наблюдения. 10% наблюдений равномерно распределены в длинных хвост между 150 мс и 450 мс. При таком распределении 95-й процентиль оказывается точно на нашем SLO в 300 мс. С гистограмме рассчитанное значение является точным, так как значение 95-го процентиль совпадает с одной из границ сегмента.Четный немного другие значения все равно будут точными, поскольку (надуманные) равномерное распределение в соответствующих сегментах — это именно то, что предполагает линейную интерполяцию внутри ведра.
Ошибка квантиля, сообщаемая сводкой, становится более интересной. сейчас. Ошибка квантиля в сводке настраивается в размер φ. В нашем случае мы могли бы настроить 0,95 ± 0,01, то есть рассчитанное значение будет между 94-м и 96-м. процентиль. 94-й квантиль с описанным выше распределением равен 270 мс, 96-й квантиль — 330 мс.Расчетное значение 95-го процентиль, сообщаемый сводкой, может быть в любом месте интервала между 270 мс и 330 мс, и это, к сожалению, вся разница между явно в пределах SLO и явно вне SLO.
Итог: если вы используете сводку, вы контролируете ошибку в размер φ. Если вы используете гистограмму, вы контролируете ошибку в размер наблюдаемого значения (путем выбора соответствующего ведра макет). При широком распределении небольшие изменения φ приводят к большие отклонения от наблюдаемого значения.При резком распределении малый интервал наблюдаемых значений покрывает большой интервал φ.
Два практических правила:
Если вам нужно агрегировать, выберите гистограммы.
В противном случае выберите гистограмму, если вы имеете представление о диапазоне и распределение ценностей, которые будут соблюдаться. Выберите резюме, если вам нужен точный квантиль, независимо от диапазон и распределение значений есть.
Что делать, если моя клиентская библиотека не поддерживает нужный мне тип метрики?
Реализуйте это! Добавления кода приветствуются.В общем, мы ожидайте, что гистограммы будут нужны более срочно, чем сводки. Гистограммы также проще реализовать в клиентской библиотеке, поэтому мы рекомендуем реализовать сначала гистограммы, если есть сомнения.
Эта документация с открытым исходным кодом. Пожалуйста, помогите улучшить его, заполнив вопросы или запросы на вытягивание.
Гистограмм и сводки | Прометей
Гистограммы и сводки относятся к более сложным типам показателей. Не только одна гистограмма или сводка создают множество временных рядов, это Также труднее правильно использовать эти типы метрик.Эта секция поможет вам выбрать и настроить соответствующий тип метрики для вашего вариант использования.
Поддержка библиотеки
Прежде всего, проверьте поддержку библиотеки для гистограммы и резюме.
Некоторые библиотеки поддерживают только один из двух типов или поддерживают сводки. только ограниченно (без расчета квантилей).
Подсчет и сумма наблюдений
Гистограммы и сводки обоих выборочных наблюдений, обычно запрашиваются
продолжительность или размер ответа.Они отслеживают количество наблюдений и сумма наблюдаемых значений, позволяющая вычислить среднее значение наблюдаемых значений. Обратите внимание, что количество наблюдений
(отображается в Prometheus как временной ряд с суффиксом _count )
по своей сути счетчик (как описано выше, он только растет). Сумма
наблюдения (отображаются как временной ряд с суффиксом _sum )
тоже ведет себя как счетчик, пока нет отрицательных
наблюдения.Очевидно, что продолжительность запроса или размер ответа
никогда не отрицательный. В принципе, однако, вы можете использовать сводки и
гистограммы для наблюдения отрицательных значений (например, температуры в
по Цельсию). В этом случае сумма наблюдений может уменьшиться, поэтому вы
не может больше применять к нему rate () . В тех редких случаях, когда нужно
применить rate () и не избежать отрицательных наблюдений, вы можете использовать два
отдельные резюме, одно для положительных и одно для отрицательных наблюдений
(последний с перевернутым знаком), а затем объедините результаты с подходящими
Выражения PromQL.
Для расчета средней длительности запроса за последние 5 минут
из гистограммы или сводки под названием http_request_duration_seconds ,
используйте следующее выражение:
скорость (http_request_duration_seconds_sum [5m])
/
скорость (http_request_duration_seconds_count [5m])
оценка Apdex
Прямое использование гистограмм (но не сводок) заключается в подсчете наблюдения, попадающие в определенные периоды наблюдения значения.
У вас может быть SLO для обслуживания 95% запросов в течение 300 мс.В этом
случае, настройте гистограмму, чтобы иметь сегмент с верхним пределом
0,3 секунды. Затем вы можете напрямую выразить относительное количество
запросы обслуживаются в течение 300 мс и легко предупреждают, если значение упадет ниже
0,95. Следующее выражение вычисляет его по заданию для запросов
служил за последние 5 минут. Продолжительность запросов была собрана с
гистограмма называется http_request_duration_seconds .
сумма (ставка (http_request_duration_seconds_bucket {le = "0.3"} [5m])) по (заданию)
/
сумма (ставка (http_request_duration_seconds_count [5m])) по (задание)
Вы можете приблизиться к известному Apdex забейте аналогичным образом.Настроить ведро с целевой продолжительностью запроса в качестве верхней границы и другое ведро с допустимой продолжительностью запроса (обычно 4 раза длительность целевого запроса) в качестве верхней границы. Пример: цель длительность запроса — 300 мс. Допустимая длительность запроса — 1,2 с. В следующее выражение дает оценку Apdex для каждого задания за последний 5 минут:
(
сумма (ставка (http_request_duration_seconds_bucket {le = "0.3"} [5m])) по (задание)
+
сумма (ставка (http_request_duration_seconds_bucket {le = "1.2 "} [5м])) от (вакансии)
) / 2 / sum (rate (http_request_duration_seconds_count [5m])) по (job)
Обратите внимание, что мы делим сумму обоих сегментов. Причина в том, что гистограмма
ведра
кумулятивная. В le = "0.3" сегмент также содержится в сегменте le = "1.2" ; разделив его на 2
исправляет для этого.
Расчет не совсем соответствует традиционной оценке Apdex, так как включает ошибки в удовлетворительной и допустимой частях расчета.
квантилей
Вы можете использовать как сводки, так и гистограммы для вычисления так называемых φ-квантилей, где 0 ≤ φ ≤ 1.Φ-квантиль — это значение наблюдения, которое находится под номером φ * N среди N наблюдений. Примеры для φ-квантилей: 0,5-квантиль известная как медиана. Квантиль 0,95 — это 95-й процентиль.
Существенное различие между сводками и гистограммами состоит в том, что сводки
вычислять потоковые φ-квантили на стороне клиента и выставлять их напрямую,
в то время как гистограммы показывают подсчеты наблюдений с интервалами и расчет
квантили из сегментов гистограммы происходит на стороне сервера с использованием histogram_quantile () функция.
Эти два подхода имеют ряд различных последствий:
| Гистограмма | Сводка | |
|---|---|---|
| Требуемая конфигурация | Подбирайте ковши, соответствующие ожидаемому диапазону наблюдаемых значений. | Выберите желаемые φ-квантили и скользящее окно. Другие φ-квантили и скользящие окна не могут быть рассчитаны позже. |
| Производительность клиента | Наблюдения очень дешевы, так как им нужно только увеличивать счетчики. | Наблюдения дороги из-за вычисления квантиля потоковой передачи. |
| Производительность сервера | Сервер должен вычислить квантили. Вы можете использовать правила записи, если специальный расчет занимает слишком много времени (например, на большой панели инструментов). | Низкая стоимость на стороне сервера. |
Количество временных рядов (помимо серий _sum и _count ) | Один временной ряд на сконфигурированный сегмент. | Один временной ряд на сконфигурированный квантиль. |
| Квантильная ошибка (подробности см. Ниже) | Ошибка ограничена размером наблюдаемых значений шириной соответствующей корзины. | Ошибка ограничена размером φ настраиваемым значением. |
| Спецификация φ-квантиля и скользящего временного окна | Ad-hoc с выражениями Прометея. | Предварительно настроен клиентом. |
| Агрегация | Ad-hoc с выражениями Прометея. | В целом не агрегатируется. |
Обратите внимание на важность последнего элемента в таблице. Вернемся к
SLO обслуживает 95% запросов в течение 300 мс. На этот раз ты не
хотите отобразить процент запросов, обслуженных в течение 300 мс, но
вместо этого 95-й процентиль, то есть длительность запроса, в течение которой
вы обслужили 95% запросов. Для этого вы можете настроить
сводка с квантилем 0,95 и (например) 5-минутным спадом
времени, или вы настраиваете гистограмму с несколькими сегментами около 300 мс
марка, e.грамм. {le = "0.1"} , {le = "0.2"} , {le = "0.3"} и {le = "0.45"} . Если ваша служба реплицируется с несколькими
экземпляров, вы будете собирать длительность запросов от каждого из
их, а затем вы хотите объединить все в общую 95-ю
процентиль. Однако агрегирование предварительно вычисленных квантилей из
резюме редко имеет смысл. В данном конкретном случае усреднение
квантили дает статистически бессмысленные значения.
в среднем (http_request_duration_seconds {quantile = "0.95 "}) // ПЛОХО!
Используя гистограммы, агрегирование вполне возможно с histogram_quantile () функция.
histogram_quantile (0.95, sum (rate (http_request_duration_seconds_bucket [5m])) by (le)) // ХОРОШО.
Кроме того, если ваш SLO изменится, и теперь вы захотите построить 90-е процентиль, или вы хотите учесть последние 10 минут вместо последних 5 минут вам нужно только скорректировать выражение выше, и вам не нужно перенастраивать клиентов.
Ошибки квантильной оценки
квантилей, независимо от того, вычисляются ли они на стороне клиента или на стороне сервера. по оценкам. Важно понимать ошибки этого оценка.
Продолжая пример гистограммы сверху, представьте свой обычный
длительность запросов почти все очень близка к 220 мс, или в других
словами, если бы вы могли построить «истинную» гистограмму, вы бы увидели очень
резкий всплеск на 220 мс. В метрике гистограммы Прометея, как настроено
выше, почти все наблюдения и, следовательно, 95-й процентиль,
попадет в корзину с надписью {le = "0.3 "} , т. Е. Ковш от
От 200 мс до 300 мс. Реализация гистограммы гарантирует, что истинное
95-й процентиль находится где-то между 200 мс и 300 мс. Чтобы вернуть
одно значение (а не интервал), применяется линейный
интерполяция, которая в данном случае дает 295 мс. Расчетный
квантиль создает впечатление, что вы близки к нарушению
SLO, но на самом деле 95-й процентиль чуть выше 220 мс,
достаточно комфортное расстояние до вашего SLO.
Следующий шаг в нашем мысленном эксперименте: изменение внутренней маршрутизации добавляет фиксированное количество 100 мс ко всем длительностям запроса.Теперь просьба длительность имеет резкий всплеск на уровне 320 мс, и почти все наблюдения будут попадают в ведро от 300 мс до 450 мс. 95-й процентиль рассчитано равным 442,5 мс, хотя правильное значение близко к 320 мс. Хотя вы лишь немного выходите за рамки своего SLO, Расчетный 95-й квантиль выглядит намного хуже.
В сводке не возникло бы проблем с вычислением правильного процентиля. значение в обоих случаях, по крайней мере, если он использует соответствующий алгоритм на клиентская сторона (например, та, что используется Go клиент).К несчастью, вы не можете использовать сводку, если вам нужно агрегировать наблюдения из ряда экземпляров.
К счастью, благодаря правильному выбору границ ковша, даже в этот надуманный пример очень резких всплесков в распределении наблюдаемые значения, гистограмма смогла правильно идентифицировать, если вы находились внутри или за пределами вашего SLO. Кроме того, чем ближе фактическое значение квантиля соответствует нашему SLO (или, другими словами, значению, которое мы собственно больше всего интересует), тем точнее рассчитанное значение становится.
Давайте теперь еще раз модифицируем эксперимент. В новой настройке Распределение продолжительности запросов имеет всплеск в 150 мс, но это не так. такой же острый, как и раньше, и составляет только 90% наблюдения. 10% наблюдений равномерно распределены в длинных хвост между 150 мс и 450 мс. При таком распределении 95-й процентиль оказывается точно на нашем SLO в 300 мс. С гистограмме рассчитанное значение является точным, так как значение 95-го процентиль совпадает с одной из границ сегмента.Четный немного другие значения все равно будут точными, поскольку (надуманные) равномерное распределение в соответствующих сегментах — это именно то, что предполагает линейную интерполяцию внутри ведра.
Ошибка квантиля, сообщаемая сводкой, становится более интересной. сейчас. Ошибка квантиля в сводке настраивается в размер φ. В нашем случае мы могли бы настроить 0,95 ± 0,01, то есть рассчитанное значение будет между 94-м и 96-м. процентиль. 94-й квантиль с описанным выше распределением равен 270 мс, 96-й квантиль — 330 мс.Расчетное значение 95-го процентиль, сообщаемый сводкой, может быть в любом месте интервала между 270 мс и 330 мс, и это, к сожалению, вся разница между явно в пределах SLO и явно вне SLO.
Итог: если вы используете сводку, вы контролируете ошибку в размер φ. Если вы используете гистограмму, вы контролируете ошибку в размер наблюдаемого значения (путем выбора соответствующего ведра макет). При широком распределении небольшие изменения φ приводят к большие отклонения от наблюдаемого значения.При резком распределении малый интервал наблюдаемых значений покрывает большой интервал φ.
Два практических правила:
Если вам нужно агрегировать, выберите гистограммы.
В противном случае выберите гистограмму, если вы имеете представление о диапазоне и распределение ценностей, которые будут соблюдаться. Выберите резюме, если вам нужен точный квантиль, независимо от диапазон и распределение значений есть.
Что делать, если моя клиентская библиотека не поддерживает нужный мне тип метрики?
Реализуйте это! Добавления кода приветствуются.В общем, мы ожидайте, что гистограммы будут нужны более срочно, чем сводки. Гистограммы также проще реализовать в клиентской библиотеке, поэтому мы рекомендуем реализовать сначала гистограммы, если есть сомнения.
Эта документация с открытым исходным кодом. Пожалуйста, помогите улучшить его, заполнив вопросы или запросы на вытягивание.
Гистограмм и сводки | Прометей
Гистограммы и сводки относятся к более сложным типам показателей. Не только одна гистограмма или сводка создают множество временных рядов, это Также труднее правильно использовать эти типы метрик.Эта секция поможет вам выбрать и настроить соответствующий тип метрики для вашего вариант использования.
Поддержка библиотеки
Прежде всего, проверьте поддержку библиотеки для гистограммы и резюме.
Некоторые библиотеки поддерживают только один из двух типов или поддерживают сводки. только ограниченно (без расчета квантилей).
Подсчет и сумма наблюдений
Гистограммы и сводки обоих выборочных наблюдений, обычно запрашиваются
продолжительность или размер ответа.Они отслеживают количество наблюдений и сумма наблюдаемых значений, позволяющая вычислить среднее значение наблюдаемых значений. Обратите внимание, что количество наблюдений
(отображается в Prometheus как временной ряд с суффиксом _count )
по своей сути счетчик (как описано выше, он только растет). Сумма
наблюдения (отображаются как временной ряд с суффиксом _sum )
тоже ведет себя как счетчик, пока нет отрицательных
наблюдения.Очевидно, что продолжительность запроса или размер ответа
никогда не отрицательный. В принципе, однако, вы можете использовать сводки и
гистограммы для наблюдения отрицательных значений (например, температуры в
по Цельсию). В этом случае сумма наблюдений может уменьшиться, поэтому вы
не может больше применять к нему rate () . В тех редких случаях, когда нужно
применить rate () и не избежать отрицательных наблюдений, вы можете использовать два
отдельные резюме, одно для положительных и одно для отрицательных наблюдений
(последний с перевернутым знаком), а затем объедините результаты с подходящими
Выражения PromQL.
Для расчета средней длительности запроса за последние 5 минут
из гистограммы или сводки под названием http_request_duration_seconds ,
используйте следующее выражение:
скорость (http_request_duration_seconds_sum [5m])
/
скорость (http_request_duration_seconds_count [5m])
оценка Apdex
Прямое использование гистограмм (но не сводок) заключается в подсчете наблюдения, попадающие в определенные периоды наблюдения значения.
У вас может быть SLO для обслуживания 95% запросов в течение 300 мс.В этом
случае, настройте гистограмму, чтобы иметь сегмент с верхним пределом
0,3 секунды. Затем вы можете напрямую выразить относительное количество
запросы обслуживаются в течение 300 мс и легко предупреждают, если значение упадет ниже
0,95. Следующее выражение вычисляет его по заданию для запросов
служил за последние 5 минут. Продолжительность запросов была собрана с
гистограмма называется http_request_duration_seconds .
сумма (ставка (http_request_duration_seconds_bucket {le = "0.3"} [5m])) по (заданию)
/
сумма (ставка (http_request_duration_seconds_count [5m])) по (задание)
Вы можете приблизиться к известному Apdex забейте аналогичным образом.Настроить ведро с целевой продолжительностью запроса в качестве верхней границы и другое ведро с допустимой продолжительностью запроса (обычно 4 раза длительность целевого запроса) в качестве верхней границы. Пример: цель длительность запроса — 300 мс. Допустимая длительность запроса — 1,2 с. В следующее выражение дает оценку Apdex для каждого задания за последний 5 минут:
(
сумма (ставка (http_request_duration_seconds_bucket {le = "0.3"} [5m])) по (задание)
+
сумма (ставка (http_request_duration_seconds_bucket {le = "1.2 "} [5м])) от (вакансии)
) / 2 / sum (rate (http_request_duration_seconds_count [5m])) по (job)
Обратите внимание, что мы делим сумму обоих сегментов. Причина в том, что гистограмма
ведра
кумулятивная. В le = "0.3" сегмент также содержится в сегменте le = "1.2" ; разделив его на 2
исправляет для этого.
Расчет не совсем соответствует традиционной оценке Apdex, так как включает ошибки в удовлетворительной и допустимой частях расчета.
квантилей
Вы можете использовать как сводки, так и гистограммы для вычисления так называемых φ-квантилей, где 0 ≤ φ ≤ 1.Φ-квантиль — это значение наблюдения, которое находится под номером φ * N среди N наблюдений. Примеры для φ-квантилей: 0,5-квантиль известная как медиана. Квантиль 0,95 — это 95-й процентиль.
Существенное различие между сводками и гистограммами состоит в том, что сводки
вычислять потоковые φ-квантили на стороне клиента и выставлять их напрямую,
в то время как гистограммы показывают подсчеты наблюдений с интервалами и расчет
квантили из сегментов гистограммы происходит на стороне сервера с использованием histogram_quantile () функция.
Эти два подхода имеют ряд различных последствий:
| Гистограмма | Сводка | |
|---|---|---|
| Требуемая конфигурация | Подбирайте ковши, соответствующие ожидаемому диапазону наблюдаемых значений. | Выберите желаемые φ-квантили и скользящее окно. Другие φ-квантили и скользящие окна не могут быть рассчитаны позже. |
| Производительность клиента | Наблюдения очень дешевы, так как им нужно только увеличивать счетчики. | Наблюдения дороги из-за вычисления квантиля потоковой передачи. |
| Производительность сервера | Сервер должен вычислить квантили. Вы можете использовать правила записи, если специальный расчет занимает слишком много времени (например, на большой панели инструментов). | Низкая стоимость на стороне сервера. |
Количество временных рядов (помимо серий _sum и _count ) | Один временной ряд на сконфигурированный сегмент. | Один временной ряд на сконфигурированный квантиль. |
| Квантильная ошибка (подробности см. Ниже) | Ошибка ограничена размером наблюдаемых значений шириной соответствующей корзины. | Ошибка ограничена размером φ настраиваемым значением. |
| Спецификация φ-квантиля и скользящего временного окна | Ad-hoc с выражениями Прометея. | Предварительно настроен клиентом. |
| Агрегация | Ad-hoc с выражениями Прометея. | В целом не агрегатируется. |
Обратите внимание на важность последнего элемента в таблице. Вернемся к
SLO обслуживает 95% запросов в течение 300 мс. На этот раз ты не
хотите отобразить процент запросов, обслуженных в течение 300 мс, но
вместо этого 95-й процентиль, то есть длительность запроса, в течение которой
вы обслужили 95% запросов. Для этого вы можете настроить
сводка с квантилем 0,95 и (например) 5-минутным спадом
времени, или вы настраиваете гистограмму с несколькими сегментами около 300 мс
марка, e.грамм. {le = "0.1"} , {le = "0.2"} , {le = "0.3"} и {le = "0.45"} . Если ваша служба реплицируется с несколькими
экземпляров, вы будете собирать длительность запросов от каждого из
их, а затем вы хотите объединить все в общую 95-ю
процентиль. Однако агрегирование предварительно вычисленных квантилей из
резюме редко имеет смысл. В данном конкретном случае усреднение
квантили дает статистически бессмысленные значения.
в среднем (http_request_duration_seconds {quantile = "0.95 "}) // ПЛОХО!
Используя гистограммы, агрегирование вполне возможно с histogram_quantile () функция.
histogram_quantile (0.95, sum (rate (http_request_duration_seconds_bucket [5m])) by (le)) // ХОРОШО.
Кроме того, если ваш SLO изменится, и теперь вы захотите построить 90-е процентиль, или вы хотите учесть последние 10 минут вместо последних 5 минут вам нужно только скорректировать выражение выше, и вам не нужно перенастраивать клиентов.
Ошибки квантильной оценки
квантилей, независимо от того, вычисляются ли они на стороне клиента или на стороне сервера. по оценкам. Важно понимать ошибки этого оценка.
Продолжая пример гистограммы сверху, представьте свой обычный
длительность запросов почти все очень близка к 220 мс, или в других
словами, если бы вы могли построить «истинную» гистограмму, вы бы увидели очень
резкий всплеск на 220 мс. В метрике гистограммы Прометея, как настроено
выше, почти все наблюдения и, следовательно, 95-й процентиль,
попадет в корзину с надписью {le = "0.3 "} , т. Е. Ковш от
От 200 мс до 300 мс. Реализация гистограммы гарантирует, что истинное
95-й процентиль находится где-то между 200 мс и 300 мс. Чтобы вернуть
одно значение (а не интервал), применяется линейный
интерполяция, которая в данном случае дает 295 мс. Расчетный
квантиль создает впечатление, что вы близки к нарушению
SLO, но на самом деле 95-й процентиль чуть выше 220 мс,
достаточно комфортное расстояние до вашего SLO.
Следующий шаг в нашем мысленном эксперименте: изменение внутренней маршрутизации добавляет фиксированное количество 100 мс ко всем длительностям запроса.Теперь просьба длительность имеет резкий всплеск на уровне 320 мс, и почти все наблюдения будут попадают в ведро от 300 мс до 450 мс. 95-й процентиль рассчитано равным 442,5 мс, хотя правильное значение близко к 320 мс. Хотя вы лишь немного выходите за рамки своего SLO, Расчетный 95-й квантиль выглядит намного хуже.
В сводке не возникло бы проблем с вычислением правильного процентиля. значение в обоих случаях, по крайней мере, если он использует соответствующий алгоритм на клиентская сторона (например, та, что используется Go клиент).К несчастью, вы не можете использовать сводку, если вам нужно агрегировать наблюдения из ряда экземпляров.
К счастью, благодаря правильному выбору границ ковша, даже в этот надуманный пример очень резких всплесков в распределении наблюдаемые значения, гистограмма смогла правильно идентифицировать, если вы находились внутри или за пределами вашего SLO. Кроме того, чем ближе фактическое значение квантиля соответствует нашему SLO (или, другими словами, значению, которое мы собственно больше всего интересует), тем точнее рассчитанное значение становится.
Давайте теперь еще раз модифицируем эксперимент. В новой настройке Распределение продолжительности запросов имеет всплеск в 150 мс, но это не так. такой же острый, как и раньше, и составляет только 90% наблюдения. 10% наблюдений равномерно распределены в длинных хвост между 150 мс и 450 мс. При таком распределении 95-й процентиль оказывается точно на нашем SLO в 300 мс. С гистограмме рассчитанное значение является точным, так как значение 95-го процентиль совпадает с одной из границ сегмента.Четный немного другие значения все равно будут точными, поскольку (надуманные) равномерное распределение в соответствующих сегментах — это именно то, что предполагает линейную интерполяцию внутри ведра.
Ошибка квантиля, сообщаемая сводкой, становится более интересной. сейчас. Ошибка квантиля в сводке настраивается в размер φ. В нашем случае мы могли бы настроить 0,95 ± 0,01, то есть рассчитанное значение будет между 94-м и 96-м. процентиль. 94-й квантиль с описанным выше распределением равен 270 мс, 96-й квантиль — 330 мс.Расчетное значение 95-го процентиль, сообщаемый сводкой, может быть в любом месте интервала между 270 мс и 330 мс, и это, к сожалению, вся разница между явно в пределах SLO и явно вне SLO.
Итог: если вы используете сводку, вы контролируете ошибку в размер φ. Если вы используете гистограмму, вы контролируете ошибку в размер наблюдаемого значения (путем выбора соответствующего ведра макет). При широком распределении небольшие изменения φ приводят к большие отклонения от наблюдаемого значения.При резком распределении малый интервал наблюдаемых значений покрывает большой интервал φ.
Два практических правила:
Если вам нужно агрегировать, выберите гистограммы.
В противном случае выберите гистограмму, если вы имеете представление о диапазоне и распределение ценностей, которые будут соблюдаться. Выберите резюме, если вам нужен точный квантиль, независимо от диапазон и распределение значений есть.
Что делать, если моя клиентская библиотека не поддерживает нужный мне тип метрики?
Реализуйте это! Добавления кода приветствуются.В общем, мы ожидайте, что гистограммы будут нужны более срочно, чем сводки. Гистограммы также проще реализовать в клиентской библиотеке, поэтому мы рекомендуем реализовать сначала гистограммы, если есть сомнения.
Эта документация с открытым исходным кодом. Пожалуйста, помогите улучшить его, заполнив вопросы или запросы на вытягивание.
Гистограмм и сводки | Прометей
Гистограммы и сводки относятся к более сложным типам показателей. Не только одна гистограмма или сводка создают множество временных рядов, это Также труднее правильно использовать эти типы метрик.Эта секция поможет вам выбрать и настроить соответствующий тип метрики для вашего вариант использования.
Поддержка библиотеки
Прежде всего, проверьте поддержку библиотеки для гистограммы и резюме.
Некоторые библиотеки поддерживают только один из двух типов или поддерживают сводки. только ограниченно (без расчета квантилей).
Подсчет и сумма наблюдений
Гистограммы и сводки обоих выборочных наблюдений, обычно запрашиваются
продолжительность или размер ответа.Они отслеживают количество наблюдений и сумма наблюдаемых значений, позволяющая вычислить среднее значение наблюдаемых значений. Обратите внимание, что количество наблюдений
(отображается в Prometheus как временной ряд с суффиксом _count )
по своей сути счетчик (как описано выше, он только растет). Сумма
наблюдения (отображаются как временной ряд с суффиксом _sum )
тоже ведет себя как счетчик, пока нет отрицательных
наблюдения.Очевидно, что продолжительность запроса или размер ответа
никогда не отрицательный. В принципе, однако, вы можете использовать сводки и
гистограммы для наблюдения отрицательных значений (например, температуры в
по Цельсию). В этом случае сумма наблюдений может уменьшиться, поэтому вы
не может больше применять к нему rate () . В тех редких случаях, когда нужно
применить rate () и не избежать отрицательных наблюдений, вы можете использовать два
отдельные резюме, одно для положительных и одно для отрицательных наблюдений
(последний с перевернутым знаком), а затем объедините результаты с подходящими
Выражения PromQL.
Для расчета средней длительности запроса за последние 5 минут
из гистограммы или сводки под названием http_request_duration_seconds ,
используйте следующее выражение:
скорость (http_request_duration_seconds_sum [5m])
/
скорость (http_request_duration_seconds_count [5m])
оценка Apdex
Прямое использование гистограмм (но не сводок) заключается в подсчете наблюдения, попадающие в определенные периоды наблюдения значения.
У вас может быть SLO для обслуживания 95% запросов в течение 300 мс.В этом
случае, настройте гистограмму, чтобы иметь сегмент с верхним пределом
0,3 секунды. Затем вы можете напрямую выразить относительное количество
запросы обслуживаются в течение 300 мс и легко предупреждают, если значение упадет ниже
0,95. Следующее выражение вычисляет его по заданию для запросов
служил за последние 5 минут. Продолжительность запросов была собрана с
гистограмма называется http_request_duration_seconds .
сумма (ставка (http_request_duration_seconds_bucket {le = "0.3"} [5m])) по (заданию)
/
сумма (ставка (http_request_duration_seconds_count [5m])) по (задание)
Вы можете приблизиться к известному Apdex забейте аналогичным образом.Настроить ведро с целевой продолжительностью запроса в качестве верхней границы и другое ведро с допустимой продолжительностью запроса (обычно 4 раза длительность целевого запроса) в качестве верхней границы. Пример: цель длительность запроса — 300 мс. Допустимая длительность запроса — 1,2 с. В следующее выражение дает оценку Apdex для каждого задания за последний 5 минут:
(
сумма (ставка (http_request_duration_seconds_bucket {le = "0.3"} [5m])) по (задание)
+
сумма (ставка (http_request_duration_seconds_bucket {le = "1.2 "} [5м])) от (вакансии)
) / 2 / sum (rate (http_request_duration_seconds_count [5m])) по (job)
Обратите внимание, что мы делим сумму обоих сегментов. Причина в том, что гистограмма
ведра
кумулятивная. В le = "0.3" сегмент также содержится в сегменте le = "1.2" ; разделив его на 2
исправляет для этого.
Расчет не совсем соответствует традиционной оценке Apdex, так как включает ошибки в удовлетворительной и допустимой частях расчета.
квантилей
Вы можете использовать как сводки, так и гистограммы для вычисления так называемых φ-квантилей, где 0 ≤ φ ≤ 1.Φ-квантиль — это значение наблюдения, которое находится под номером φ * N среди N наблюдений. Примеры для φ-квантилей: 0,5-квантиль известная как медиана. Квантиль 0,95 — это 95-й процентиль.
Существенное различие между сводками и гистограммами состоит в том, что сводки
вычислять потоковые φ-квантили на стороне клиента и выставлять их напрямую,
в то время как гистограммы показывают подсчеты наблюдений с интервалами и расчет
квантили из сегментов гистограммы происходит на стороне сервера с использованием histogram_quantile () функция.
Эти два подхода имеют ряд различных последствий:
| Гистограмма | Сводка | |
|---|---|---|
| Требуемая конфигурация | Подбирайте ковши, соответствующие ожидаемому диапазону наблюдаемых значений. | Выберите желаемые φ-квантили и скользящее окно. Другие φ-квантили и скользящие окна не могут быть рассчитаны позже. |
| Производительность клиента | Наблюдения очень дешевы, так как им нужно только увеличивать счетчики. | Наблюдения дороги из-за вычисления квантиля потоковой передачи. |
| Производительность сервера | Сервер должен вычислить квантили. Вы можете использовать правила записи, если специальный расчет занимает слишком много времени (например, на большой панели инструментов). | Низкая стоимость на стороне сервера. |
Количество временных рядов (помимо серий _sum и _count ) | Один временной ряд на сконфигурированный сегмент. | Один временной ряд на сконфигурированный квантиль. |
| Квантильная ошибка (подробности см. Ниже) | Ошибка ограничена размером наблюдаемых значений шириной соответствующей корзины. | Ошибка ограничена размером φ настраиваемым значением. |
| Спецификация φ-квантиля и скользящего временного окна | Ad-hoc с выражениями Прометея. | Предварительно настроен клиентом. |
| Агрегация | Ad-hoc с выражениями Прометея. | В целом не агрегатируется. |
Обратите внимание на важность последнего элемента в таблице. Вернемся к
SLO обслуживает 95% запросов в течение 300 мс. На этот раз ты не
хотите отобразить процент запросов, обслуженных в течение 300 мс, но
вместо этого 95-й процентиль, то есть длительность запроса, в течение которой
вы обслужили 95% запросов. Для этого вы можете настроить
сводка с квантилем 0,95 и (например) 5-минутным спадом
времени, или вы настраиваете гистограмму с несколькими сегментами около 300 мс
марка, e.грамм. {le = "0.1"} , {le = "0.2"} , {le = "0.3"} и {le = "0.45"} . Если ваша служба реплицируется с несколькими
экземпляров, вы будете собирать длительность запросов от каждого из
их, а затем вы хотите объединить все в общую 95-ю
процентиль. Однако агрегирование предварительно вычисленных квантилей из
резюме редко имеет смысл. В данном конкретном случае усреднение
квантили дает статистически бессмысленные значения.
в среднем (http_request_duration_seconds {quantile = "0.95 "}) // ПЛОХО!
Используя гистограммы, агрегирование вполне возможно с histogram_quantile () функция.
histogram_quantile (0.95, sum (rate (http_request_duration_seconds_bucket [5m])) by (le)) // ХОРОШО.
Кроме того, если ваш SLO изменится, и теперь вы захотите построить 90-е процентиль, или вы хотите учесть последние 10 минут вместо последних 5 минут вам нужно только скорректировать выражение выше, и вам не нужно перенастраивать клиентов.
Ошибки квантильной оценки
квантилей, независимо от того, вычисляются ли они на стороне клиента или на стороне сервера. по оценкам. Важно понимать ошибки этого оценка.
Продолжая пример гистограммы сверху, представьте свой обычный
длительность запросов почти все очень близка к 220 мс, или в других
словами, если бы вы могли построить «истинную» гистограмму, вы бы увидели очень
резкий всплеск на 220 мс. В метрике гистограммы Прометея, как настроено
выше, почти все наблюдения и, следовательно, 95-й процентиль,
попадет в корзину с надписью {le = "0.3 "} , т. Е. Ковш от
От 200 мс до 300 мс. Реализация гистограммы гарантирует, что истинное
95-й процентиль находится где-то между 200 мс и 300 мс. Чтобы вернуть
одно значение (а не интервал), применяется линейный
интерполяция, которая в данном случае дает 295 мс. Расчетный
квантиль создает впечатление, что вы близки к нарушению
SLO, но на самом деле 95-й процентиль чуть выше 220 мс,
достаточно комфортное расстояние до вашего SLO.
Следующий шаг в нашем мысленном эксперименте: изменение внутренней маршрутизации добавляет фиксированное количество 100 мс ко всем длительностям запроса.Теперь просьба длительность имеет резкий всплеск на уровне 320 мс, и почти все наблюдения будут попадают в ведро от 300 мс до 450 мс. 95-й процентиль рассчитано равным 442,5 мс, хотя правильное значение близко к 320 мс. Хотя вы лишь немного выходите за рамки своего SLO, Расчетный 95-й квантиль выглядит намного хуже.
В сводке не возникло бы проблем с вычислением правильного процентиля. значение в обоих случаях, по крайней мере, если он использует соответствующий алгоритм на клиентская сторона (например, та, что используется Go клиент).К несчастью, вы не можете использовать сводку, если вам нужно агрегировать наблюдения из ряда экземпляров.
К счастью, благодаря правильному выбору границ ковша, даже в этот надуманный пример очень резких всплесков в распределении наблюдаемые значения, гистограмма смогла правильно идентифицировать, если вы находились внутри или за пределами вашего SLO. Кроме того, чем ближе фактическое значение квантиля соответствует нашему SLO (или, другими словами, значению, которое мы собственно больше всего интересует), тем точнее рассчитанное значение становится.
Давайте теперь еще раз модифицируем эксперимент. В новой настройке Распределение продолжительности запросов имеет всплеск в 150 мс, но это не так. такой же острый, как и раньше, и составляет только 90% наблюдения. 10% наблюдений равномерно распределены в длинных хвост между 150 мс и 450 мс. При таком распределении 95-й процентиль оказывается точно на нашем SLO в 300 мс. С гистограмме рассчитанное значение является точным, так как значение 95-го процентиль совпадает с одной из границ сегмента.Четный немного другие значения все равно будут точными, поскольку (надуманные) равномерное распределение в соответствующих сегментах — это именно то, что предполагает линейную интерполяцию внутри ведра.
Ошибка квантиля, сообщаемая сводкой, становится более интересной. сейчас. Ошибка квантиля в сводке настраивается в размер φ. В нашем случае мы могли бы настроить 0,95 ± 0,01, то есть рассчитанное значение будет между 94-м и 96-м. процентиль. 94-й квантиль с описанным выше распределением равен 270 мс, 96-й квантиль — 330 мс.Расчетное значение 95-го процентиль, сообщаемый сводкой, может быть в любом месте интервала между 270 мс и 330 мс, и это, к сожалению, вся разница между явно в пределах SLO и явно вне SLO.
Итог: если вы используете сводку, вы контролируете ошибку в размер φ. Если вы используете гистограмму, вы контролируете ошибку в размер наблюдаемого значения (путем выбора соответствующего ведра макет). При широком распределении небольшие изменения φ приводят к большие отклонения от наблюдаемого значения.При резком распределении малый интервал наблюдаемых значений покрывает большой интервал φ.
Два практических правила:
Если вам нужно агрегировать, выберите гистограммы.
В противном случае выберите гистограмму, если вы имеете представление о диапазоне и распределение ценностей, которые будут соблюдаться. Выберите резюме, если вам нужен точный квантиль, независимо от диапазон и распределение значений есть.
Что делать, если моя клиентская библиотека не поддерживает нужный мне тип метрики?
Реализуйте это! Добавления кода приветствуются.В общем, мы ожидайте, что гистограммы будут нужны более срочно, чем сводки. Гистограммы также проще реализовать в клиентской библиотеке, поэтому мы рекомендуем реализовать сначала гистограммы, если есть сомнения.
Эта документация с открытым исходным кодом. Пожалуйста, помогите улучшить его, заполнив вопросы или запросы на вытягивание.
Как использовать Prometheus для обнаружения аномалий в GitLab | GitLab
Одной из основных функций языка запросов Prometheus является агрегирование данных временных рядов в реальном времени.Эндрю Ньюдигейт, выдающийся инженер группы инфраструктуры GitLab, предположил, что язык запросов Prometheus также можно использовать для обнаружения аномалий в данных временных рядов.
Эндрю рассказал о различных способах использования Prometheus для посетителей Monitorama 2019. В этом сообщении блога объясняется, как обнаружение аномалий работает с Prometheus, и включены фрагменты кода, которые вам понадобятся, чтобы опробовать его на своей собственной системе.
Почему полезно обнаружение аномалий?
Есть четыре основные причины, по которым обнаружение аномалий важно для GitLab:
- Диагностика инцидентов : мы можем быстро определить, какие службы работают за пределами своих нормальных границ, и сократить среднее время, необходимое для обнаружения инцидента (MTTD), что приведет к более быстрому разрешению.
- Обнаружение регресса производительности приложения : Например, если введена регрессия n + 1, которая приводит к тому, что одна служба вызывает другую с очень высокой скоростью, мы можем быстро отследить проблему и решить ее.
- Выявление и устранение злоупотреблений : GitLab предлагает бесплатные вычисления (GitLab CI / CD) и хостинг (GitLab Pages), и есть небольшая группа пользователей, которые могут этим воспользоваться.
- Безопасность : Обнаружение аномалий необходимо для выявления необычных тенденций в данных временных рядов GitLab.
По этим и многим другим причинам Эндрю исследовал возможность обнаружения аномалий в данных временных рядов GitLab, просто используя запросы и правила Prometheus.
Какой уровень агрегирования правильный?
Во-первых, данные временных рядов должны быть правильно агрегированы. Эндрю использовал стандартный счетчик http_requests_total в качестве источника данных для этой демонстрации, хотя многие другие показатели могут быть применены с использованием тех же методов.
http_requests_total {
job = "apiserver",
method = "ПОЛУЧИТЬ",
controller = "ProjectsController",
status_code = "200",
environment = "prod"
}
В этом примере метрики есть дополнительные измерения : метод , контроллер , код_статуса , среда , а также измерения, которые добавляет Prometheus, такие как экземпляр и задание .
Затем вы должны выбрать правильный уровень агрегирования для данных, которые вы используете.Это своего рода проблема Златовласки — слишком много, слишком мало или как раз то, что нужно, — но она необходима для поиска аномалий. Если слишком сильно агрегирует данные , это может быть уменьшено до слишком малого количества измерений, создавая две потенциальные проблемы:
- Вы можете пропустить подлинные аномалии, потому что агрегирование скрывает проблемы, возникающие в подмножествах ваших данных.
- Если вы все же обнаружите аномалию, трудно связать ее с определенной частью вашей системы без дополнительного исследования аномалии.
Но если агрегировать слишком мало данных , вы можете получить серию данных с очень маленькими размерами выборки, что может привести к ложным срабатываниям и может означать пометку подлинных данных как выбросы.
Совершенно верно: наш опыт показал, что правильный уровень агрегации — это уровень обслуживания , поэтому мы включаем метку задания и метку среды, но опускаем другие измерения. Агрегирование данных, используемое в остальной части выступления, включает: задание http-запросы , скорость пять минут, что в основном представляет собой скорость для задания и среды в пятиминутном окне.
- запись: job: http_requests: rate5m
выражение: сумма без (экземпляр, метод, контроллер, код_статуса)
(оценка (http_requests_total [5m]))
# -> job: http_requests: rate5m {job = "apiserver", environment = "prod"} 21321
# -> job: http_requests: rate5m {job = "gitserver", environment = "prod"} 2212
# -> job: http_requests: rate5m {job = "webserver", environment = "prod"} 53091
Использование z-показателя для обнаружения аномалий
Некоторые из основных принципов статистики могут быть применены для обнаружения аномалий с помощью Prometheus.
Если мы знаем среднее значение и стандартное отклонение (σ) ряда Прометея, мы можем использовать любую выборку в ряду для расчета z-показателя. Z-оценка измеряется в количестве стандартных отклонений от среднего. Таким образом, z-оценка, равная 0, будет означать, что z-оценка идентична среднему значению в наборе данных с нормальным распределением, в то время как z-оценка, равная 1, равна 1,0 σ от среднего и т. Д.
Если исходные данные имеют нормальное распределение, 99,7% выборок должны иметь z-оценку от нуля до трех.Чем дальше z-оценка от нуля, тем меньше вероятность ее существования. Мы применяем это свойство для обнаружения аномалий в серии Prometheus.
- Рассчитайте среднее значение и стандартное отклонение для показателя, используя данные с большим размером выборки. В этом примере мы используем данные за одну неделю. Если предположить, что мы оцениваем правило записи раз в минуту, в течение недели у нас будет чуть более 10 000 образцов.
# Долгосрочное среднее значение для серии
- запись: задание: http_requests: rate5m: avg_over_time_1w
выражение: avg_over_time (задание: http_requests: rate5m [1 нед])
# Долгосрочное стандартное отклонение для серии
- запись: задание: http_requests: rate5m: stddev_over_time_1w
выражение: stddev_over_time (задание: http_requests: rate5m [1 нед])
- Мы можем вычислить z-оценку для запроса Prometheus, если у нас есть среднее значение и стандартное отклонение для агрегирования.
# Z-Score для агрегирования
(
задание: http_requests: rate5m -
задание: http_requests: rate5m: avg_over_time_1w
) / задание: http_requests: rate5m: stddev_over_time_1w
Основываясь на статистических принципах нормального распределения, , мы можем предположить, что любое значение, выходящее за пределы диапазона примерно от +3 до -3, является аномалией . Мы можем построить оповещение на основе этого принципа. Например, мы можем получить предупреждение, когда наше агрегирование выходит за пределы этого диапазона более пяти минут.
GitLab.com Pages обслуживают запросы в секунду в течение 48 часов, область значений z ± 3, выделенная зеленым цветом
Z-score немного неудобно интерпретировать на графике, потому что у них нет единицы измерения. Но аномалии на этом графике легко обнаружить. Все, что появляется за пределами зеленой зоны (которая обозначает z-значения, попадающие в диапазон +3 или -3), является аномалией.
Что делать, если у вас нет нормального распределения?
Но подождите : мы делаем большой скачок, предполагая, что наша базовая агрегация имеет нормальное распределение.Если мы рассчитаем z-оценку с данными, которые не имеют нормального распределения, наши результаты будут неверными.
Существует множество статистических методов для проверки ваших данных на нормальное распределение, но лучший вариант — проверить, что ваши базовые данные имеют z-оценку примерно от +4 до -4 .
(
max_over_time (задание: http_requests: rate5m [1w]) - avg_over_time (job: http_requests: rate5m [1w])
) / stddev_over_time (задание: http_requests: rate5m [1 нед])
# -> {job = "apiserver", environment = "prod"} 4.01
# -> {job = "gitserver", environment = "prod"} 3.96.
# -> {job = "webserver", environment = "prod"} 2.96
(
min_over_time (задание: http_requests: rate5m [1w]) - avg_over_time (job: http_requests: rate5m [1w])
) / stddev_over_time (задание: http_requests: rate5m [1 нед])
# -> {job = "apiserver", environment = "prod"} -3,8
# -> {job = "gitserver", environment = "prod"} -4.1
# -> {job = "webserver", environment = "prod"} -3,2
Два запроса Prometheus, проверяющие минимальный и максимальный z-значения.
Если ваши результаты возвращаются с диапазоном от +20 до -20, хвост слишком длинный, и ваши результаты будут искажены.Помните также, что это нужно запускать для агрегированных, а не неагрегированных рядов. Метрики, которые, вероятно, не имеют нормального распределения, включают такие вещи, как частота ошибок, задержки, длина очереди и т. Д., Но многие из этих метрик в любом случае будут лучше работать с фиксированными пороговыми значениями для предупреждений.
Обнаружение аномалий по сезонности
Хотя вычисление z-оценок хорошо работает с нормальным распределением данных временных рядов, существует второй метод, который может дать еще более точные результаты обнаружения аномалий . Сезонность — это характеристика метрики временного ряда, в которой метрика испытывает регулярные и предсказуемые изменения, которые повторяются каждый цикл.
запросов Gitaly в секунду (RPS), понедельник-воскресенье, в течение четырех недель подряд
На этом графике показано количество запросов в секунду (запросов в секунду) для Gitaly за семь дней, с понедельника по воскресенье, за четыре недели подряд. Семидневный диапазон называется «смещением», что означает образец, который будет измеряться.
Каждая неделя на графике выделена другим цветом. На сезонность данных указывает последовательность тенденций, показанных на графике — каждый понедельник утром мы наблюдаем такой же рост ставок RPS, а вечером в пятницу мы видим, что ставки RPS снижаются, неделя за неделей.
Используя сезонность в данных наших временных рядов, мы можем создавать более точные прогнозы, что приведет к лучшему обнаружению аномалий.
Как мы используем сезонность?
Для расчета сезонности с помощью Prometheus мы использовали несколько различных статистических принципов.
На первой итерации мы вычисляем, добавляя тенденцию роста, которую мы наблюдали за однонедельный период, к значению на предыдущей неделе. Рассчитайте тенденцию роста, вычтя скользящее среднее значение за последнюю неделю из скользящего среднего значения за неделю на данный момент.
- запись: job: http_requests: rate5m_prediction
expr:>
job: http_requests: rate5m offset 1w # Значение за последний период
+ job: http_requests: rate5m: avg_over_time_1w # Тенденция роста за неделю
- job: http_requests: rate5m: avg_over_time_1w смещение 1w
Первая итерация немного узкая; мы используем пятиминутное окно на этой и предыдущей неделях, чтобы делать наши прогнозы.
Во второй итерации мы расширяем область действия, беря среднее значение четырехчасового периода за предыдущую неделю и сравнивая его с текущей неделей. Итак, если мы пытаемся предсказать значение показателя в 8:00 утра понедельника, вместо того, чтобы использовать то же пятиминутное окно за неделю до этого, мы используем среднее значение показателя с 6:00 до 10:00 для предыдущего утро.
- запись: job: http_requests: rate5m_prediction
expr:>
avg_over_time (job: http_requests: rate5m [4h] offset 166h) # Округленное значение за последний период
+ job: http_requests: rate5m: avg_over_time_1w # Добавить тенденцию роста на 1 неделю
- job: http_requests: rate5m: avg_over_time_1w смещение 1w
Мы используем в запросе 166 часов вместо одной недели, потому что мы хотим использовать четырехчасовой период, основанный на текущем времени суток, поэтому нам нужно, чтобы смещение было на два часа меньше полной недели.
Gitaly service RPS (желтый) против прогноза (синий), более двух недель.
Сравнение реального Gitaly RPS (желтый) с нашим прогнозом (синий) показывает, что наши расчеты были довольно точными. Однако у этого метода есть недостаток.
Использование GitLab было ниже, чем в обычную среду, потому что 1 мая был Международный день труда, праздник, отмечаемый во многих странах. Поскольку наши темпы роста зависят от использования на предыдущей неделе, наши прогнозы на следующую неделю, в среду, 8 мая, были для более низких запросов в секунду, чем это было бы, если бы среда, 1 мая, не была выходным днем.
Это можно исправить, сделав три прогноза на три недели подряд до среды, 1 мая; за предыдущую среду, среду перед этим и среду перед этим. Запрос остается прежним, но смещение корректируется.
- запись: job: http_requests: rate5m_prediction
expr:>
квантиль (0,5,
label_replace (
avg_over_time (задание: http_requests: rate5m [4h] смещение 166h)
+ job: http_requests: rate5m: avg_over_time_1w - job: http_requests: rate5m: avg_over_time_1w смещение 1w
, "смещение", "1w", "", "")
или же
label_replace (
avg_over_time (задание: http_requests: rate5m [4h] смещение 334h)
+ job: http_requests: rate5m: avg_over_time_1w - job: http_requests: rate5m: avg_over_time_1w смещение 2w
, "смещение", "2w", "", "")
или же
label_replace (
avg_over_time (задание: http_requests: rate5m [4h] смещение 502h)
+ job: http_requests: rate5m: avg_over_time_1w - job: http_requests: rate5m: avg_over_time_1w смещение 3w
, "смещение", "3w", "", "")
)
без (смещения)
Три прогноза для трех сред по сравнению с фактическим RPS Гитали, среда, 8 мая (одна неделя после Международного дня труда)
На графике мы построили среду, 8 мая, и три прогноза на три недели подряд до 8 мая.Мы видим, что два прогноза верны, но прогноз на 1 мая все еще далек от основания.
Кроме того, нам не нужны три предсказания, нам нужно , одно предсказание . Взятие среднего значения не вариант, потому что оно будет разбавлено нашими искаженными данными о количестве запросов в секунду на 1 мая. Вместо этого мы хотим вычислить медиану. У Prometheus нет медианного запроса, но мы можем использовать квантильное агрегирование вместо медианы.
Единственная проблема с этим подходом заключается в том, что мы пытаемся включить три серии в агрегирование, и эти три серии на самом деле являются одними и теми же сериями в течение трех недель.Другими словами, все они имеют одинаковые ярлыки, поэтому связать их сложно. Чтобы избежать путаницы, мы создаем метку с именем смещение и используем функцию замены метки, чтобы добавить смещение к каждой из трех недель. Затем, в агрегировании квантилей, мы убираем это, и это дает нам среднее значение из трех.
- запись: job: http_requests: rate5m_prediction
expr:>
квантиль (0,5,
label_replace (
avg_over_time (задание: http_requests: rate5m [4h] смещение 166h)
+ job: http_requests: rate5m: avg_over_time_1w - job: http_requests: rate5m: avg_over_time_1w смещение 1w
, "смещение", "1w", "", "")
или же
label_replace (
avg_over_time (задание: http_requests: rate5m [4h] смещение 334h)
+ job: http_requests: rate5m: avg_over_time_1w - job: http_requests: rate5m: avg_over_time_1w смещение 2w
, "смещение", "2w", "", "")
или же
label_replace (
avg_over_time (задание: http_requests: rate5m [4h] смещение 502h)
+ job: http_requests: rate5m: avg_over_time_1w - job: http_requests: rate5m: avg_over_time_1w смещение 3w
, "смещение", "3w", "", "")
)
без (смещения)
Теперь наш прогноз, основанный на среднем значении из серии трех агрегатов, намного точнее.
Медиана прогнозов по сравнению с фактическими показателями Gitaly RPS, среда, 8 мая (одна неделя после Международного дня труда)
Как мы узнаем, что наш прогноз действительно точен?
Чтобы проверить точность нашего прогноза, мы можем вернуться к z-баллу. Мы можем использовать z-оценку, чтобы измерить расстояние между выборкой и ее предсказанием в стандартных отклонениях. Чем больше стандартных отклонений от нашего прогноза, тем больше вероятность того, что конкретное значение будет выбросом.
Прогнозируемый нормальный диапазон ± 1,5σ для Gitaly Service
Мы можем обновить нашу диаграмму Grafana, чтобы использовать сезонный прогноз, а не еженедельное скользящее среднее значение. Диапазон нормальности для определенного времени суток заштрихован зеленым. Все, что выходит за пределы затененной зеленой зоны, считается выбросом. В этом случае выброс произошел в воскресенье днем, когда наш облачный провайдер столкнулся с некоторыми проблемами сети.
Использование границ ± 2σ по обе стороны от нашего прогноза — довольно хорошее измерение для определения выброса с сезонными прогнозами.
Как настроить оповещение с помощью Prometheus
Если вы хотите настроить оповещения для аномальных событий, вы можете применить к Prometheus довольно простое правило, которое проверяет, находится ли z-оценка метрики между стандартным отклонением +2 или -2 .
- предупреждение: RequestRateOutsideNormalRange
expr:>
абс (
(
задание: http_requests: rate5m - задание: http_requests: rate5m_prediction
) / задание: http_requests: rate5m: stddev_over_time_1w
)> 2
для: 10м
ярлыки:
серьезность: предупреждение
аннотации:
резюме: Запросы на вакансию {{$ label.job}} находятся за пределами ожидаемых рабочих параметров
В GitLab мы используем настраиваемое правило маршрутизации, которое проверяет Slack при обнаружении каких-либо аномалий, но не оповещает сотрудников службы поддержки по вызову.
На вынос
- Prometheus может использоваться для некоторых типов обнаружения аномалий
- Правильный уровень агрегирования данных — ключ к обнаружению аномалий
- Z-скоринг — эффективный метод, если ваши данные имеют нормальное распределение
- Сезонные метрики могут дать отличные результаты для обнаружения аномалий
Посмотреть полную презентацию Эндрю из Monitorama 2019.Если у вас есть вопросы к Эндрю, свяжитесь с ним в Slack по адресу # talk-andrew-newdigate. Вы также можете узнать больше о том, зачем вам Прометей.
«. @ Su Suprememoocow показывает, как язык запросов @PrometheusIO можно использовать для обнаружения аномалий в @gitlab» — Сара Кассабиан
Нажмите, чтобы твитнуть
целевых квантилей в Prometheus | Александр Топличану
Алгоритм, лежащий в основе сводок Прометея.
Аннотация
Prometheus использует метод, называемый целевыми квантилями, для реализации типа метрики «Сводка», который используется для мониторинга распределений, например задержек.Здесь мы даем обзор того, как работает алгоритм, мы отвечаем, почему он так эффективен и как настраивать сводки.
Введение
Очень важный способ понять, как ваша распределенная система работает в производственной среде, — это отслеживать ее. В последние годы Prometheus стал самой популярной системой мониторинга приложений, развернутых в Kubernetes.
Помимо более распространенных счетчиков и датчиков, клиент Prometheus предоставляет тип метрики «Сводка». В проекте Go это может выглядеть так:
// Это определение метрики, которая отслеживает задержку RPC.задержка: = prometheus.NewSummary (prometheus.SummaryOpts {
Название: "rpc_durations_seconds",
Справка: «Распределение задержки RPC.»,
Цели: map [float64] float64 {0,5: 0,05, 0,9: 0,01, 0,99: 0,001},
})
// Вот как вы бы использовали его где-нибудь в своем коде.
reqDuration: = rand.Float64 ()
задержка.Observe (reqDuration)
Этот код был извлечен из примера prometheus / client-golang
В приведенном выше случае Сводка даст нам 99-й, 90-й и 50-й процентили для задержки этого конкретного запроса RPC.
Вот как это будет выглядеть в Graphana, популярном графическом интерфейсе для Prometheus:
Prometheus использует структуру данных, называемую целевыми квантилями, для очень эффективного вычисления итогов. В этом посте я опишу, как они реализованы и почему они так эффективны.
Квантили и процентили
Этот раздел представляет собой небольшой обходной путь для описания того, что такое квантили и процентили.
Квантиль q в наборе данных размера n — это элемент с рангом math.Ceil (q * n) , где 0 <= q <= 1 .
Ранг элемента - это его индекс в отсортированном наборе данных.
Например, пусть a будет списком из 20 целых чисел от 1 до 20, а также дубликатов:
a: = [] int {11, 9, 13, 19, 13, 13, 5, 12, 7, 16, 6, 15, 17, 1, 19, 5, 11, 10, 18, 2}
Давайте отсортируем a в переменную с именем b :
b: = [] int {1, 2, 5, 5, 6, 7, 9, 10, 11, 11, 12, 13, 13, 13, 15, 16, 17, 18, 19, 19}
0.9 квантиль набора данных a размера 20 - это элемент с индексом 0,9 * 20 == 18 из отсортированной версии b , то есть 18!
Процентили - это то же понятие, что и квантили, за исключением того, что процентили выражаются в процентах.
Таким образом, процентиль p набора данных размера n - это элемент с рангом math.Ceil (p * n / 100) , где 0 <= p <= 100 .
В приведенном выше примере 99-й процентиль - это элемент с индексом math.Ceil (99 * 20/100) == 20 в b , в результате получается значение 19 .
Подход
В предыдущем разделе мы вычислили квантиль 0,9 для массива из 20 чисел. У нас было преимущество небольшого набора данных. Помните, что квантиль определяется как функция всех значений во входном наборе данных. Отслеживание задержек запросов в архитектуре с сотнями микросервисов составляет очень большой объем наблюдений даже для узкого скользящего временного окна.
Распределения наблюдений за задержкой обычно имеют длинные хвосты, которые представляют большой интерес: мы хотим знать, каковы наихудшие задержки в работе наших сервисов. Выборка - это популярный метод уменьшения размеров набора данных, но он имеет высокую вероятность пропустить выбросы, поэтому в данном случае это не вариант!
Что необходимо, так это потоковый подход с пространственной сложностью , значительно сублинейной по отношению к размеру ввода.
Некоторые исходные условия необходимо смягчить: интересующие квантили и допустимые ошибки для каждого из них должны быть определены априори,
система не сможет произвести никакой другой квантиль.На практике это ограничение незначительно, а преимущества существенны: сложность пространства линейна с количеством целевых квантилей, а не с размером набора данных.
Поле Objectives сводки Prometheus содержит целевые квантили в качестве ключей и допустимые ошибки в качестве значений:
карта [float64] float64 {0,5: 0,05, 0,9: 0,01, 0,99: 0,001},
Обратите внимание, , что ошибка применяется не к возвращаемому значению, а к полученному рангу.Помните, что квантиль соответствует рангу в отсортированной версии входного набора данных, который, в свою очередь, соответствует значению из исходного набора данных. В приведенном выше примере алгоритм будет создавать квантили в диапазонах:
-
[0,45, 0,55]для цели0,5 -
[0,89, 0,91]для цели0,9 -
[0,989, 0,991]для цели0,99.
Важно, чтобы алгоритм вырабатывал значения из исходного набора данных, а не агрегированные значения (например, среднее или максимальное значение) по определению квантиля.Хотя агрегаты полезны, более высокие абстракции над квантилями могут использовать свойство, согласно которому значения действительно наблюдались.
Интуиция
Чтобы получить представление о том, как работает алгоритм, рассмотрим следующий график:
Он показывает три гауссовские функции плотности вероятности, по одной для каждого из трех квантилей:
- 0,5 квантиля »синий с медианой 50 и дисперсией 10
- 0,9 квантиль »красный со средним значением 90 и дисперсией 5
- 0.Квантиль 99 »желтый со средним значением 99 и дисперсией 3
На Ox есть числа от 1 до 100, полученные алгоритмом в случайном порядке. Каждая точка на любой из колоколообразных кривых представляет вероятность того, что значение Ox будет возвращено алгоритмом при запросе целевого квантиля.
Поскольку значения квантилей будут смещаться по мере потребления большего количества данных, алгоритм должен сохранять соседние значения, чтобы убедиться, что он покрывает ограничение ошибки. Следовательно, чем ниже допустимая ошибка для квантиля, тем больше данных должен хранить алгоритм.
Например, 0,5-й квантиль с ошибкой 0,05 приемлем, потому что большинство значений около среднего будут очень похожими, поэтому нет смысла хранить их больше. Однако для 0,99-го квантиля ошибка должна быть намного меньше, чтобы улавливать выбросы. С другой стороны, хвостовые значения гораздо реже, поэтому алгоритм будет хранить намного меньше данных.
Алгоритм
Абстрактная структура данных, используемая алгоритмом, представляет собой отсортированный список со следующими операциями:
-
Insert (float64)вычисляет самый низкий и самый высокий ранг для нового значения, затем вставляет его в список, сохраняя список отсортированным.Каждое значение в списке охватывает диапазон рангов, ограниченный настроенными ошибками. -
Запрос (float64) float64просматривает список, чтобы найти значение, диапазон охваченных рангов которого включает ранг, соответствующий запрошенному квантилю. Затем он возвращает это значение. -
Compress ()просматривает список и удаляет все избыточные значения: по мере добавления дополнительных значений интервалы ранжирования для целевых квантили сдвигаются и начинают перекрываться. Сжатие находит эти перекрывающиеся значения и удаляет их.
Реализация Prometheus использует небольшой фрагмент (500 выборок) в качестве конкретной структуры данных и запускает Compress сразу после каждой вставки.
В следующей таблице показан алгоритм в работе с набором данных из 30 выборок: перемешанные целые числа от 1 до 30 включительно.
Вы можете найти скрипт, сгенерировавший эту таблицу, в этом коммите.
Чтобы заставить его работать, размер внутреннего списка, используемого в реализации, был уменьшен с 500 до 10, чтобы заставить Compress сократить данные.
Обратите внимание на то, как при вводе значений удаляются другие значения, возможно, из других областей квантильного спектра, например на Вставка 24 , 2 снимается.
Часто новое введенное значение не добавляет никакой новой информации, поэтому оно игнорируется, например на Вставка 7 , Вставка 1 и т. д.
Наблюдения
Алгоритм не производит выборку, то есть учитывает все входные значения, но отсекает те, которые не имеют отношения к объективным квантилям.
Сложность пространства пропорциональна количеству интересующих квантилей, а не размеру ввода!
Чтобы структура данных оставалась небольшой, необходимо часто выполнять Compress для удаления ненужных значений.
Чтобы получить наилучшую временную сложность, можно использовать красно-черное дерево для быстрого поиска и удаления.
Два отдельных экземпляра целевой структуры данных квантиля с одинаковыми целевыми значениями могут быть объединены простым
вставка значений из одного в другой и запуск Compress .
Запоздалые мысли
Интересные решения используются в средах с ограниченными ресурсами. Для выполнения любой полезной работы необходимо идти на компромиссы и принимать уровни ошибок. Существует обширная категория алгоритмов, подходящих для таких ситуаций, и они оказываются полезными вне своего исходного контекста. Целевые квантили изначально были разработаны для сетевого оборудования, но мы постоянно используем их для мониторинга наших развертываний Kubernetes. Я призываю вас попытаться понять, как устроены часто используемые вами инструменты.
Список литературы
- Исходный документ, цитируемый в реализации Prometheus, - это эффективное вычисление смещенных квантилей по потокам данных Кормода и др. Он описывает общий алгоритм, называемый предвзятыми квантилями. В качестве специализации он вводит квантили с высоким, низким и целевым значениями. Он содержит математическое доказательство правильности и анализ рабочих характеристик.
- Более новая статья той же исследовательской группы: Эффективные по пространству и времени детерминированные алгоритмы для смещенных квантилей по потокам данных.Это представляет собой еще более обобщенный алгоритм, который распространяется на ответы на запросы ранжирования, а также на предвзятые и целевые квантили.
- В глобальном клиенте Prometheus используется реализация github.com/beorn7/perks/quantile
- Документация Прометея для квантильной оценки.
Сообщите мне, что вы думаете о Lobsters, Hacker News или Twitter.
Примирение с Прометеем ставка () | by Zaar Hai
Долгий путь к тому, чтобы сделать rate (), чтобы пройти свое выступление
Недавно я провел серию докладов из двух частей о системе мониторинга Prometheus.В последней главе второго выступления я затронул довольно запутанную тему, где вы можете спрятать свои метрические изменения под ковер. Этот блог является продолжением вышеупомянутой серии бесед, в котором подробно рассказывается о том, что может выглядеть как противоречие.
Внутренности пещеры Кумистави, известной как пещера ПрометеяПо возможности инициализируйте свои счетчики с 0, чтобы метрика сразу же начала сообщаться, опять же, с 0 в качестве значения. Вот почему:
Со счетчиками нас интересуют только измененийВыше у нас есть метрика, которая не была инициализирована нулем.Теперь, когда первая ошибка приводит к появлению «1», Прометей (с этого момента для краткости будем называть его просто «P8s») с радостью сохранит его. Но с его точки зрения в метрике изменений не произошло. Следовательно, если у вас есть предупреждение, отслеживающее изменения на этом счетчике, оно наверняка пропустит первую ошибку, и кто-то с пейджером может вскоре получить очень грустный смайлик.
Сказанное выше может удивить новичка в P8s, но его легко понять. И на самом деле это единственная проблема, описанная в этом посте, которую я оставил бы разработчику приложения для решения.
Давайте перейдем к более тонким тонкостям.
У меня часто был медленно увеличивающийся счетчик, возможно, счетчик ошибок, где при выполнении rate () возвращались все нули, несмотря на то, что мой диапазон был установлен книгой. Что ж, может быть, мой счетчик действительно не увеличивается, я подумал про себя как успокаивающее упражнение, но это не тот случай: счетчик
My Grafana «Min step» (и, следовательно, $ __ interval ) была ограничена одной минутой, а интервал очистки 15 секунд - это как раз рекомендуемое окно ретроспективного анализа для функции rate () .Так что здесь не так?
Чтобы понять, что нам нужно вернуться к классной доске:
Видите ли, в зависимости от того, как выстраиваются звезды, если наши 1-минутные сегменты диапазона попадают только на границы изменения метрики, в этом сегменте нет никаких изменений в метрике. и именно поэтому rate () вместе со своей сестрой Увеличить () возвращает нули.
Почему он воспроизводится так часто и так последовательно? Два фактора:
- Если в вашем коде есть что-то, что сообщает об изменении в течение целой минуты (подумайте о cronjobs), то, скорее всего, изменение будет отнесено к целой минуте границы при парсинге.
- По состоянию на два года назад Grafana обеспечивает (и это справедливо) выравнивает начало диапазона диаграммы так, чтобы оно было кратным шагу , следовательно, если ваш шаг в Grafana составляет одну минуту, границы сегмента всегда будут совпадать граница целой минуты, например [[18:06:00, 18:07:00], [18:07:00, 18:08:00],…].
В совокупности все вышеперечисленное создает идеальный шторм (или, скорее, идеальный штиль?), При котором ставки становятся равными нулю для счетчиков, которые меняют свое значение на целой минутной границе.
Но не верьте мне на слово - давайте изменим шаг с 1 минуты на 15 секунд и посмотрим, что произойдет (в основном вычисляем rate () при каждом цикле за последние 4 выборки).
Ага! Здесь мы можем наблюдать две интересные вещи:
- На самом деле рисунок на классной доске соответствует действительности - наша метрика изменяется в 13:14:15, но
увеличение ()в 13:15:00 равно нулю, поскольку мы снова получили «идеально» Здесь выравнивание ковша, где все изменения приходятся на границы. - в 13:14:15
Увеличить ()сообщает об изменении, но ... оно больше, чем фактическое! А именно 1,33 вместо 1,0.
Почему? Снова вернемся к доске:
Экстраполяция Прометея в действииВидите ли, у нас есть четыре точки данных в каждом сегменте, но нам нужна дельта во времени, помните, и по времени наши четыре точки данных покрывают только 45 секунд вместо 60! - 15 секунд за [t₃, t₄], еще 15 секунд за [t₄, t₅] и последние 15 секунд за [t₅, t₆]. Следующим сегментом будет [t₇, t₈], [t₈, t₉] и [t₉, t₁₀], , но ни один сегмент не будет содержать интервал [t₆, t₇]! И это потому, что Prometheus применяет один и тот же алгоритм сегментирования как для вычислений первого порядка (например,грамм. средние по датчикам) и вычисления второго порядка (например, ставки по счетчикам).
Таким образом, в основном Prometheus понимает, что фактический диапазон в каждом сегменте на один цикл меньше, то есть 45 секунд вместо 60 в нашем случае, поэтому, когда он видит, что метрика изменяется на 1 в сегменте, это фактически «на 1 за 45 секунд», не «на 1 за 60 секунд», поэтому он экстраполирует результат как 1/45 * 60 = 1,33 , и именно так мы получаем, что значения Увеличить () больше фактического изменения.
На этом этапе, если вы все еще не уверены, что Прометей хорош для мониторинга, но не подходит для точных данных, таких как биллинг, я бы предпочел не заниматься с вами банковскими операциями 🙂 включить лишнюю царапину, которая попадает между ведрами c̶h̶a̶i̶r̶s̶…
Как мы можем это исправить, если вообще?
Для начала, мы можем контролировать наш диапазон и шагать сами:
Заполнение промежуткаЧтобы получить увеличение за 60 секунд, мы просим P8s вычислить единицу за 75 секунд (с той дополнительной выборкой, которая обычно падает между бакетами).Конечно, Prometheus экстраполирует это значение до 75 секунд, но мы вручную деэкстраполируем его до 60, и теперь наши диаграммы точны и предоставляют данные с интервалом в одну минуту.
Обратной стороной, конечно, является то, что мы не можем использовать автоматический шаг Grafana и механизмы $ __ interval . Но, по крайней мере, в Grafana есть определения предупреждений, где интервалы в любом случае рассчитываются вручную.
Что дальше?
К сожалению, пока ничего официального.В Grafana продолжается работа по внедрению $ __ rate_interval . Использование этой переменной вместо простого $ __ interval действительно будет включать эту дополнительную очистку после шага , чтобы убедиться, что мы действительно получаем данные, например, о точках за целые минуты, как в нашей демонстрации. Тем не менее, он все равно оставит интерполяцию нетронутой:
В последнее время эта проблема набирает обороты, поэтому, надеюсь, она будет доступна в следующем выпуске Grafana, чтобы убрать нулевые значения rate () .
Если мы хотим исправить «коррекцию» экстраполяции, я знаю два варианта.
xrate
Это форк Prometheus, который добавляет функции x rate () , x Увеличить () и т. Д., Которые обе добавляют дополнительную очистку (аналогично $ __ rate_interval ) но также будет применена деэкстраполяция, как мы это делали в примере предыдущей главы:
Здесь вы можете видеть, что я запускаю эту разветвленную версию P8s и использую стандартный интервал $ __ и зажим «Мин. Шаг»; и все просто работает - нулей нет и вычисления верны.
Хотя это форк, он внимательно следует за официальными релизами Prometheus, и
Алин Синпалеан (сопровождающий) поддерживает его на плаву последние пару лет. Я не использовал его в продакшене, но обязательно попробую его в следующем проекте.
Это проект удаленного хранилища * для Prometheus, который, в свою очередь, реализует «фиксированную» версию функций скорости, которые позволяют одновременно обрабатывать дополнительные данные и не использовать интерполяцию.
* Т.е. вы настраиваете потенциально несколько экземпляров Prometheus для отправки данных в VictoriaMetrics, а затем запускаете свой PromQL для последнего.
Опять же, я использую Grafana как обычно, и все просто работает:
VictoriaMetrics в действииЯ надеюсь, что этот пост поможет вам разобраться в ваших диаграммах Grafana и примириться с тем, как здесь все работает. Лично я бы серьезно пошел на форк xrate и VictoriaMetrics в следующий раз, когда я разверну систему мониторинга.
Если вас интересуют подробности того, почему вообще существует эта проблема, вот довольно длинные дискуссии на эту тему:
- Отличный блог, в котором объясняются такие проблемы и их развитие: ссылка
- Мой оригинал «Что за… ? » сообщение в группе пользователей P8s: ссылка
- скорость () / увеличение () экстраполяция считается вредной: ссылка
- Предложение по улучшению скорости / увеличения: ссылка
В заключение позвольте мне добавить, что эта проблема разделяет людей на лагеря «P8» основные разработчики против остальных »; и хотя у разработчиков P8 могут быть свои причины сказать, что они правы в этом вопросе, проблема действительно возникает в реальной жизни и довольно часто.